
Яндекс-переводчик. Новое.
Интервью Елизаветы Ивтушок с Дэвидом Талбот.
Руководитель Яндекс.Переводчика Дэвид Талбот — о новой гибридной системе перевода.
Четырнадцатого сентября компания «Яндекс» запустила новую версию своего переводчика. Главным нововведением является внедрение гибридной системы, которая умеет выбирать между нейронным машинным переводом и статистической моделью. Об особенностях и перспективах нового Яндекс.Переводчика, а также о том, сможет ли машинный перевод вытеснить живых переводчиков, мы побеседовали с британским компьютерным лингвистом и разработчиком Дэвидом Талботом — новым руководителем сервиса

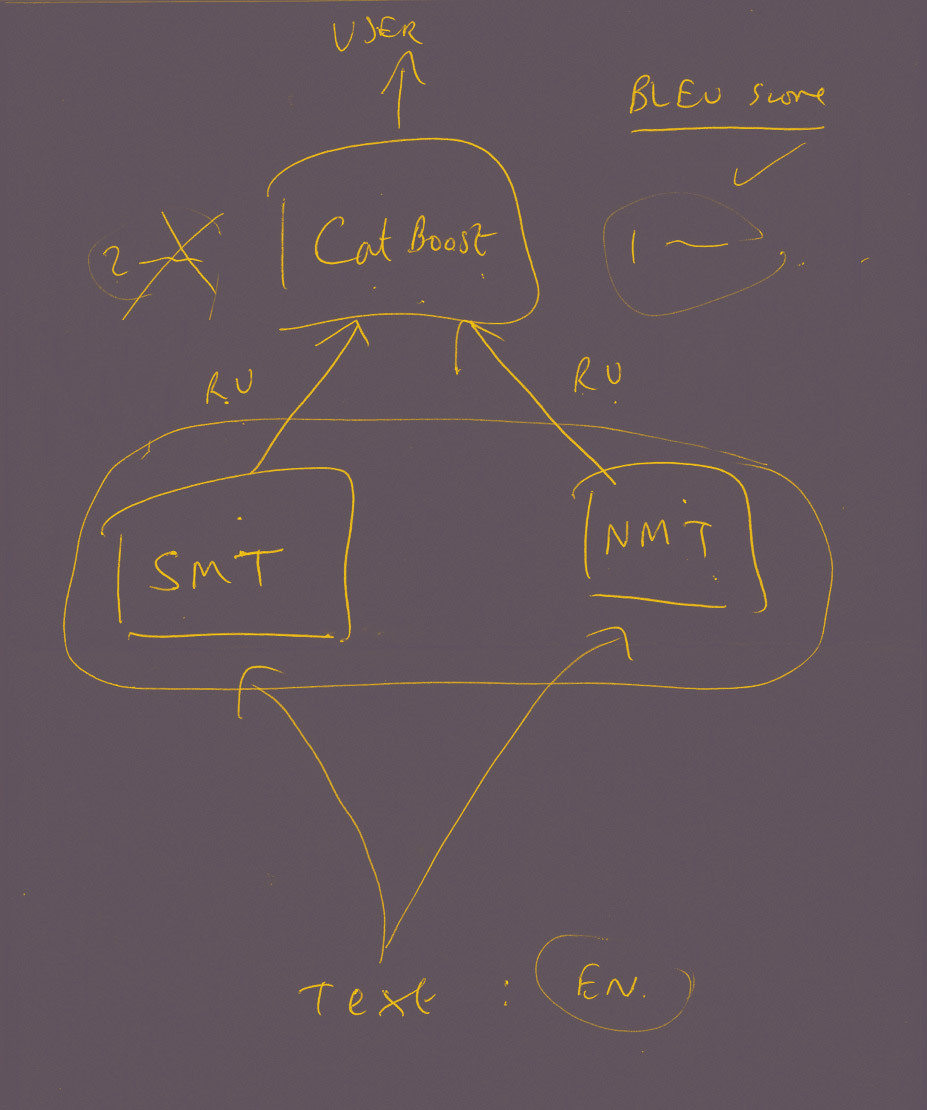
Вот как это работает. Предположим, у нас есть на входе какое-то предложение и мы переводим его с помощью обеих моделей. Если бóльшая часть слов из одного варианта перевода соответствует словам, которые были в обучающей выборке, то классификатор выбирает именно этот вариант и запоминает особенности, сделавшие этот перевод хорошим.
И наоборот, классификатор отбрасывает вариант, если он плохой. Например, частая проблема нейронного перевода — это повтор слов. Если в переведенном предложении повторяются слова, значит, такой перевод нам не подходит — и классификатор делает выбор в пользу статистической модели.

Довольно интересное интервью.
Касательно последней таблички перевода текста - не кажется ли Вам, что это весьма литературный, или ,если хотите, фривольный перевод, который будет мешать в некоторых частных случаях.
Я не такой большой специалист в данном вопросе, но все же...
https://nplus1.ru/material/2017/09/14/yandex-machine-transla...