
Анализ новостных лент на основе RSS парсинга
12.04.2024 г. я продолжил RSS парсинг популярных новостных лент в России. По результатам наблюдал такую картинку...


Облако слов...
Показать полностью
1
12.04.2024 г. я продолжил RSS парсинг популярных новостных лент в России. По результатам наблюдал такую картинку...
Облако слов...
14.12.2023 г. после онлайн-трансляции прямой линии Президента России, я выполнил RSS парсинг популярных новостных лент в России.
По результатам частотного анализа полученного текста в виде слов (более 448 тыс. слов) при помощи:
- визуализации в трехмерном пространстве;
- построения круговой диаграммы;
- визуализации тепловой карты;
- построения столбчатой диаграммы;
- визуализации в виде облака слов;
- построения точечной диаграммы частоты слов,
наблюдал такую картинку...
P.S. данная информация носит исключительно информационный характер, не является офертой или публичной офертой в соответствии с положениями ст. ст. 435, 437 ГК РФ!

RSS парсинг популярных новостных лент в России

Визуализация популярности 15 полученных слов в трехмерном пространстве
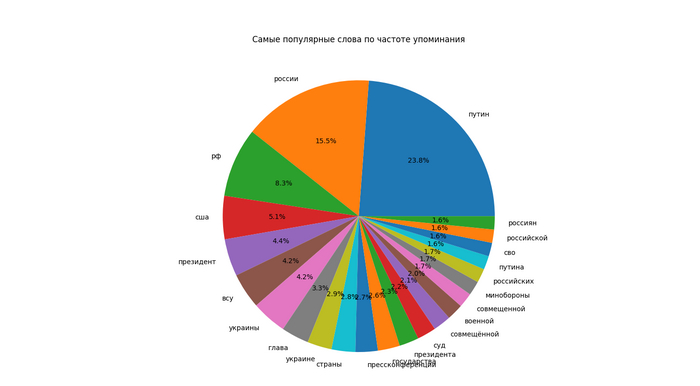
Визуализация популярности 23 полученных слов в виде круговой диаграммы
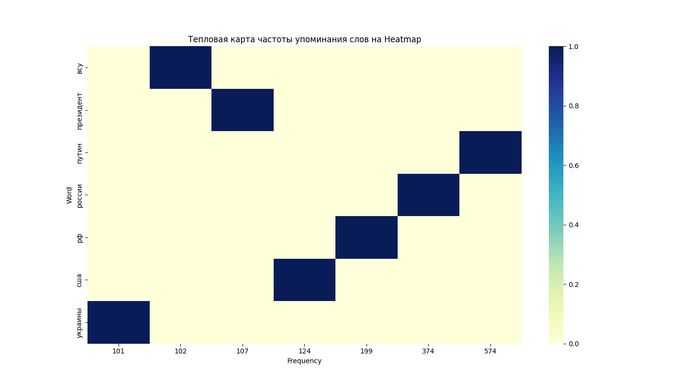
Визуализация популярности 7 полученных слов при помощи тепловой карты Heatmap
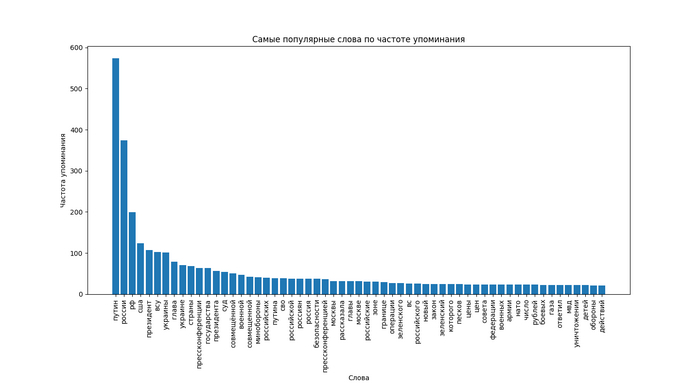
Визуализация популярности 59 полученных слов в виде столбчатой диаграммы

Визуализация популярности 59 полученных слов в виде облака
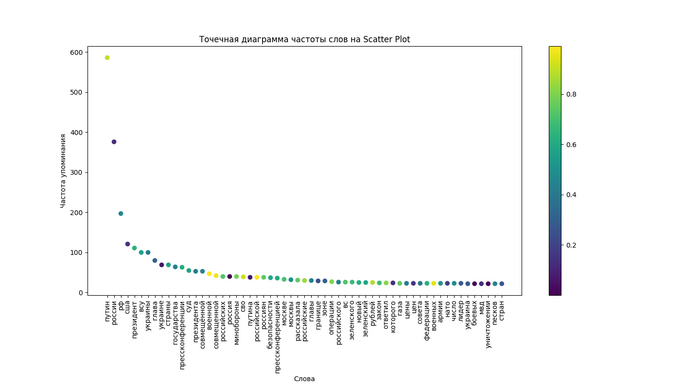
Визуализация популярности 59 полученных слов при помощи точечной диаграммы частоты слов на Scatter Plot
12.12.2023 г. я продолжил RSS парсинг популярных новостных лент в России. По результатам частотного анализа полученного текста при помощи построения столбчатой и круговой диаграмм, а также визуализации в трехмерном пространстве, наблюдал такую картинку...
P.S. данная информация носит исключительно информационный характер, не является офертой или публичной офертой в соответствии с положениями ст. ст. 435, 437 ГК РФ!

RSS парсинг популярных новостных лент в России

Визуализация популярности 75 полученных слов в виде столбчатой диаграммы
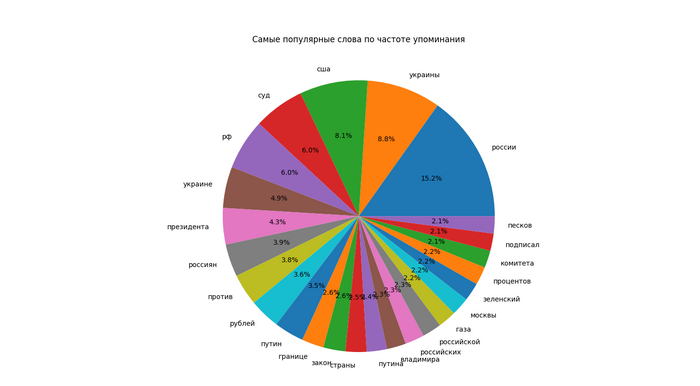
Визуализация популярности 25 полученных слов в виде круговой диаграммы
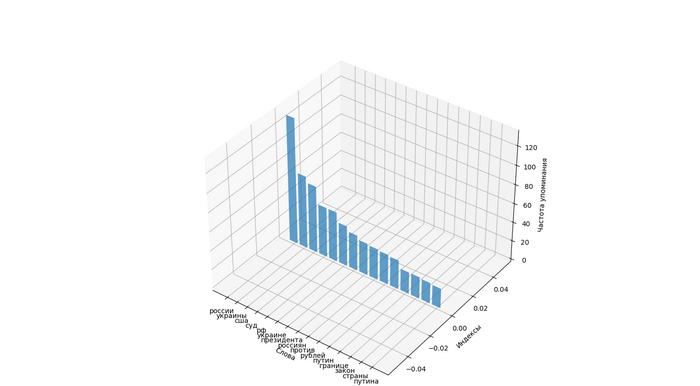
Визуализация популярности 15 полученных слов в трехмерном пространстве
Мы постарались сделать каждый город, с которого начинается еженедельный заед в нашей новой игре, по-настоящему уникальным. Оценить можно на странице совместной игры Torero и Пикабу.
Реклама АО «Кордиант», ИНН 7601001509
10.12.2023 г. по результатам RSS парсинга популярных новостных лент в России и частотного анализа полученного текста при помощи закона Ципфа, а также визуализации слов в виде облака, наблюдал такую картинку...
P.S. данная информация носит исключительно информационный характер, не является офертой или публичной офертой в соответствии с положениями ст. ст. 435, 437 ГК РФ!

RSS парсинг популярных новостных лент в России
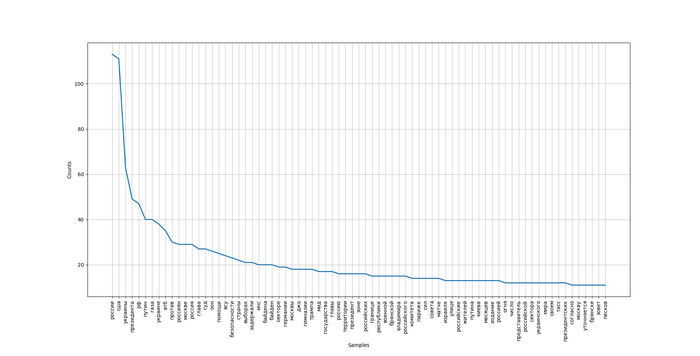
Закон Ципфа иллюстрирует частотность распределения полученных слов

Визуализация популярности полученных слов в виде облака
Все представленные ссылки не принадлежат мне и не мои. Я публикую их в качестве примера.
Итак, сначала как обычно немного предыстории. Понадобилось мне агрегировать все свои новостные источники в один единый. Новостных источников больше 50, а еще всякие Telegram, Youtube каналы, Instagram аккаунты.
Ну т.е. я слежу за несколькими СМИ, они все разные, а заходить и читать на все 50 сайтов, ежедневно - не с руки, а подписываться на их рассылки, чтобы потом разгребать почту тем более. Пожиралось огромное количество времени. По этому пришлось придумать какой-то облегчённый механизм получения новостей для их оперативного мониторинга.
Я знаю, многие сначала посоветуют мне использовать таких ветеранов ПО как Mozilla Thunderbird или FeedBurner (который уже недоступен для РФ), но доступ к информации мне нужен на всех устройствах, на ноутбуке, на ПК, в телефоне и для такой простой вещи не хочется использовать какие-то отдельные приложения занимать мусором память и так далее. И начал я шерстить способы возможной реализации с помощью уже имеющихся у меня решений. Например, было бы очень удобно иметь бота в Telegram, уже готового. Чтобы не кодить самому. Всё что находилось в Телеграм уже не работало.
Перейдем к сути.
В конечном счете я нашел просто бота в Telegram, который просто принимает ссылку на RSS/Atom Фид. Хоть что-то. Бот не мой и это не реклама, а совет.
В одном из чатов в Telegram, мне посоветовали сервис под названием RSS Hub с виду ничем непримечательный сервис. Не сразу понимаешь что он умеет, но если почитать документацию, сразу понимаешь масштабность его функционала.
RSS Hub предлагает преобразовать уведомления или ленту новостей, практически в любой социальной сети у любого пользователя (но наверное кроме тех, кто приватит свой контент) в RSS Фид, а потом использовать его в своих агрегаторах RSS типа нашего бота. Ну так вот, поскольку у меня списке СМИ могут не иметь своего сайта, а просто вести канал на Youtube или Telegram, то мне такой сервис очень под руку.
Третий инструмент который мне очень облегчил жизнь, это расширение в браузере Google Chrome Get RSS Feed Url, я его установил и забыл, активирую только на сайтах СМИ чтобы получить из них ссылку на RSS. Потому что эти сайты её зачастую прячут.
Что я сделал?
1. Запустил бота RSS в Telegram, отключил в нем звук и поставил автоудаление на 3 дня. Т.е. бот соберет все новости, и будет хранить 3 дня, потом автоматически удалит сообщение и так каждый день. С помощью настроек бота можно настроить отображение этих новостей, превью или без, с описанием и заголовком или без. Я сделал так, чтобы у меня были просто ссылки с названиями статей. Названия статей порой максимально кликбейтные, но со временем вырабатывается слепота к этому и ты практически по кликбейту понимаешь суть статьи.
2. Закинул боту все ссылки на RSS ФИДЫ с сайтов СМИ, который собрал с помощью плагина Get Rss Feed Url.
Уже что-то. Теперь вы спросите, а зачем тут RSS Hub?
А дело в том, что мой Telegram аккаунт забит всякими каналами. Каждый канал нужно открыть отдельно чтобы, что-то прочитать, таков Telegram ничего не поделаешь. Знаю что там можно перелистываться с канала на канал когда дочитываешь все новости, но я не из таких. Я решил использовать RSS Feed чтобы получать новости с таких Telegram каналов в боте. Благодаря тому что все новости с этих Telegram каналов стекаются в тот же новостной бот, я могу отписаться от канала и почистить визуально свой Telegram сконцентрировавшись на общении.
Думать особо ненадо. Берите эту ссылку https://rsshub.app/telegram/channel/ЛОГИН_КАНАЛА , где вместо ЛОГИН_КАНАЛА вставьте Telegram логин того канала, из которого хотите извлечь новости. Например как в примере: https://rsshub.app/telegram/channel/awesomeDIYgod, где awesomeDIYgod это логин канала в который вы можете перейти по ссылке https://t.me/awesomeDIYgod.
Я так собрал все каналы, блоггеров на которых я подписан подготовил ссылки и закинул в RSS бот. А от самих каналов и блоггеров отписался. Результат - меньше визуального мусора, больше концентрации и свободы.
Если к ссылке добавить https://rsshub.app/telegram/channel/ЛОГИН_КАНАЛА/searchQuery... и закинуть такую ссылку в RSS бот, то в боте вы будете получать только те новости с этого канала, в которых имеются указанные вами ключевые слова.
Есть возможность также подписаться за новостями на Youtube каналах, Instagram аккаунтах (если они открыты) - не подписываясь на сами аккаунты. И видеть все-все новости в одном едином месте.
Таким образом я оперативно получаю множество интересующих меня новостей, не подписываясь на каналы или рассылки, не регистрируясь на сайтах. В одном месте. Без всяких доп приложений и это совершенно бесплатно.
Этот инструмент подойдёт тем, кто не умеет кодить, кто готов воспользоваться готовыми инструментами и ищет такой же способ агрегации фидов в единый RSS поток.
помощью какой программы можно сохранять RSS-ленту в формате PDF на диске в автоматическом режиме.
Допустим есть RSS-Лента:
https://habr.com/ru/rss/news/
Как сделать так чтоб, как только появляется статья она автоматически вся скачивалась (со всеми изображениями) и сохранялась в формате PDF на диске в заранее указанной папке?
Сейчас читаю статьи с помощью Thunderbird, но там такой функции не нашел.
Понадобилось мне получать с Хабра ленту комментариев пользователя в каком-то удобном виде, чтобы не заходить периодически на сайт для проверки её обновления. Очевидное решение — RSS.
В базе Хабр позволяет подписаться на профиль пользователя, или, по RSS, на ленту его публикаций. А вот для комментариев подобной возможности не предусмотрено (сама лента комментариев имеет вид https://habr.com/ru/users/user-name/comments/).
Первая мысль — воспользоваться Yahoo Pipes, ведь когда-то уже использовал его для решения подобных задач. Увы — оказалось, что сервис давно закрыт. Помолчим минуту (он был хорош!) и рассмотрим доступные альтернативы.
Интернет предлагает несколько бесплатных (или имеющих бесплатные тарифные планы) вариантов, например:
- IFTTT — слишком абстрактно для моей задачи (первым шагом надо выбрать сервис, для которого у них есть готовые наборы правил обработки), плюс сразу предлагают привязать карту (для активации триала, хотя на стартовой странице обозначен и free plan). И свой триггер можно добавить только к сервису, с которым у IFTTT уже есть интеграция.- pipe2py — предлагается разворачивать в Google App Engine, для чего нужно привязать карту, а сделать это в данный момент непросто. Слишком сложно для «просто попробовать и сравнить».
- Zapier — идеалогически похож на IFTTT — тоже надо выбирать готовое «приложение», которое уже есть в сервисе. Это не решение моей задачи.
- dlvr — тут всё понятно из их самопрезентации — Automate Social Media Posting — полностью мимо.
- Huginn — наконец — наш сегодняшний герой. Автономный (поддерживает локальное развертывание), гибкий (даже готовых обработчиков хватит для многого), скромный (в части интерфейса по сравнению с вышеперечисленными). Надо пробовать!
Сразу отмечу, что ни одно из приведённых решений (даже Huginn) не является аналогом Pipes, который был удобен своей возможностью комбинировать «блочную сборку» с тонкой настройкой алгоритма работы блока (если это требовалось).
Самый простой вариант развертывания Huginn с целью ознакомления — использование готового docker-контейнера. Исчерпывающая инструкция приводится на соответствующей справочной странице, добавлю к ней пару пару моментов, касающихся вариантов развертывания контейнера.
При локальной установке имеет смысл примонтировать хранилище в отдельный том (или каталог в хост-системе), который нужно предварительно создать: docker volume create huginn-mysql. А также — примонтировать .gitignore следующего содержания:
[safe]directory = /app
чтобы избежать лишней «ругани» в логах (при развертывании контейнера идёт обновление сабмодулей из репозитория).
После чего можно создать контейнер (на первый раз — с перенаправлением вывода контейнера в консоль):
docker run -it -p 3000:3000 -v huginn-mysql:/var/lib/mysql \ --mount type=bind,source="${HOME}"/dev/docker/gitconfig,target="/app/.gitconfig" \ --name huginn huginn/huginn
и в дальнейшем запускать его через docker start huginn.
Среди доступных в настоящий момент сервисов, предлагающих бесплатные ресурсы для развертывания приложения, GitHub Godespaces — один из немногих. Что немаловажно — в нём можно просто развернуть контейнер docker, без необходимости писать сборочные скрипты. Кстати, доступны весьма неплохие, для бесплатного предложения, варианты машин.
Достаточно в панели управления выбрать шаблон Blank, дождаться запуска сервиса, и в открывшейся консоли запустить докер: docker run -it -p 3000:3000 huginn/huginn.
Порты пробрасываются автоматически, после запуска приложение можно открыть в браузере (логин/пароль по умолчанию: admin / password). Чтобы приложение было доступно «извне», а не только внутри аккаунта github, нужно переставить порт на Public (правой кнопкой на Private -> Видимость порта -> Public).
Настало время перейти к главному — тому, ради чего всё затевалось — преобразованию страницы Хабра в RSS.
В простейшем случае — достаточно комбинации трёх агентов (так называются обработчики в Huginn), а именно:
- Website Agent — для получения исходных данных (страницы ленты) с сайта.- Event Formatting Agent — для подготовки (очистки) полученных данных.
- Data Output Agent — вывод результата в RSS (xml) и json. Но сначала стоит добавить новый сценарий, в котором эти агенты будут сгруппированы: Scenarios -> New scenario. На открывшейся после создания нового сценария странице можно смело жать New agent. Настройки агентов достаточно подробно документированы на странице их создания.
Website AgentВыбрать тип Website Agent, дать ему произвольное название, добавить его к созданному сценарию, затем, в разделе Options, переключить вид настроек (Toggle View) и вставить туда код агента (не забудьте в ссылке поменять user-1 на интересующего вас автора).
{ "url": "https://habr.com/ru/users/user-1/comments/", "mode": "on_change", "expected_update_period_in_days": "30", "extract": { "url": { "css": "a.tm-comment-footer__button", "value": "@HREF" }, "title": { "css": "a.tm-user-comments__header-link", "value": "string(.)" }, "body_text": { "css": "div.tm-comment__body-content", "value": "./node()" }, "publish_date": { "css": "a.tm-article-comment__link", "value": "string(.)" }, "author": { "css": "a.tm-user-info__username.router-link-active", "value": "string(.)" } } }
Проверить работу агента можно, запустив режим Dry Run. Если всё нормально — откроется вкладка Events с результатами, в случае проблем — подробности будут на вкладке Log.
Аналогично — добавить новый агент соответствующего типа, вставить код, в качестве источника данных указать созданный на прошлом шаге Website Agent (выбрать по названию в выпадашке).
{ "instructions": { "message": "<p>{{body_text}}<\/p>", "published": { "date": "{{pretty_date.date}}", "time": "{{pretty_date.time}}", "raw_date": "{{publish_date | lstrip | rstrip}}" }, "author": "{{author | lstrip | rstrip}}", "link": "https://habr.com{{url}}", "title": "{{title}}" }, "matchers": [ { "path": "{{publish_date | lstrip | rstrip}}", "regexp": "(?<date>\\d{2}\\.\\d{2}\\.\\d{4})\\s.\\s(?<time>\\d{2}:\\d{2})", "to": "pretty_date" } ], "mode": "clean" }
Для проверки работы этого агента — перед запуском Dry Run необходимо однократно запустить (Run) агент предыдущего шага, чтобы сгенерировать подлежащие обработке события.
Наконец, последний в этой цепочке — Data Output Agent, предназначенный для генерации RSS/JSON фида. Создается тем же способом, источником данных для него служит Event Formatting Agent с прошлого шага. Код агента:
{ "secrets": [ "habr-ucf" ], "expected_receive_period_in_days": "1", "template": { "title": "Habr comments feed", "description": "Comments feed of Habr user", "item": { "title": "{{title}}", "description": "{{message}}", "link": "{{link}}", "pubDate": "{{published.date}} {{published.time}}", "dc:creator": "{{author}}" }, "language": "ru" }, "ns_media": "true" }
secrets здесь содержит уникальную часть url-адреса будущего фида.
Наконец — можно запустить Website Agent и дождаться прохождения событий по цепочке агентов (это происходит в пределах минуты-другой, также есть возможность вызвать принудительное распространение событий).
Адреса фидов можно найти на вкладке Summary агента Data Output Agent.
Если видимость проброшенного порта объявлена, как Public — на ленту можно подписаться, не логинясь в аккаунт Github.
Чтение ленты комментариев одного пользователя — это уже неплохо. Но что делать, если есть потребность читать нескольких? Здесь также возможны варианты:
- Простой вариант — скопировать всю цепочку агентов. Можно даже в отдельный сценарий, ещё проще — экспортировать существующий сценарий, переименовать его и агенты (в полученном при экспорте файле), затем — импортировать обратно в Huginn. Поменять ссылку-источник на нужную, пользоваться. Минусы — игнорирование DRY, повышается нагрузка приложение. Ленты разных пользователей (источников) сливаются в одну общую, которой в дальнейшем неудобно пользоваться. Захламляется пространство сценариев. Плюсы — крайне просто реализуется, отключить ставшую ненужной ленту можно через управление сценарием.- Сбалансированный вариант (на нём остановлюсь подробней) — создать источники данных для разных ссылок, после обработки — разделить поток на отдельные для каждого источника ленты . Минусы — тот же DRY, чуть сложней в реализации. Плюсы — при необходимости можно добавлять источники в виде Website Agent простым клонированием самого агента с подстановкой в ссылку имени интересующего пользователя. В отсутствие необходимости в источнике — можно просто отключить соответствующий Website Agent.
- Экономичный вариант — использовать один общий Website Agent для нескольких ссылок. Минус этого варианта — для добавления/отключения источников надо или редактировать настройки Website Agent, или выключать агенты-потребители ниже по цепочке (при этом сохранятся запросы уже не нужных страниц). Плюс — не приходится создавать «лишние» агенты, реализуется такой вариант несложно (на базе второго). Код ссылок-источников будет выглядеть следующим образом:
"url": [ "https://habr.com/ru/users/user-1/comments/", "https://habr.com/ru/users/user-2/comments/" ],
На время опытной эксплуатации (пока Huginn у меня работает в развёрнутом локально контейнере) я остановился на варианте 2. Подробно расписывать его реализацию не буду, скажу лишь, что в цепочку добавляются Trigger Agent для разбивки ленты на отдельные потоки по авторам.
Готовый сценарий с набором агентов для второго варианта привожу в виде ссылки на Github. Имена целевых авторов хранятся в Credentials.
При развертывании Huginn на хостинге — планирую перейти на третий вариант формирования лент (с некоторыми доработками — чтобы список ссылок создавался на основе тех же Credentials). Приятного (и полезного) оHuginnения!
Kerbal Space Program (с англ. — «Космическая программа Кербалов»; сокр. KSP) — компьютерная игра в жанре космический симулятор, разработанная и изданная компанией Squad. Игра относится к жанру подлинных космических симуляторов, продолжая реализм таких игр, как Apollo 18: Mission to the Moon и Microsoft Space Simulator
Давным-давно я написал два поста:
Как я пытался посадить БИБ-1Л на Луну
Как я пытался посадить БИБ-1М на Марс
В этой серии постов я рассказывал как я сажал дроны на различные космические тела, однако с тех пор минуло два года и я решил, что нужно медленно "возродить" это, по крайней мере для себя.
Итак, я собрал маленькую сборку основанную на RSS, но без гиперреализма. С чего начать? Конечно начать стоит с вывода на орбиту спутников для сканирования территории и связи. Однако, первые два запуска остались за кадром (ниже гифки с пролётом этого спутника) - спутник-пробник связи и спутник для сканирования биомов и составления визуальной карты был выведен без особых проблем, однако я забыл вывести спутник для составления высотной карты в высоком разрешении, что и привело к созданию ещё одной ракеты.


Начинка ракеты состоит из:
Основного груза, а именно - спутник для сканирования высот Земли и дополнительно маленького зонда ретранслятора, который может помочь в последующем освоении космоса.
Немного о ракете:
Вес: 1,597,437 т;
Высота: 56,3 м;
Ширина: 13,1 м;
Длина: 13,1 м.

Два выводимых спутника:

Итак, выводить будем на полярную орбиту на высоту +-7,500 км над уровнем моря для сканирования всей планеты, а значит нам придётся потратить больше ΔV, однако у меня есть большой запас - порядка 2000-3000, чего должно с избытком хватить.
Ракета на старте и готова! Старт!

Успешная отстыковка первой ступени!

Работа над выходом на орбиту!

За кадром осталось: отделение ступени и сброс обтекателей.
Конечная стадия вывода на орбиту основного спутника для сканирования!

Итак! Основной спутник остаётся на орбите +-7,500 км, а далее следует дополнительная задача - вывод маленького спутника-ретранслятора на более высокую орбиту и проверка его работоспособности.
Работа двигателя спутника связи:

Вот и всё! Ступень для вывода на орбиту отделена и теперь маленький связной навсегда останется на орбите Земли и в дальнейшем может быть будет помогать мне, но что самое главное - стало понятно, что такой маленький спутник хорошо выполняет свои задачи.

Итак, миссия под названием: "АБОБ-1О" успешно завершена!
Спасибо, что прочитали пост :)
(Большая орбита - спутник связи, меньшая в той же плоскости - спутник сканирования)
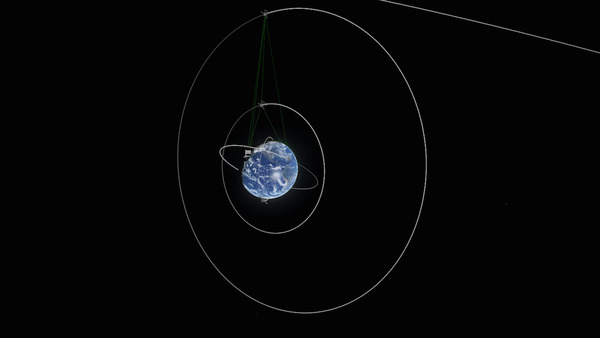
Пост написан в развлекательных целях и не несёт большой смысловой нагрузки, задачи придуманы самим собой для самого себя.
Конкурс мемов объявляется открытым!
Выкручивайте остроумие на максимум и придумайте надпись для стикера из шаблонов ниже. Лучшие идеи войдут в стикерпак, а их авторы получат полугодовую подписку на сервис «Пакет».
Кто сделал и отправил мемас на конкурс — молодец! Результаты конкурса мы объявим уже 3 мая, поделимся лучшими шутками по мнению жюри и ссылкой на стикерпак в телеграме. Полные правила конкурса.
А пока предлагаем посмотреть видео, из которых мы сделали шаблоны для мемов. В главной роли Валентин Выгодный и «Пакет» от Х5 — сервис для выгодных покупок в «Пятёрочке» и «Перекрёстке».
Реклама ООО «Корпоративный центр ИКС 5», ИНН: 7728632689






