
DA, подбор архитектуры. Отличить кота от собаки.
Сейчас расскажу, как примерно работает нейросеть, различающая котов от собак. Итак... датасет:
Посмотрели на котиков и собачек? А как же вы отделили одних от других?
Этой задачей в свою время задумались ученые, коим было интересно, как человек ищет на картинке признаки одного или другого зверька. Им нужно было придумать какой-то фильтр, а то и несколько, которые будут искать какие-то признаки картинки. Так был изобретен сверточный слой. Как это работает?
Наша задача: найти какие-нибудь признаки на картинке и сформировать матрицу признаков. Объясняю на примере, допустим, ищем какие-нибудь палочки (границы):

Так сверточный слой нашел границы предметов. Другой фильтр может отвечать за какие-нибудь кругляшки и так далее.
Если сделать несколько таких слоев, то в конце последнего сверточного слоя мы будем иметь информацию, допустим: глаза, шляпа, волосы и т. д., то есть довольно высокоуровневые данные. В случае собак и кошек мы найдем отличие, допустим, в ушах. Далее мы ставим обычный полносвязный слой (то, о чем говорил в прошлых постах) - и получаем такую задачу: уши большие, глаза черные - определить собака или кот. То есть свели задачу к предыдущей.
Обычно фильтры сильно меньше картинок, например для картинок 100х100 используются фильтры 3х3, опять же, для поиска каких-нибудь палочек и кружочков. Следующий уровень, например, может отвечать за поиск квадратов, треугольников. Потом - за какие-то крупные части изображения и так далее.
Итак, какой может быть подходящая архитектура? Ну, хотя бы такая:
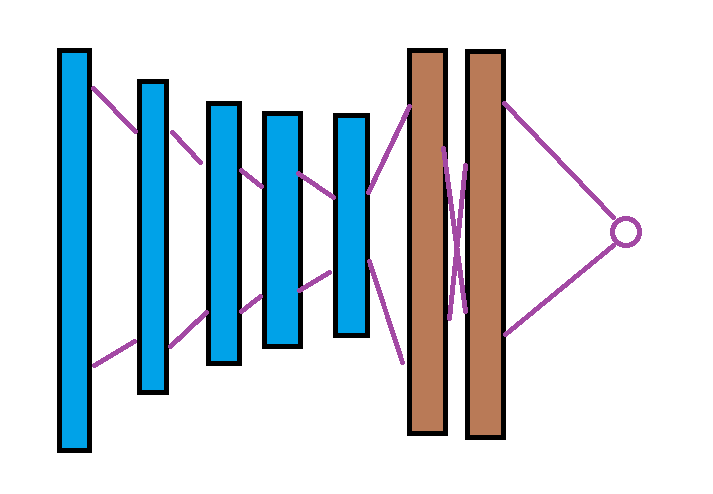
(Картинки размером от 50х50 до 100х100). Первые 5 - сверточные слои с фильтром 3х3. Пройдя первые 5 слоев сформируется матрица высокоуровневых признаков (например, уши, глаза...). Далее, с помощью двух обычных (полносвязных, линейных) слоев классифицируется изображение.
Как вообще подбирать архитектуру? На самом деле, ответа нет. То, что я привел - придумал из головы. Я делал модель, определяющую цифру из вебкамеры. Конкретно про собак я решал совсем иным способом: я взял существующую обученную нейросеть (VGG) и с помощью нее классифицировал. Для разного рода задач обычно есть стандарты, но существующие сетки и архитектуры улучшаются и совершенствуются...
Дальше могу рассказать про:
1) Сетки, которые понимают текст.
2) Про среду разработки, в которой мы работаем (она в браузере, серьезно)
3) Про что-нибудь еще.
4) Все, насобирал подписчиков, ни про что ни рассказывать.
Выбирайте :)