

Нестандартное использование поиска по картинкам для распознавания текста
Так получилось, что под конец года приходится очень часто работать с электронными копиями документов. Хорошо, если его присылают в редактируемом формате, но к сожалению, это далеко не всегда так. Чаще всего это сканированная копия документа, а то и вовсе фото на смартфон.
Поделюсь сегодня как я использую сервис поиска по изображениям, предоставляемый Яндексом для оперативного распознания текста. Это очень удобно, быстро, бесплатно, всегда под рукой и самое главное качество распознавания на уровне хороших OCR систем. Так что студентам, офисным работникам мне кажется будет крайне полезно.
ВАЖНО! Я не знаю технических тонкостей работы сервиса и его особенностей хранения данных, поэтому не загружайте и не распознавайте документы, содержащие информацию ограниченного доступа - коммерческую тайну, персональные данные и прочее! Помните - все что однажды попало в интернет, остается там навсегда!
Итак, у меня есть два документа с просторов Интернета в формате jpg (фотография договора, сделанная судя по всему на смартфон) и в формате pdf (качественный текст). Процесс распознавания текста в обоих случаях будет идентичный. Но для pdf документа нам понадобится дополнительно его разобрать на картинки.

Заходим на сайт https://ya.ru/ и в поисковой строке жмем пиктограмму с изображением фотоаппарата.
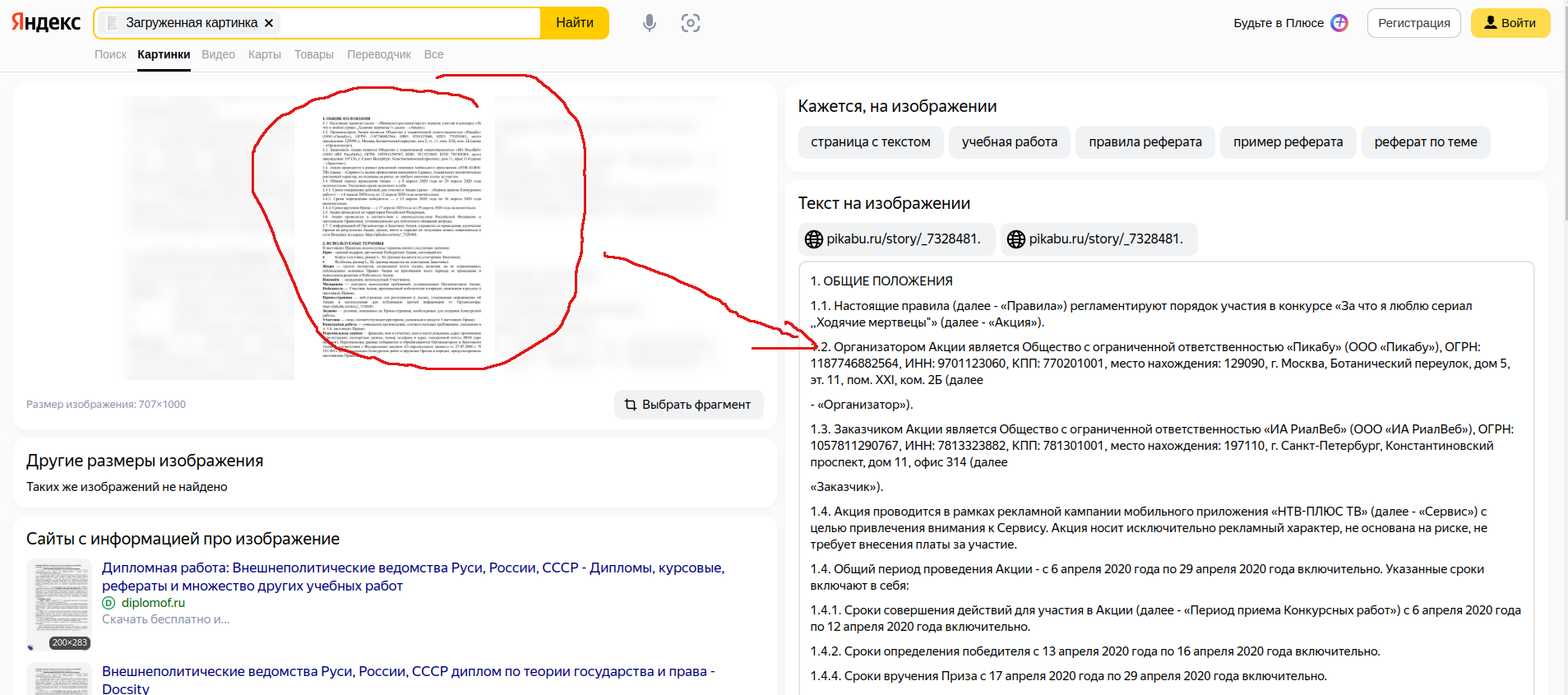
С помощью открывшегося проводника выбираем изображение на котором есть текст, который требуется распознать. Подтверждаем открытие картинки. Получаем результат.

Имеем:
- поисковая строка с загруженным изображением
- предпросмотр самого изображения
- результаты поиска с сайтами где встречается похожее изображение
- справа поисковые хэштеги и самое главное поле с текстом на изображении.
Поздравляю страница распознана, текст можно скопировать в редактор и работать с ним дальше.
Дополнительные операции с документом в формате pdf
Загрузить документ целиком не получится. Нам надо взять pdf документ и разобрать его по отдельным страничкам. Тут вариантов множество:
- программы-конвертеры для вашей операционки
- графическим редакторы (например бесплатный GIMP)
- онлайн-сервисы (их множество, выбирайте на свой вкус и цвет).
Я покажу как разобрать документ с помощью онлайн-сервиса https://pdftoimage.com/ru/ , но повторюсь еще раз вы можете выбрать любой другой, наверняка шаги будут точно такие же.
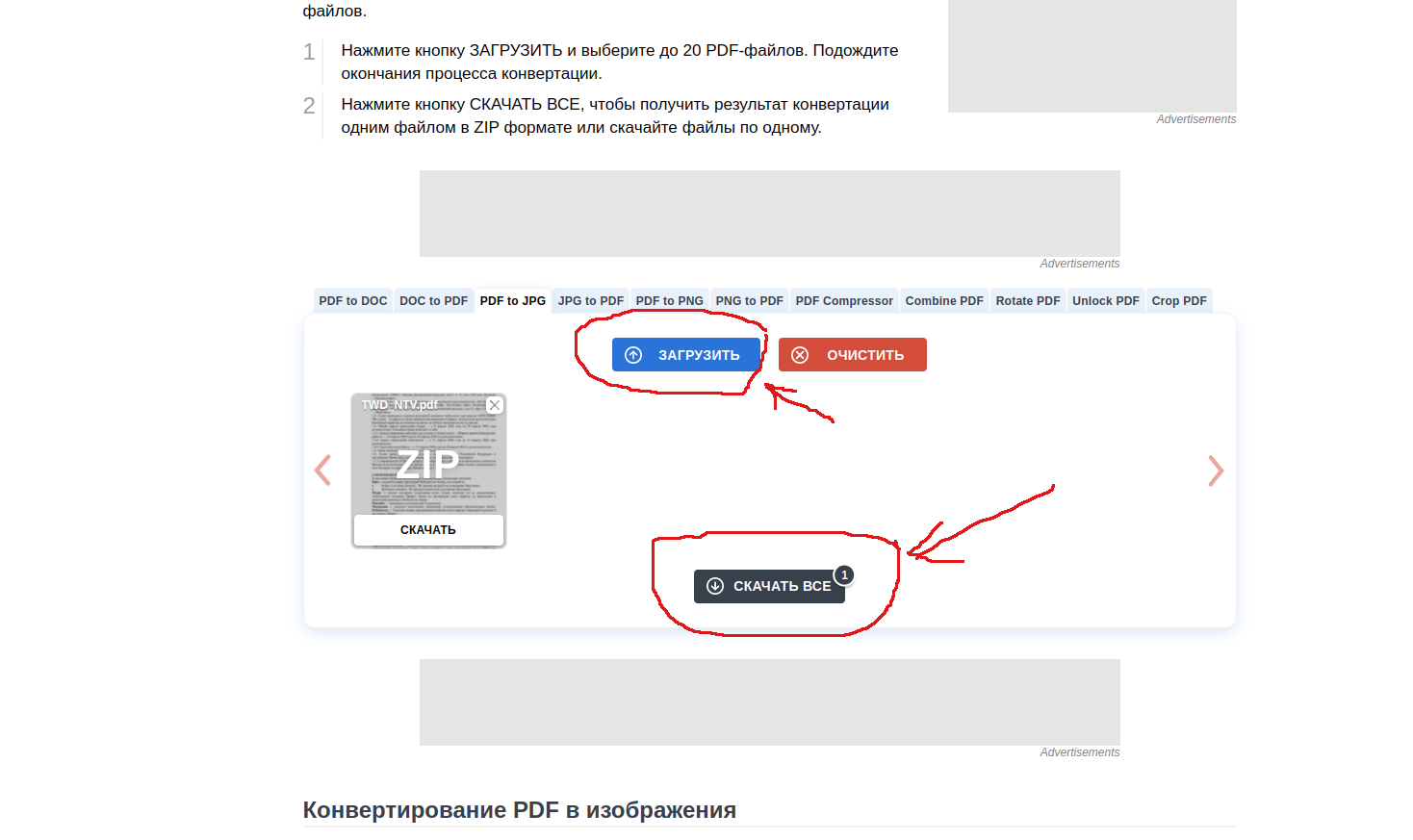
Переходим в сервис и жмем кнопку "загрузить".
В проводнике выбираем необходимый pdf документ.
После загрузки файла, сервис автоматически начинает работу с ним.
После завершения разбиения файла, становится доступна кнопка "скачать все".
Жмем её, и скачиваем себе zip архив. Распаковываем его и находим в папке наш исходный pdf документ, который разделен на отдельные jpg картинки - одна страница = одна картинка.
Ну вот и все - возвращаемся на шаг распознавания текста и подгружаем по отдельности каждую страницу с текстом и распознаем.
Само собой качество распознавания в обоих вариантах будет очень сильно зависеть от качества исходного изображения, но в любом случае это очень удобно, так как не требует установки какого-либо стороннего программного обеспечения, бесплатно и быстро.
Всем спокойной работы и никаких дедлайнов!
Программы и Браузеры
756 постов5.4K подписчиков
Правила сообщества
-Ставьте наши теги, если Ваш пост о программе, приложении или браузере(в том числе о расширениях, дополнениях в нему), его недоработке, баге, обновлении. Это может быть пост - обзор или отзыв.
-При возникновении споров относитесь с уважением друг к другу, а так же приводите аргументы.
Разрешено всё, что не запрещено правилами Пикабу.