

Из недавнего
Виртуалка, диски на СХД. Основная файлопомойка центрального офиса. Там же - рабочие столы и "Мои документы" всех пользователей.
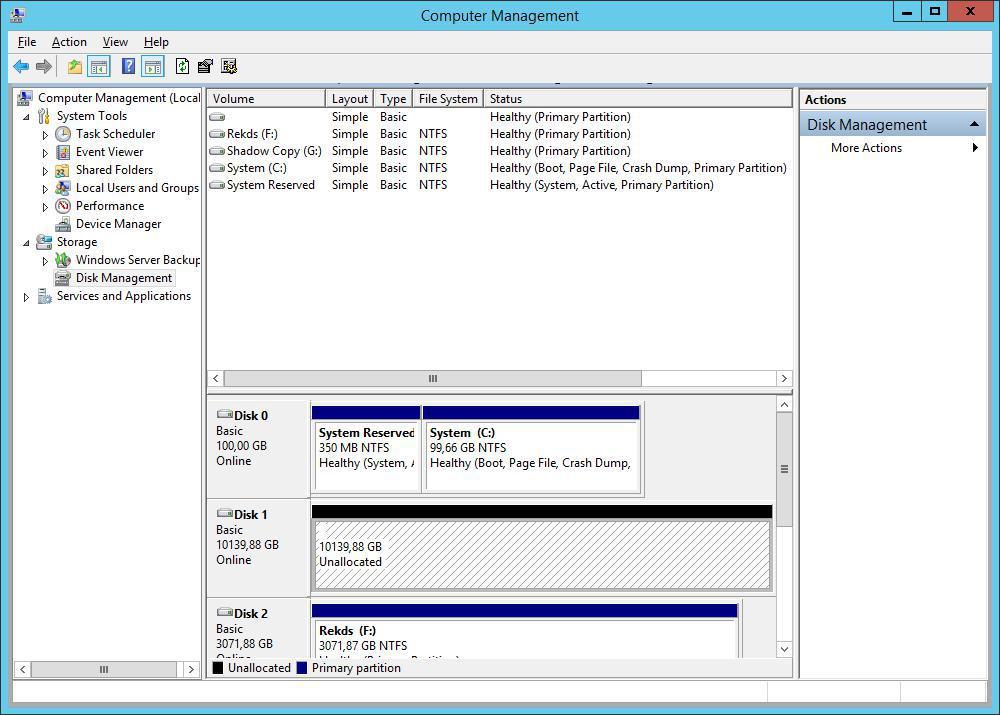
Слава б-гу, слетела только разметка разделов, данные все на месте. Что бы я делал с 10-терабайтным VMDK файлом - ума не приложу.
Поменьше работы вам в праздники, коллеги.


Лига Сисадминов
2.3K постов18.8K подписчиков
Правила сообщества
Мы здесь рады любым постам связанным с рабочими буднями специалистов нашей сферы деятельности.