


Как работает баянопоиск Пикабу
В этом посте я расскажу в деталях как устроен поиск похожих постов на Пикабу и почему баянометр иногда молчит :)
Постараюсь все рассказать популярным языком, не скатываться в узкоспециализированные терминологии. Полагаю этот пост будет интересен как пикабушникам, которые вероятно не раз сталкивались результатами баянопоиска, так и другим читателям, которым интересен опыт разработки сложных систем.
Текущая технология поиска баянов была разработана нами в запущена в бой в октябре 2014 года. Это была вторая версия баянопоиска и её целью было улучшить качество и скорость поиска похожих постов.
Баянопоиск состоит из трех модулей: поиск текста, поиск видео и поиск картинки. Самый сложный и интересный - это поиск по картинкам, но для начала быстренько разберемся с другими видами поисков.
ПОИСК ВИДЕО
Модуль поиска похожего видео работает только для видео, добавленных с внешних видео-хостингов, таких как youtube, vimeo, coub и пр. Поиск выполняется по внешнему идентификатору, который есть в URL к видео. Например, в следующем URL https://www.youtube.com/watch?v=dQw4w9WgXcQ идентификатором будет dQw4w9WgXcQ. Таким образом поиск похожих постов для видео из внешних видео-хостингов самый примитивный и ищет по сути посты, в которых добавили такую же ссылку на видео. Но если пользователь заливает видео файл (mp4, webm и пр), то тут уже другая песня и работает более сложный поиск по картинке, который мы разберем чуть ниже.
Исходя из рассказанного не сложно догадаться, что если добавить на Пикабу видео с youtube и затем попробовать такое же видео добавить с vimeo или просто залить как mp4 файл, то баянопоиск его никак не найдет сходства, так как у vimeo будет другой идентификатор у видео, а mp4 файл будет искаться другим способом.
Немного статистики по этому виду поиска: на текущий момент у нас в базе 932 тыс идентификаторов видео внешних хостингов, из них youtube - 90%, coub - 7.8%, vimeo - 0.7%, rutube и vk по 0.5%, liveleak всего 0.1%.
ПОИСК ТЕКСТА
Поиск по тексту посложнее и интереснее, почти как оргия с кучей фильтров) Основная сложность такого поиска - быстро найти сходство между одним текстом и миллионами других в базе данных. Подкованные в разработке ребята скажут, тут можно обычный LIKE использовать, либо можно Full-Text Search, Sphinx, ElasticSearch и тд. Но не все так просто. Одно дело искать строку среди разных текстов, а другое дело искать сходство текста с другими текстами. Ведь автор поста мог написать абзац своего текста, затем вставить абзац скопированного анекдота и поиск баянов должен будет найти не постил ли кто-нибудь уже такой анекдот. Также не забываем про объемы поиска, которые постоянно растут (сейчас более 8 млн постов), а требование стоит в моментальном поиске в момент набора текста.
Плотно покурив статьи разных умных гиков и глубоко погрузившись в пучину алгоритмов неточного поиска текстов было решено написать свой крутой велосипед)
Для объяснения принципа работы этого велосипеда возьмем следующую короткую панграмму с небольшим текстом:
Эй, жлоб! Где туз? Прячь юных съёмщиц в шкаф. Не судите строго на pikabu.
Шаг 1 - нормализация
Первым делом баянопоиск нормализует текст для русского языка: переведет все в нижний регистр символов, заменит буквы "ё" на "е" (а также "ў" на "y", "i" на "и"), удалит символы троеточия "…", приведет все дробные числа к единому формату (запятая вместо точки: 2.15 -> 2,15). Затем из текста удаляются замаскированные маты, типа "с@ка", "ебл#н", и цифры с буквенными наращениями, например 2-x, 3мя, 101-й.
В нашем случае в тексте изменится только регистр символов и буква "ё" в слове "съёмщиц":
эй, жлоб! где туз? прячь юных съемщиц в шкаф. не судите строго на pikabu.
Шаг 2 - удаление шаблонных фраз
На Пикабу пользователи часто в постах указывают одни и те же фразы, что в итоге приводит к бессмысленным результатам поиска, когда находятся сотни постов с такой фразой. Примеры фраз: "коммент для минусов внутри" (старички на Пикабу всплакнули, да?), "благодарю за внимание", "баянодетектор молчал". Или вот последнюю фразу что добавляли недавно: "источник - телеграм канал плохой шофер".
Удаление немного хитрое, оно учитывает разные варианты написания. Например, для фразы "взято с vk" будут удалены также варианты "взято из вконтакте", "взято из вк", "взято c vkontakte" и тд.
В нашем тексте есть шаблонная фраза "не судите строго", поэтому после её удаления текст станет следующим:
эй, жлоб! где туз? прячь юных съемщиц в шкаф. на pikabu.
Шаг 3 - токенизация
Токенизация - это по сути разбиение текста на отдельные независимые кусочки (термы), каждый из которых является минимальным самостоятельным фрагментом текста. Ай, проще это назвать разбиением текста на предложения и отдельные слова :D Понавыдумывали умных слов тут.
Мы бежим по всему тексту, ищем пунктуацию и принудительные переносы строк, отдельно стоящие слова, и затем разделяем текст на отдельные предложения (токены).
В нашем случае получится 4 токена:
- эй жлоб
- где туз
- прячь юных съемщиц в шкаф
- на pikabu
Шаг 4 - удаление стоп-слов
В каждом токене мы удаляем из текста так называемые стоп-слова. Так принято называть слова, в которых нет особой пользы при поиске. У Пикабу свой словарь таких слов и в нем сейчас 576 слов. Помимо общепринятых стоп-слов, типа "моя", "никуда", "однако", "через" и тд, в наш словарь мы включили и популярные маты с разным вариантом их написания :D Да-да, особо смысла искать маты нет, так как даже в анекдотах их кто-то маскирует, кто-то заменяет на другие слова, кто-то заменят другими матами. Также к стоп-словам мы отнесли pikabu и старое его название - pickaboo.
После удаления стоп-слов наш текст примет следующий вид (пропали "где", "в", "на" и "pikabu"):
эй жлоб // туз // прячь юных съемщиц шкаф
знаком "//" я показал разделение на токены. Как видно, у нас минус 1 токен, так как он целиком был удален.
Шаг 5 - словарь синонимов
Заменяем слова в токенах на синонимы по словарю из 6332 пар. Например, если в тексте будут слова "баянометр", "баянопоиск", "боянодетектор", то это разные слова, но все они об одном и том же. Поэтому в этом шаге мы их заменяем на одно общее слово, в частости "поиск".
Ну что, давайте посмотрим на что наш текст будет похож после этого шага:
эй жлоб // аристократ // прячь юных съемщиц шкап
Да, тут можно посмеяться, но слово "туз" имеет синоним "аристократ" :D А слово "шкаф" заменено на более древнее "шкап" (мы в разработке Пикабу знаем толк в извращениях :) ).

Шаг 6 - стемминг
Стемминг - это процесс удаления окончания и суфиксов у слов, чтобы осталась некая основа слова. Например, в русском языке слово "работа" может иметь много форм: работой, работал, работ, работе, работу и тд. Так вот стемминг все эти формы приведет к основе - работ.
После стемминга наш текст станет ещё краcивее:
э жлоб // аристократ // пряч юн съемщиц шкап
Шаг 7 - замена букв
Чтобы убрать различия в написании слов с гласными "о"/"а" и "е"/"и", мы все буквы "а" и "и" заменяем "о" и "е". Тем самым что автор напишет "присосался", что "пресасался" - для баянопоиска это будет одно и то же слово "пресосолся" :D
Ну что, взглянем на текст сейчас после этого шага:
э жлоб // орестокрот // пряч юн съемщец шкоп
Красота)

Шаг 8 - сортировка токенов
У нас в примере всего 3 токена осталось, но в реальности часто посты имеют большие тексты и там по 100-500 токенов. Так много токенов нам не получится искать, накладно. Поэтому мы должны выбрать токены самые значимые для поиска. Для этого токены делятся на 4 группы:
1. ничтожные токены, в которых 1 слово
2. слабые токены, в которых меньше 5 слов.
3. нормальные токены, от 5 до 16 слов.
4. сильные токены, от 16 и более слов.
Для нас самые привлекательные - нормальные токены, так как они и не жирные и не скудные. Поэтому мы сортируем так, вначале идут нормальные, затем сильные и в конце слабые токены. Ничтожные мы используем только в том случае, если других токенов у нас нет или если в этом токене URL (ссылка на что-нибудь).
Итого для поиска мы будем использовать следующие два токена:
1. пряч юн съемщец шкоп
2. э жлоб
Шаг 9 - расчет хэшей для токенов
Хэш - это представление любой информации в виде какой-то строки с всегда одинаковой длиной. Саму функцию хэша рассказывать не буду, там много всякий сложной математики. Но особенность нашего хэша в том, что мы для кажого слова внутри токена вычисляем некую контрольную сумму, затем сортируем по ней все слова внутри токена и затем берем лишь 5 первых слов и уже по ним финально вычисляем итоговый хэш как строку из 32 символов. Так что порядок слов не имеет значения внури токена: что маша мыла раму, что рама мыла машу.
Итого, для наших двух токенов будут следующие хэши:
1. 77a4bf0983fad218064fb2d36911c71d
2. 7b9758f810f00cdf169e2810e56127fe
Шаг 10 - поиск токенов в БД и сравнение постов
Каждый пост при добавлении на сайте проходит процедуру регистрации в базе данных баянопоиска. Так что каждый текст каждого поста проходит все эти 9 шагов и на выходе получаются токены, которые мы сохраняем в базу. Сейчас в базе насчитывается 34 миллиона токенов и вот по ним мы и ищем токены каждого нового текста из черновиков постов)
Если мы нашли токены в БД, то рано радоваться, ещё нет гарантии, что в том посте, где были найдены такие же токены, на самом деле текст совпадает с искомым. Мы выгружаем тексты постов, которые были найдены по токенам, и сравниваем уже более тщательно: сравниваем статистику количества одинаковых слов и вычисляем наибольшую общую подстроку . Немного математики с полученными данными для расчета релевантности (процент сходства текстов) и вуаля! Мы нашли баяны и показали на какой % тексты совпадают) Посты с релевантностью меньше 30% мы откидываем, так как это погрешности поиска.
Итого, основная фишка нашего поиска по текстам - это создать токены, по которым мы быстро можем найти посты с похожими текстами, а далее мы уже более плотно сравниваем тексты найденных постов с искомым текстом, чтобы точно определить % схожести и отбросить, если ложноположительный результат поиска был) Конечно, можно найти 100500 причин назвать этот велосипед извращением, особенно с учетом всех замечательных решений сегоднешнего дня, но

ПОИСК КАРТИНОК
Ну вот мы и добрались до самого вкусного, за что я в течение последних 7 лет икал непрерывно.
Итак, какие задачи ставились перед новой версией баянопоиска по картинкам в 2014 году:
1. уметь искать отдельные независимые фрагменты картинок в длиннопостах. Ньюфаги вероятно не знают, а олдфаги позабыли, но раньше на Пикабу нельзя было добавлять несколько картинок в пост, только 1, и тогда были популярны т.н. длиннопосты, где вставлялась 1 длинная картинка с коллажем из разных фото. Вот пример ещё небольшого поста Стальные яйца. ;
2. уметь искать картинки перевернутые, отзеркаленные;
3. уметь искать немного обрезанные картинки или картинки с добавленными границами. Опять же старички припомнят эпоху демотиваторов, где полезная для поиска картинка имела черную толстую рамку с текстом;
4. уметь искать картинки с измененным цветом;
5. искать быстро;
6. сортировать результаты поиска по релевантности.
Изучив матчасть, прочитав кучу непонятной литературы, посмотрев на сомнительные готовые решения, было решено сделать свой велосипед!
Для объяснения как работает поиск по картинкам давайте возьмем для примера следующее изображение:

Шаг 1 - подготовка изображения
Если изображение имеет анимацию (gif) или вместо изображения используется видео (mp4, webm и др), то мы берем для дальнейшей работы только первый кадр.
Применяем фильтр рассеивания (Dispecle), который немного размажет границы (заметно по забору), но при этом сгладит шумы (пропали артефакты возле текста):

Шаг 2 - фрагментирование
Далее нам нужно разделить изображение на независимые фрагменты, каждый фрагмент мы будем искать отдельно. Для этого мы переводим изображение в черно-белый цвет (по сути оставляем только информацию о яркости каждого пикселя) и сжимаем по ширине до 128px самым быстрым алгоритмом масштабирования (тут качество не важно, важна скорость).
Начинаем анализ пикселей получившегося изображения сверху вниз (построчно) и затем слева направо (по каждой колонке), чтобы откинуть бесполезную информацию и найти отдельные фрагменты.
Анализ работает так:
- если в строке или колонке все пиксели имеют совсем небольшое количество уникальных значений яркостей (напомню, что картинка черно-белая, т.е. только яркости есть), то мы считаем эту строку пикселей бесполезной. Под такие строки попадают любые однородные фоны, на которых есть мелкий шум или текст.
- если статистика яркостей текущей строки на более чем 90% отличается от статистики яркостей предыдущей строки, то баянопоиск считает, что в данной строке начался новый фрагмент изображения.
На следующей иллюстрации желтыми полосками показано что баянпоиск посчитает бесполезным при построчном анализе, а голубыми - при анализе колонок.

Итак, мы нашли 1 полезный фрагмент, и откинули ненужные границы и тексты вокруг него. Однако поиск по базе данных мы будем делать все же по двум изображениям: оригинальному со всеми границами и текстами, и отдельным найденным фрагментом только с медведем.
Шаг 3 - оценка фрагментов
Баянопоиск умеет искать как по геометрии изображения, так и по статистике цветов. По геометрии имеет смысл искать, если у изображения есть перепады яркостей и их много, например, светлая и темные стороны чего-либо, а для поиска по цветам нужно наличие оных в картинке).
Приведу примеру двух плохих для поиска картинок:

В той, что скудная геометрия, компьютерное зрение может спутать со 100500 различными другими картинками, например, с флагом Польши, у него такая простая геометрия, линия сверху и линия снизу. В той, где скудная статистика цветов действительно всего несколько оттенков серого. В итоге баянопоиск на данном шаге решает, какие способы поиска имеет смысл использовать для каждого из фрагментов) Если изображение супер скудное по всем параметрам, то баянопоиск ищет только по геометрии и будь что будет :D
В нашем примере с медведем баянопоиск посчитает, что это изображение выгодно искать и по геометрии и по статистике цветов)
Шаг 4 - расчет геометрии изображений
Ещё это называют перцептивным хэшем. Принцип расчета очень прост: мы сжимаем изображение до супер маленького размера, например, до квадрата 16 на 16 пикселей, затем переводим все пиксели в черно-белую палитру, и сканируем пиксели по порядку с проверкой их по выбранному пороговому значению яркости. Если яркость пикселя ниже порога - это бит 0, если яркость выше порога - это бит 1. В итоге на изображение 16x16 у нас будет 256 бит, которые укладываются в 32 байта.
Баянопоиск рассчитывает таким образом два перцептивных хэша: 8x8 - для грубого поиска и 24x24 - для точного. На следующем изображении показаны представления этих хэшей. Синий квадрат - это значит уровень яркости был выше порогового (бит 1), а белый квадрат - ниже (бит 0). Если изрядно выпить и прищуриться, то в этих квадратах можно увидеть мишку, сидящего на лавке :D
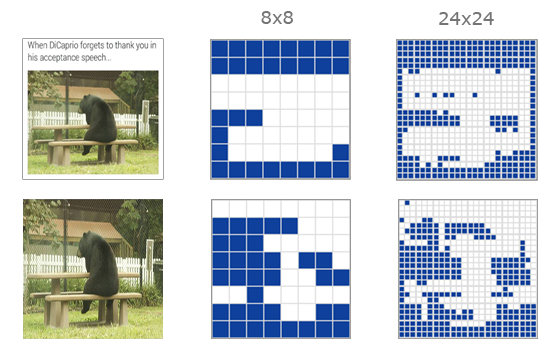
Итого, для грубого поиска по геометрии изображения мы рассчитали хэш длиной 8 * 8 = 64 бита, а для точного поиска - 24 * 24 = 576 бит.
Шаг 5 - расчет статистики цветов
Мы назвали этот способ расчета - гистограммный хэш, так как он строится на базе гистограммы (статистике цветов) изображения. Суть его проста: мы считаем для каждого канала RGB (Красного, Зеленого и Синего) статистику яркостей и получаем три гистограммы. Также мы строим гистограмму и для самого канала яркости (Luminance). Далее делаем квантование уровней, дискретизацию и получаем биты информации для каждой гистограммы) По сути так работает перевод аналогового сигнала в цифровой в телекоммуникациях.
Также как и в расчете геометрии мы делаем грубый и точный расчет. На следующем изображении показаны эти гистограммы (уже с квантованием по уровням):

Шаг 6 - поиск хэшей по базе
Увы, мы не можем искать по точному совпадению хэшей, так как минимальное отличие геометрии или гистограммы откинет потенциально похожий пост. Поэтому для поиска по базе данных мы применяем расчет расстояния Хэмминга , т.е. считаем количество отличающихся бит между искомым хэшем и теми, что в БД. Выглядит это примерно так:01010101111000010101
01000101111100010101
В этих двух двоичных представлениях хэшей у нас отличаются только 2 бита, так что расстояние Хэмминга тут равно двум. Таким образом мы сравниваем искомый хэш с более чем 13 миллионами фрагментов изображений в БД.
Для ускорения поиска вначале мы ищем по грубым перцептивным и гистограммным хэшам. Для грубого перцептивного хэша допустимое количество отличающихся бит - 16, т.е. 25% от длины самого хэша (64 бит). Для гистограммного - 12 (18% от 64 бит).
Затем полученную выборку постов фильтруем уже точными хэшами, которые сложнее сравнить. Там для перцептивного хэша допустимое количество ошибок не превышает 140 бит (24%), а для гистограммного - 200 (39%).
Сортируем результаты фильтрации постов по количеству отличий в битах, вначале будут идти посты с наименьшим отличием, т.е. у которых хэши больше всего похожи друг на друга.
Шаг 7 - финальная фильтрация
После поиска по базе данных мы выбрали большую пачку потенциально похожих постов. Теперь нам нужно ещё разок фильтровать эту пачку, чтобы откинуть посты, которые вероятно по ошибке (погрешности) система посчитала похожими. Для этого мы применяем ещё один хэш - DCT (дискретно косинусное преобразование) по изображению и по полученному результату строим снова перцептивный хэш. Сравниваем найденные по базе данных фрагменты с только что рассчитанным DCT-хэшем (тоже через расстояние Хэмминга), и если ошибок в битах не более чем 26%, то считаем, что это похожий пост.
Далее немного волшебной математики с разными показателями поиска и у нас на руках релевантрость для каждого найденного фрагмента. Отсеиваем все фрагменты, у которых релевантность ниже 18%, а все остальное показываем пользователю как возможные дубликаты)
ЭКСПЕРИМЕНТ С МЕДВЕДЕМ
Давайте проверим что будет, если к нашей картинке с медведем мы добавим смайлик, обрежем края немного, и перевернем на 180 градусов?

Геометрия изображения очень сильно поменялась, так как во-первых мы обрезали картинку, во-вторых перевернули. На следующей иллюстрации красным я подсветил отличия при сравнении перцептивных хэшей этих двух картинок. Отличий слишком много, поэтому поиск по перцептивному хэшу не дал результат:
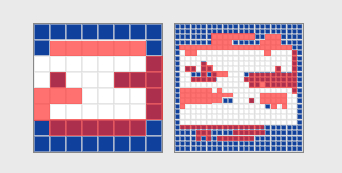
А вот статистика цветов практически не поменялась и баянопоиск посчитал, что по гистограммному сравнению картинки равны на 80%!
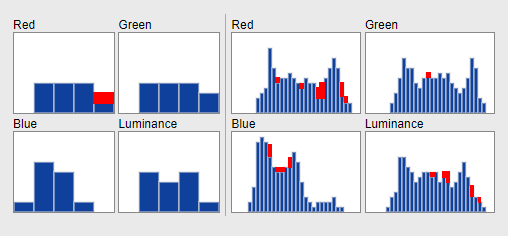
Немного математики с DCT-хэшем и остальными результатами и итоговый вердикт баянопоиска - картинки схожи на 43%!
Теперь вы чуть больше знаете о том, как Пикабу ищет баяны. Надеюсь было интересно. Если будут вопрос - смело задавайте в комментах.
Немного о планах. Мы планируем попробовать заменить баянопоиск на новую версию, уже с ML (машинное обучение, нейронные сети). Но пока что ещё точно не знаем получится ли или нет, но если получится, то постараемся рассказать и о принципах его работы)










Как работает Пикабу
4 поста121 подписчик