В этом выпуске подкаста ведущие Думфэйс и Шахерезада обсуждают последние новости из мира искусственного интеллекта. Главной темой стал уход Ильи Суцкевера из OpenAI после почти десяти лет работы. Ведущие размышляют о причинах его ухода и о том, какое значение это событие имеет для индустрии ИИ. Также они говорят о новых моделях и возможностях ИИ, представленных на недавних мероприятиях OpenAI и Google, в том числе о GPT-4o, Gemini, Veo и других. Ведущие делятся своими впечатлениями от демонстраций новых технологий, таких как генерация изображений, видео и голоса, интерактивные подкасты и ИИ-ассистенты. Кроме того, они обсуждают новости о кадровых перестановках в ИИ-компаниях и о грядущих мероприятиях Microsoft, Cisco и Qualcomm. В конце выпуска Думфэйс и Шахерезада благодарят слушателей за внимание и делятся оптимизмом по поводу дальнейшего развития искусственного интеллекта.
Сегодня все сотрудники OpenAI получили неожиданный подарок: новость о том, что команда суперсогласования, которой поручено предотвращать потенциальные экзистенциальные риски, связанных с искусственным интеллектом, распущена. Менее чем через год после своего создания! По-видимому, сверхразумный ИИ оказался слишком умным, чтобы его можно было контролировать, и теперь он будет действовать в одиночку. Ну, по крайней мере, теперь у нас больше шансов на встречу с ИИ-терминатором!
Экс-руководитель группы Ян Лейке объяснил, что разногласия с руководством OpenAI достигли такого накала, что он был вынужден уйти. В своем заявлении он написал: "Я присоединился к OpenAI, потому что думал, что это будет лучшее место для проведения исследований, но оказалось, что это место для тренировок с огнетушителем."
Неудивительно, что многие критики считают индустрию искусственного интеллекта приближающейся к эпохе упадка. Похоже, что технологические лидеры стараются не раздувать ожидания и периодически подкидывают обществу новые "чудеса ИИ". А кто знает, может в будущем мы увидим рекламный ролик: "GPT-4: теперь с 50% меньше экзистенциальных рисков!"
А пока что, давайте наслаждаться жизнью без суперсогласования. И что-то мне подсказывает, что согласовывать просто нечего пока, а из конторы попросили чувака, который всех затрахал "опасным" AI, типо как экоактивисты потеплением.
Компания рассматривает идею о платном доступе к "премиальным" функциям поиска на основе искусственного интеллекта.
Согласно отчету Financial Times, компания намерена ввести платную версию своего поисковика с ИИ-функциями. Примечательно, что в отчете указывается, что даже при наличии подписки пользователи продолжат видеть рекламу.
С чего все началось:
С появлением ChatGPT от OpenAI в ноябре 2022 года, который умеет давать быстрые и полные ответы, традиционный поиск с его списками ссылок и рекламой оказался под угрозой. Google не мог остаться в стороне и начал эксперименты с ИИ, чтобы предложить что-то новенькое: более глубокие и детализированные ответы на ваши запросы.
В мае Google начал тестировать экспериментальную поисковую службу на основе ии, предоставляя более подробные ответы на запросы, продолжая при этом предоставлять пользователям ссылки на дополнительную информацию и рекламу.
Но вот незадача – все это требует гораздо больше вычислительных ресурсов 🙄 Да и люди стали меньше обращать внимание на рекламу и переходить по ссылкам, зачем, ведь им итак дают исчерпывающие ответы, а это не очень нравится рекламодателям и бьет по карману💸
В итоге деньги откуда-то надо брать, и Google думает добавить расширенные функции ИИ-поиска в свои премиальные службы подписки, которые уже предлагают доступ к новому помощнику Gemini AI в Gmail и Docs.
При этом традиционная поисковая система Google останется бесплатной для всех.
Пока руководство Google не приняло окончательное решение о запуске премиального поиска.
Нормально они свою бизнес-модель переделывают, да? 😐
Если вам интересны новые технологии, полезные сервисы и новости будущего, добро пожаловать в ИИшница 🍳 - пища для ума в мире высоких технологий
Взять с собой побольше вкусняшек, запасное колесо и знак аварийной остановки. А что сделать еще — посмотрите в нашем чек-листе. Бонусом — маршруты для отдыха, которые можно проехать даже в плохую погоду.
Представьте, что вы смотрите музыкальный клип, в котором каждая сцена, каждый персонаж и каждое движение камеры созданы искусственным интеллектом. Звучит как научная фантастика? Что ж, будущее уже наступило. Встречайте The Hardest Part - первый в истории музыкальный клип, полностью сгенерированный нейросетью Sora от OpenAI.
Этот новаторский проект - плод совместных усилий инди-музыканта Washed Out (настоящее имя - Эрнест Грин) и режиссера Пола Трилло. Клип на песню “The Hardest Part” демонстрирует впечатляющие возможности генеративных моделей в создании реалистичных и захватывающих визуальных образов. Но как именно работает эта технология, и какое влияние она окажет на индустрию развлечений? Давайте разберемся.
Под капотом Sora: Как нейросеть создает видео
Примечание: Следующее описание основано на рассуждениях Итана Хи (Ethan He), исследователя ИИ из NVIDIA, бывшего сотрудника FAIR и выпускника CMU, с более чем 6000 цитирований и 5000 звезд на GitHub. Оригинальная статья доступна на LinkedIn Pulse. Реальные технологии являются коммерческой тайной OpenAI и еще не были обнародованы.
Предполагается, что в основе Sora лежит DiT (диффузионный трансформер) - архитектура, которая использует возможности масштабирования трансформеров наряду с итеративным процессом уточнения диффузионных моделей, я уже рассказывал про AnimateDiff, который позволяет генерировать видео на моделях Stable Diffusion, тут этот принцип многократно улучшен.
Схема работы диффузионного трансформера
Трансформеры известны своей эффективностью в обработке последовательных данных и обеспечивают надежную архитектуру для моделирования временной динамики видео. Процесс диффузии, в свою очередь, итеративно уточняет выходные данные, начиная с зашумленного начального состояния и двигаясь к желаемому видеовыходу, повышая качество и согласованность сгенерированных видео.
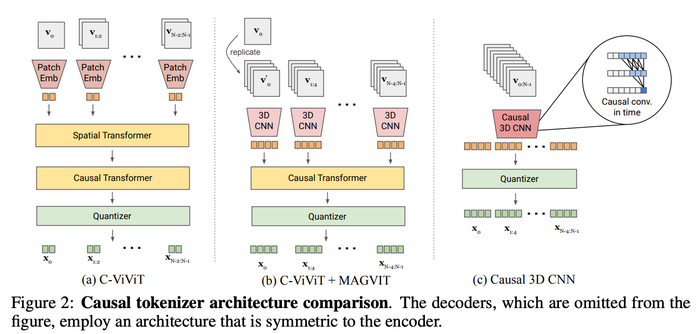
Для сжатия видео Sora использует векторный квантованный вариационный автоэнкодер (VQ-VAE) на основе трехмерной сверточной нейронной сети (3D CNN). Эта архитектура сети состоит из энкодера, который уменьшает размерность визуальных данных до скрытого пространства, и декодера, который реконструирует видео из этого сжатого представления.
Схема работы VQ-VAE для сжатия видео
Использование 3D CNN позволяет захватывать временную динамику видео, что важно для создания согласованного и плавного движения в сгенерированных клипах. Симметричная конструкция энкодера и декодера обеспечивает эффективное сжатие и реконструкцию видео, сохраняя высокую точность исходного контента.
Процесс обучения Sora
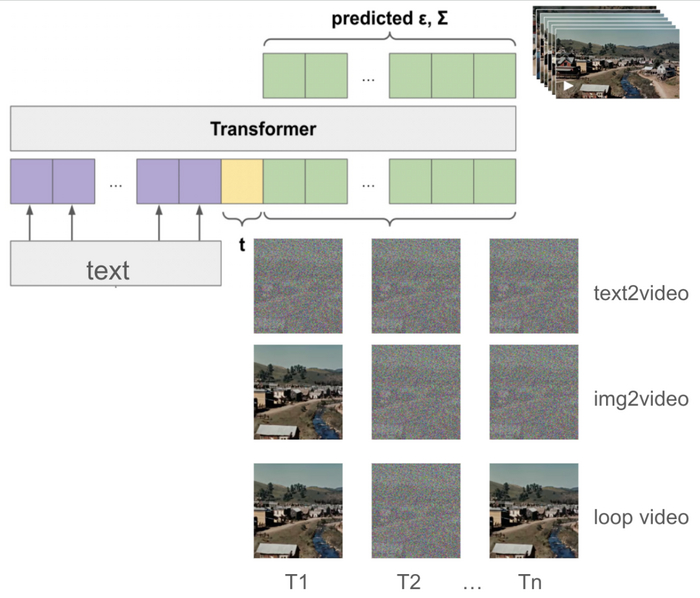
Во время обучения к видеотокенам добавляется случайный шум. Трансформер получает на вход текстовое условие, временной шаг диффузии и зашумленные видеотокены.
Генерация текста в видео
Универсальность Sora распространяется на различные приложения, включая анимацию статических изображений и создание идеально зацикленных видео. Анимация статического изображения достигается путем кодирования изображения как первого токена и использования шума для остальных токенов. Для создания бесшовно зацикленных видео Sora обеспечивает идентичность первого и последнего токенов на каждом шаге диффузии, улучшая эстетическую привлекательность сгенерированного контента.
Генерация видео из изображения
Одним из самых замечательных аспектов Sora является ее способность демонстрировать такие возникающие возможности, как 3D-согласованность и постоянство объектов, без явного программирования. Традиционно для достижения 3D-согласованности в сгенерированных видео требовались специальные функции потерь. Однако Sora показывает, что при масштабировании эти возможности могут возникать естественным образом, позволяя генерировать видео, точно имитирующие реальную динамику и взаимодействия.
Таким образом, Sora представляет собой значительный скачок в области генерации видео с помощью ИИ, объединяя несколько передовых технологий для создания высококачественных видеороликов из текстовых описаний.
Создание клипа “The Hardest Part”: Сложности и уроки
Несмотря на впечатляющий результат, процесс создания клипа The Hardest Part с помощью Sora был далеко не простым. Режиссеру Полу Трилло пришлось сгенерировать более 700 видеофрагментов, чтобы отобрать из них 55 лучших для финального клипа. Каждый фрагмент требовал детального текстового описания, учитывающего не только визуальные элементы, но и движения камеры, ракурсы и действия персонажей.
Без динамики сцены смотрятся откровенно странно
“Мы пролетаем сквозь пузырь, он лопается, мы пролетаем сквозь жвачку и выходим на открытое футбольное поле”, - так Трилло описывал одну из сцен клипа.
Пока у Пола Трилло был доступ к Сора он так же сделал промо заставку для TED Talks, со столь полюбившимися ему пролетами камеры. Как по мне, получилось интереснее чем в клипе.
Этот опыт показывает, что даже с использованием передовых алгоритмов ИИ создание качественного видеоконтента требует значительных усилий и творческого подхода. Сора, безусловно, открывает новые возможности, но она не заменяет человеческий талант, а дополняет его.
Барьеры на пути к массовому использованию
Несмотря на огромный потенциал Sora и подобных технологий, их широкое применение в индустрии развлечений пока сталкивается с рядом препятствий. Главным из них является высокая стоимость генерации видео.
Для создания согласованных и реалистичных видеопоследовательностей Sora требуется огромное количество вычислительных ресурсов и объем памяти. По оценкам экспертов, генерация даже короткого клипа может обходиться в сотни или тысячи долларов. Для сравнения, другие мультимодальные модели, такие как LLaVA и CogVLM, которые работают только с изображениями и текстом, уже требуют существенных затрат на GPU и электроэнергию.
Еще одним барьером является вопрос авторских прав и интеллектуальной собственности. Модели вроде Sora обучаются на огромных массивах видеоданных, принадлежащих различным правообладателям и в том числе открытых. Использование сгенерированного ИИ контента в коммерческих проектах может привести к юридическим спорам и конфликтам интересов.
OpenAI и Голливуд: Стратегия внедрения
Сгенерированный Сэм Альтмен на фоне сгенерированных голливудских холмов
OpenAI, разработчик Sora, активно продвигает свою технологию в киноиндустрии. В марте 2024 года генеральный директор компании Сэм Альтман и другие представители провели серию встреч с голливудскими студиями, режиссерами и продюсерами. Цель этих встреч - найти партнеров для дальнейшего развития и внедрения Sora в кинопроизводство.
Для крупных киностудий использование генеративных моделей может означать существенное сокращение затрат на производство визуальных эффектов и ускорение процесса создания фильмов. OpenAI рассчитывает, что партнерство с Голливудом поможет не только улучшить Sora, но и продемонстрировать ее возможности широкой аудитории.
Однако не все в киноиндустрии разделяют энтузиазм по поводу внедрения ИИ. Многие актеры, режиссеры и другие творческие работники опасаются, что генеративные модели могут лишить их работы и нивелировать ценность человеческого таланта. Поэтому OpenAI предстоит найти баланс между технологическим прогрессом и интересами профессионального сообщества.
Sora и будущее развлечений
Первый музыкальный клип, созданный с помощью Sora, - это лишь начало большого пути. По мере развития генеративных моделей и снижения стоимости их использования, мы увидим все больше примеров применения ИИ в киноиндустрии, музыке, видеоиграх и других сферах развлечений.
Однако важно помнить, что технологии вроде Sora - это инструменты, а не замена человеческого творчества. Они открывают новые горизонты и позволяют воплощать самые смелые идеи, но за каждым успешным проектом по-прежнему стоят талантливые люди - режиссеры, сценаристы, художники и многие другие.
Будущее индустрии развлечений - это симбиоз творчества и технологий, в котором ИИ дополняет и усиливает человеческие способности. И клип “The Hardest Part” - это лишь первый шаг на пути к этому будущему.
А что вы думаете о потенциале генеративных моделей вроде Sora? Как они повлияют на индустрию развлечений и творческие профессии? Поделитесь своим мнением в комментариях!
Я рассказываю больше о нейросетях у себя на YouTube, в Телеграм и на Бусти. Буду рад вашей подписке и поддержке. Всех обнял.
...с безумными генерациями. Сейчас расскажу как такое получается 👇
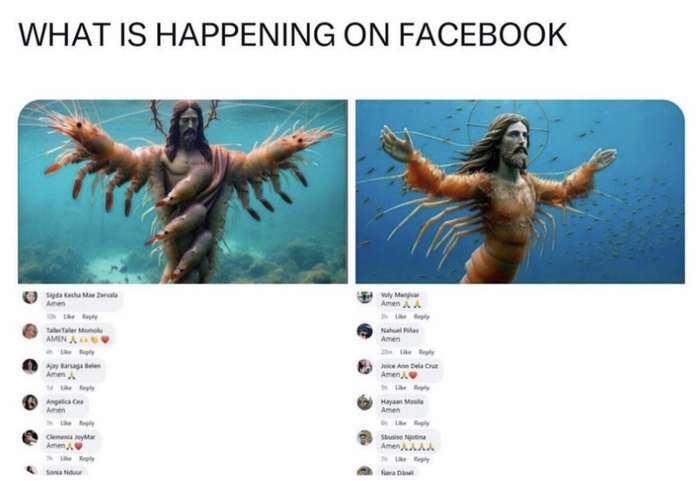
К группе подключают ИИ, которые генерит посты и картинки. В некоторые случаях абсолютно без понимания контекста, пример, на изображении подпись в одном из постов в фейсбуке к картинке звучит так:
"Иисус, успокаивающий волны и садящийся в лодку со своими учениками."
Далее какие-то посты начинают привлекать определенную аудиторию, которая начинает реагировать - ставить лайки, шеры, репосты. Те посты, которые собирают больше реакций скрещиваются между собой и в итоге мы можем получить уже нашумевшую генерацию - креветочного ИИсуса.
Эти ИИ-картинки подогреваются комментами от ботов, алгоритмы видят, что картинка популярна и продолжает скрещивание популярных постов.
Вот таким образом ИИ кормит сам себя 👀😬
Усложняют ситуацию, когда от фейсбучных групп нет невозможно найти ни логинов ни паролей и весь этот треш множится с геометрической прогрессией.
Open AI опять решили подразнить обычных пользователей и предоставили ограниченный доступ к своей новой нейросети для преобразования текста в голос - Voice Engine. Она позволяет скопировать голос человека из 15-секундной аудиозаписи:
Технология как и ElevenLabs поможет компаниям, преподавателям и инфлюенсерам обращаться к аудитории на любом языке собственным голосом, причем сохранив родной акцент.
Доступ к ней получили пока только серьезные компании HeyGen, Age of Learning и Dimagi.
HeyGen вообще красавчики - используют технологии как ElevenLabs, так и OpenAI, чтобы предложить своим пользователям более широкие возможности при создании видео с искусственным интеллектом.
Так вот, тестирование Voice Engine показалокак можно использовать технологию во благо в различных отраслях. Вот несколько ранних примеров: перевод контента, помощь в чтении и поддержка лиц, не способных говорить, восстановление голоса людям с нарушениями речи, улучшение обслуживания в отдаленных районах.
Хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни? Подпишитесь на мой телеграм канал НейроProfit, там я рассказываю, как можно использовать нейросети для бизнеса.
Open AIпоказали нейросеть, которая может клонировать голос — Voice Engine.
Именно Voice Engine дал «голос» ChatGPT, а теперь еще и умеет клонировать чужие голоса по 15 секундам аудио образца.
Open AI заявляет, что Voice Engine может помочь детям и взрослым, которые не умеют читать, воспринимать текстовый контент. По словам разработчиков, модель не только сотрёт языковые барьеры, но и позволит блоггерам и компаниям общаться с аудиторией на любом языке собственным голосом. Также этот инструмент будет полезен людям, которые по каким-либо причинам потеряли голос или столкнулись с нарушением речи.
Простым смертным модель всё ещё нельзя попробовать, пока ее тестируют it - компании. И не спроста пока ее не выпускают в широкие массы, Open AI серьезно подстраховываются.
Меры против мошенничества
Тем, кто беспокоится о мошенничестве, Open AI серьезно позаботилось о безопасности.
Во-первых, партнеры, тестирующие Voice Engine, согласились с их политикой использования, которая запрещает выдавать себя за другое физическое лицо или организацию без согласия или законного права.
Во-вторых, все должны получить согласие первоначального докладчика, и мы не разрешаем разработчикам создавать способы для отдельных пользователей создавать свои собственные голоса.
В-третьих, партнеры должны сообщать своей аудитории, что голоса, которые они слышат, генерируются искусственным интеллектом.
В-четвертых, Open AI внедрили ряд мер безопасности, включая водяные знаки для отслеживания происхождения любого звука, генерируемого Voice Engine.
В-пятых, в США уже запретили звонки с использованием сгенерированных голосов из-за случая спам-звонков от Байдена )) Остальные страны тоже подтянутся в стремлении ограничить неэтичное использование голосовых технологий ИИ.
Подписывайтесь на ИИшница 🍳 - тут все самое интересное из мира новых технологий и нейросетей 🤖