Кажется, что рекомендательный движок музыкального сервиса - это черный ящик. Берет кучу данных на входе, выплевывает идеальную подборку лично для вас на выходе. В целом это и правда так, но что конкретно делают алгоритмы в недрах музыкальных рекомендаций? Разберем основные подходы и техники, иллюстрируя их конкретными примерами.
Начнем с того, что современные музыкальные сервисы не просто так называются стриминговыми. Одна из их ключевых способностей - это выдавать бесконечный поток (stream) треков. А значит, список рекомендаций должен пополняться новыми композициями и никогда не заканчиваться. Нет, безусловно, собственноручно найти свои любимые песни и слушать их тоже никто не запрещает. Но задача стримингов именно в том, чтобы помочь юзеру не потеряться среди миллионов треков. Ведь прослушать такое количество композиций самостоятельно просто физически нереально!
Так как они это делают?
Если ваши музыкальные алгоритмы не похожи на это, то даже не предлагайте мне скачивать приложение!
Чтобы сделать годную рекомендацию, сервису нужны три сита…
Первое сито - это так называемые рекомендации на основе знаний (knowledge-based). Это значит, что сервис аккумулирует всю доступную информацию об одном пользователе - что он слушает (например, каких артистов или жанр), как часто, что лайкает, что дослушивает, что проматывает дальше и т.д. Учитываются сотни или даже тысячи факторов. Разумеется, собираемые данные анонимны.
После этого сервис делает рекомендацию. Причем она может даваться безотносительно общих предметных знаний сервиса. Например, если мы видим, что Вася добавил в плейлист Metallica “Nothing Else Matters”, то с большой вероятностью ему понравится и “Unforgiven”. Для такого вывода нам не нужна дополнительная информация.
Помимо прочего, рекомендации на основе знаний помогают решить проблему “холодного старта” (это когда свеженький и тепленький юзер только-только зарегался), предлагая новому пользователю тот контент, который соответствует его требованиям с самого начала использования.
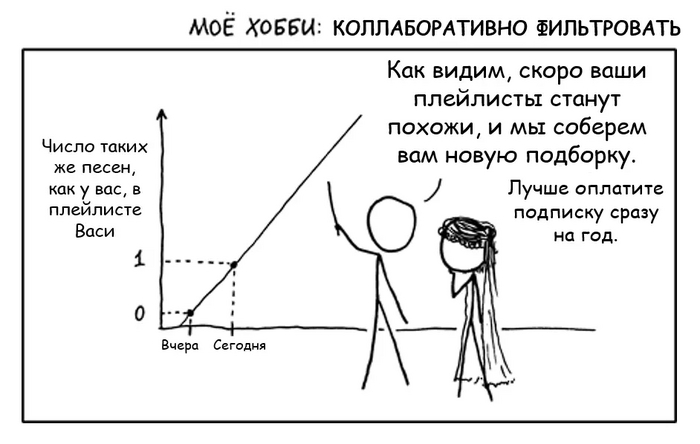
Второе сито - коллаборативная фильтрация. Пожалуй, это самый главный прием и краеугольный камень любого стриминга. Хотя коллаборативная фильтрация и может издалека походить на анализ предпочтений пользователей, на самом деле это совсем другая техника и технология - гораздо более продвинутая и математически точная.
Работает она на следующем допущении:
Пользователи, которые одинаково оценили какие-либо композиции в прошлом, склонны давать похожие оценки другим композициям в будущем.
Давайте разберем на примере, очень упрощенно:
Допустим, у Васи затерты до дыр треки:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Scooter “How much is the fish?”
Валерий Леонтьев “Мой дельтаплан”
Какую закономерность можно выявить на основе этого набора? Да никакую. Просто мешанина из разных жанров, артистов и эпох.
Тем не менее, у сервиса также есть пользователь Петя, чей плейлист по удивительному совпадению похож на Васин, а именно:
Metallica “Nothing Else Matters”
Skrillex “Kyoto”
Dua Lipa “Swan Song’’
Валерий Леонтьев “Мой дельтаплан”
Все треки одинаковые, кроме одного. У Васи это Scooter, у Пети - Dua Lipa.
По логике коллаборативной фильтрации, есть вероятность, что если Вася и Петя “обменяются” этими песнями, то обоим понравится. Поэтому такие рекомендации и называются “коллаборативными” - пользователи как бы сотрудничают, обмениваясь предпочтениями друг с другом.
Коллаборативная фильтрация in a nutshell.
Понятное дело, что коллаборативная фильтрация работает не на двух пользователях, и даже не на двух тысячах. А вот на паре миллионов юзеров, у которых удается найти критическую массу одинаковых композиций - уже вполне. Также очевидно, что я привожу примеры карикатурно непохожих песен “из разных миров”. Я это делаю намеренно, чтобы подчеркнуть, что подход помогает делать рекомендации на основе данных, в которых, казалось бы, не за что зацепиться в поисках общего паттерна. Понятное дело, что в реальности между прослушанными и рекомендуемыми треками скорее всего будет больше схожести.
Так почему этот способ дает хороший результат, когда между наборами треков может не быть ничего общего?
Ну смотрите. Музыкальные предпочтения зависят от целого множества факторов - ваш вкус в целом, ваше настроение сегодня, работаете вы или же чиллите, болит ли у вас голова, с какой ноги вы сегодня встали, что конкретно на завтрак ели и многое-многое другое. Запихивать все эти переменные в строгое правило с четкими “если Х, то У” - дело неблагодарное. А вот если ИИ эмпирически прошерстит огромную выборку и найдет в ней похожие участки, то это совсем другое дело.
Здесь примерно та же логика, по которой если нейросетке скормить кучу картинок с котиками, а потом попросить её нарисовать котика, то она скорее всего изобразит туловище, к которому будут приделаны 4 лапы, хвост, шерсть и мордочка с усами и треугольными ушками. То есть нюансы изображения могут различаться, но основные свойства котика (назовем их “котиковость”) будут переданы. А значит, концептуально результат будет верный.
Так же и с рекомендациями в рамках коллаборативной фильтрации. Разве можно рационально объяснить, почему одна группа любителей Slipknot вдруг слушает песни Димы Билана (наверно, чтобы вкус перебить, такой себе имбирь между разными роллами), а другая группа - Леди Гагу? Вряд ли. Однако, если такие два паттерна существуют, то это значит, что слушающим Леди Гагу металлистам можно попробовать включить Билана, а их визави, наоборот, протолкнуть в поток Poker Face или Alejandro. Ведь точный эмпирический анализ большой выборки попадает в яблочко как минимум очень часто.
Наконец, третье сито, которое отлично дополняет первые два. Это рекомендации на основе контента (content-based). Здесь уже анализируется непосредственно сама композиция. Сервис берет песню, разбивает её на куски, отрезки или даже отдельные “квадраты”, после чего анализирует каждый отдельный элемент звука и ищет песни, технически похожие на анализируемую. Есть вероятность, что если Васе нравится песня Х с определенным звучанием и ритмом, то ему понравится и песня Y с похожими музыкальными свойствами.
Здесь есть важный нюанс. Звучание песни анализирует машина по каким-то техническим критериям, которые понятны ей, машине. А вот мы, люди, можем кайфовать от песни иррационально. Например, не только благодаря ритму мелодии, аранжировке или тембру голоса исполнителя, а еще и благодаря вайбу композиции, а то и символическому капиталу вокруг неё (например, если песня культовая или просто трендовая и модная-молодежная).
Поэтому, content-based рекомендации не всегда дают хороший эффект сами по себе, но служат отличным дополнением других способов фильтрации.
Также, такой способ - рабочий вариант для так называемых “холодных треков”. Это композиции, которые только-только выложили на стриминг. Допустим, новая песня известного исполнителя, либо же неизвестный трек совсем нового певца-ноунейма, которому тоже хочется славы. В таком случае плясать от самой композиции - полезное умение. Ведь трека еще нет в плейлистах тысяч и миллионов пользователей, а значит, порекомендовать его с помощью коллаборативной фильтрации или через knowledge-based вряд ли получится.
Резюмирую принципы рекомендательных движков музыкальных стримингов с помощью классического мема.
Итак, мы разобрали три основных техники, с помощью которых стриминги рекомендуют звуковой контент нашим ушкам. Разумеется, современные продвинутые сервисы обычно используют их все (получаются “гибридные рекомендации”), прикручивая к каждому из них свои авторские фишки.
Как конкретно это работает. Разбираю на примере гибридного подхода Яндекс Музыки
Теперь предлагаю показать на практике, как конкретно описанные выше техники работают. Для иллюстрации я буду использовать пример Яндекс Музыки. Потому что сам давно пользуюсь этим сервисом (думаю, уже лет 10), а также по той причине, что недавно у них прошло большое обновление алгоритма, которое внесло важные изменения в механизм рекомендаций. Ну и еще потому что всегда приятнее разбирать глобальные лучшие практики на отечественном сервисе, который в полной мере им соответствует.
Итак:
Базово рекомендательный движок Яндекс Музыки реализован через Мою волну, которая появилась на главной странице сервиса пару-тройку лет назад. По умолчанию этот поток сбалансированный - это значит, что он комбинирует любимые и привычные треки (которые пользователь и так активно слушает) с новыми композициями, причем в комфортной пропорции. По своему опыту скажу, что микс между добавленными и новыми треками по умолчанию примерно 50:50. При этом 30-40% новых я лайкаю, чтобы сохранить к себе. За счет этого алгоритм дообучается и адаптируется.
Однако Мою волну можно дополнительно кастомизировать через настройки. Нажимаем кнопку под плеером и проваливаемся вот в такое меню.
Как видим, параметров кастомизации вроде бы немного, но при этом изменения могут быть весьма существенными. К тому же, из скриншота видно, что настройки потока можно включать и отключать в разных комбинациях. Используя свои знания наивысшей математики, я перемножил 5 (Занятия) на 3 (Характер) на 4 (Настроение) и на 3 (Языки) и получил примерно 180. Ну ладно, пришлось использовать калькулятор, подловили…
Так что, внутри одной Моей волны на самом деле сидят очень много разных Моих волн.
Остановимся детальнее на настройке под названием “Характер”. Можно попросить движок делать больше акцента на моих залайканных треках (“Любимое”), или же наоборот чуть абстрагироваться от знаний о пользователе и поддаться общим трендам (“Популярное”).
Но поскольку статья все же о рекомендательном функционале, то остановимся подробнее на настройке “Незнакомое”. Ведь именно глядя на способность подбирать релевантные треки из всего внешнего многообразия можно оценить движок. Итак, если включить “Незнакомое”, то алгоритм сделает серьезный крен в сторону ранее незнакомых композиций.
Кстати, недавнее обновление касалось именно этой настройки. “Незнакомое” получила новый ранжирующий алгоритм, благодаря чему стала более смело предлагать новые композиции, которые, тем не менее, должны соответствовать музыкальным вкусам пользователя.
С обновленной настройкой юзер получает новый аудиоконтент, при этом не ощущая особенно сильных скачков и перепадов. То есть, даже если алгоритм решит выйти за пределы рекомендационного пузыря, дабы расширить музыкальные горизонты пользователя, то он все равно будет оставаться в рамках его предпочтений и смежных жанров. Проще говоря, несмотря на экспериментирование, подбрасывание неактуальной музыки будет сведено к минимуму.
Уважаемые газеты пишут, что теперь пользователи сервиса добавляют к себе в “Коллекцию” примерно на 20% больше новых треков. Для артистов (в том числе молодых и начинающих) это тоже важный ништяк, поскольку повышается вероятность, что их творчество распространится и взлетит среди новой аудитории.
Так вот, для поиска этих самых новых композиций сервис как раз и применяет гибридный подход, объединяющий коллаборативную фильтрацию, анализ контента и фильтрацию на основе знаний о пользователе. Поговорим о нем детальнее.
Начнем с пользователя
Для начала, машина кушает все “долгосрочные” (очень условно их так назову, дорогие технари, не ругайтесь) данные о пользователе. Какие жанры и исполнителей он указывал как любимых, когда регистрировался? Что у него лежит в плейлисте? Что там лежит давно, а что недавно? Что удалялось? Что из лежащего давно он слушает регулярно или иногда, а что лежит мертвым балластом? И еще 100500 факторов и паттернов.
На эти “долгосрочные” знания о юзере накладываются конкретные действия.
Например, обычно Вася слушает треки в одной последовательности, а вчера решил включить в другой. Алгоритм тоже это примет к сведению. Возможно, учтет сразу, а, может быть, посмотрит на динамику последовательности при парочке ближайших использований (кто ж знает, как эта “черная коробка” решит там у себя внутри).
Не забываем, что алгоритмом все-таки заведует продвинутая ML-моделька, которая любит сама себя дообучать и всячески развивать. Так что, хотя человеки и знают принципы её мироустройства, точно предсказать результаты из “черного ящика” решительно нельзя.
Разумеется, движок учитывает, дослушал ли песню наш лирический герой, смахнул её или вовсе влепил ей лайк.
Далее - анализ контента
Вторая составляющая годной рекомендации - это анализ самой композиции. Для этого сервис преобразует трек в специальный формат - цифровой аудиовектор.
Для этого сервис разворачивает трек во времени и раскладывает его на частотные диапазоны, получая спектрограмму. Она передается специальной аудиомодели с нейросетью-энкодером, которая сворачивает спектрограмму в аудиовектор, или аудиоэмбеддинг (это когда сервис прячет в аудиофайле специальные метки - о песне, исполнителе, жанре и т.д.).
У похожих по звучанию треков такие векторы расположены близко друг к другу в многомерном векторном пространстве. У разных треков, соответственно, наоборот.
За счет таких манипуляций алгоритм может разложить трек буквально на атомы, чтобы потом сравнить каждую “элементарную музыкальную частицу” с аналогичными частицами других композиций.
Алгоритм сервиса преобразует трек в аудиовектор, расщепляя его на мельчайшие музыкальные элементы, чтобы проанализировать каждый из них. Вижу так.
Этот прием дополнительно повышает точность рекомендаций.
Наконец, коллаборативная фильтрация
Залезть в глубинные сущности этой техники конкретного сервиса непросто. Но каждый уважающий себя продвинутый стриминг старается довести эту технологию до высокого уровня.
За основу берется принцип, который я описал в первой части статьи. Но реализуется он, само собой, на предпочтениях миллионов слушателей. Алгоритм анализирует обезличенные данные массы пользователей, после чего прогнозирует музыкальные интересы конкретного человека, добиваясь максимально точных попаданий. В основе всего этого движа лежит матрица взаимодействия, составленная из различных оценок пользователей. Если упрощенно, то это такая табличка (ооочень большая), где отображаются все взаимодействия юзера с сервисом. Потом с матрицей работают алгоритмы машинного обучения - они уже обрабатывают данные и передают их в обобщенную модель, которая и отвечает за рекомендации.
Три типа фильтрации в итоге объединяются в единый machine-learning алгоритм под названием CatBoost, который уже генерирует для каждого юзера персональную последовательность треков с учетом множества вышеописанных факторов.
В итоге в алгоритмическом магическом котле заваривается тот самый вуншпунш, который мы готовы потреблять ушами в течение часов и дней, поддерживая свой энергичный рабочий настрой, умиротворенный расслабленный вайб либо же вызывая внезапный эмоциональный порыв. Подчеркнуть нужное в зависимости от ваших текущих целей, настроения и самочувствия.
Теперь вы знаете чуть больше про рекомендательные системы стриминга, особенно музыкального. Надеюсь, было интересно и полезно. Есть что добавить или с чем поспорить? Пишите в комменты.
Если вам понравилось, то подписывайтесь на мои тг-каналы. На основном канале - Дизрапторе - я простым человечьим языком и с юмором разбираю разные интересные штуки из мира бизнеса, инноваций и технологических новшеств (а еще анонсирую все свои статьи, чтобы вы ничего не пропустили). А на втором канале под названием Фичизм я регулярно пишу про новые фичи и инновационные решения самых крутых компаний и стартапов.
Мы постарались сделать каждый город, с которого начинается еженедельный заед в нашей новой игре, по-настоящему уникальным. Оценить можно на странице совместной игры Torero и Пикабу.
AIVA- генерирует эмоциональные саундтреки с помощью нейронки. Свободно выбираете стиль, темп, настроение и количество композиций. Например, можно создать музыку lo-fi, hip-hop или для медитации.
Сначала алгоритмы создают трек, который можно полностью подстраивать под себя, менять ноты, аккорды. Немного потыкаете и поймёте, как всё работает.
Источник телеграм канал ИИшница 🍳 - тут все самое интересное из мира новых технологий и нейросетей 🤖
В пятницу увидел гору уведомлений из всех утюгов. Оказалось, Яндекс Музыка провела ребрендинг и кардинально обновила функционал. При этом есть стойкое ощущение, что несмотря на все обзоры, никто так нормально и не раскрыл самую мякотку этого обновления. В этой статье постараюсь это исправить (отдаю дань сервису, которым пользуюсь уже 10+ лет).
Я пользуюсь Яндекс Музыкой cо времен, когда Дуров еще не придумал Telegram, а Рокстары только-только выпустили пятую GTA. В общем, очень давно.
Когда я начинал пользоваться Яндекс Музыкой, она выглядела вот так на экране моего Сони Эрикссона. Ладно, это, конечно, шутка, но я действительно пользуюсь сервисом почти с самого запуска (а Яндекс Музыка и правда вот так респектовала Winamp).
Мне стало интересно, и я полез искать нормальный авторский разбор обновлений. Чтобы сразу все четко, по фактам и с кристаллизацией самой сути. И… не нашел его.
Так что, как говаривал Танос, опять все приходится делать самому.
Итак, сейчас разберемся, какие самые важные изменения произошли у одного из моих любимых сервисов. За что хочется особенно звонко респектнуть, а над чем, на мой взгляд, можно еще поработать.
Заодно попробуем ответить на главный вопрос: будем ли мы теперь работать еще продуктивнее благодаря сочному музону, улучшающему нашу концентрацию и работоспособность?
При этом, само собой, мы не просто перечислим ключевые нововведения (я же не обзорщик какой-то), а выделим самое важное, анализируя частное исходя из общей картины. Дедуктивно, то есть.
Но чтобы увидеть всю картинку целиком и сделать системный вывод, мы начнем немного издалека.
С чего начался музыкальный стриминг, и как он развивался - самое важное очень кратко
Чтобы понять, где в обновлении Яндекс Музыки спрятался тот самый алмаз, нужно сначала вспомнить суть музыкального стриминга в целом. Зачем вообще нужен стриминг, и почему именно стриминговые сервисы стали главным форматом потребления музыкального контента? Для этого вернемся на 20-25 лет назад, когда индустрия начала формироваться.
Если вы смотрели фильм “Социальная сеть”, то наверно помните Шона Паркера - персонажа в исполнении Джастина Тимберлейка, который стал партнером Цукерберга по кое-какой соцсети, которую мы тут не будем называть.
Вот этот чел, слева от киношного Цукерберга.
Так вот, до цукерберговской соцсети этот самый Паркер прославился как основатель сервиса Napster. Некоторые ресурсы называют его первым стримингом, но это не совсем так.
Napster - это просто программка, которая получала доступ к папкам с музыкой с компов других пользователей. По сути, обычный файлообменник, просто с фокусом на музыкальных файлах. Условный пользователь Джон сохранял свое любимое музло в какую-то папку и давал к ней доступ Напстеру. А пользователь Джейн могла эту папку скачать. И наоборот.
Кстати, Джон мог еще затролить Джейн, оборвав ей загрузку на 99%. Напстеру даже пришлось чуть пофиксить эту баг/фичу, а то у пользователей начинало подгорать, и они выливали негатив на сам сервис. Но в целом примерно так и работало.
У Napster была кое-какая рекомендательная система (очень простенькая, больше похожая на примитивный каталог), но до каких-то алгоритмов или бесшовного рекомендательного движка было еще далеко. Какой там движок - это же просто скачивалка пиратской музыки с компа на комп. Да и потока вещания как такого у Napster не было. Поэтому, собственно, это и не стриминг.
С первым же тру-стримингом чуть сложнее. Ряд источников пишет, что это сервис SonicNet, запущенный еще в далеком 1998 году (т.е. на год раньше Napster). И он уже был похож на современные сервисы по своей сути. Правда тогда говорили не “стриминг”, а “cybercast service”, т.е. сервис цифрового вещания. Широкой аудитории SonicNet не снискал, но начало было положено.
Еще через несколько лет начали рождаться популярные стриминговые площадки. Они то и дополнили легкий доступ к контенту и бесконечное потоковое вещание атрибутами, за которые мы и любим стриминги - в первую очередь, тематические подборки, и, конечно же, рекомендательные алгоритмы.
Массовый пользователь полюбил стриминг именно за качественные рекомендательные движки с высоким уровнем персонализации. Ведь пользователь не хочет напрягать мозг и делать лишние действия, он просто хочет потреблять актуальный для него продукт.
В последние годы случилась еще одна важная веха - компании стали выводить рекомендательные алгоритмы на новый уровень за счет искусственного интеллекта. В результате чего потребительская ценность и конкурентные особенности стриминговых сервисов еще сильнее сдвинулась в сторону персонализированных рекомендаций.
Я пользователь, и я не хочу ничего решать, я хочу слушать классную музыку!
Ретроспективу выше я расписал не просто так, а чтобы показать, что ценностное предложение музыкального стриминга, по сути, всегда сводилось к одной понятной потребности:
Максимально упростить доступ к прослушиванию музыки.
Это делал и Napster, и SonicNet, и более поздние игроки. Но по мере развития индустрии и технического прогресса эта потребность удовлетворялась все более продвинутыми и изощренными способами.
Итак, что такое годный музыкальный стриминг прямо сейчас? Предположу, что для массовых пользователей (к коим я без всякого стыда себя отношу) критически важны вот такие возможности сервиса:
Во-первых, давать легкий доступ к музыке без лишних усилий. Эту задачу вполне умели решать и Napster c SonicNet - разными способами и теми инструментами, которые тогда были доступны.
Во-вторых, воспроизводить длительный поток (в идеале - вообще бесконечный). Чтобы если мне захотелось слушать музыку долго и упорно, то сервис не написал “извините, плейлист кончился, будьте добрый поискать другой”. Для меня, как для пользователя, это доп действие и лишний напряг. А я не хочу ничего решать - я пользователь, у меня лапки. Вот это Napster уже не умел делать, т.к. был ограничен доступными файлами. Это умеет делать именно стриминг.
В третьих, моментально запускать именно ту аудиодорожку, которая мне нужна. Тут важно, что именно моментально - в идеале с помощью нажатия одной кнопки, на которой написано “включить нужный мне музон” (на нейминге не настаиваю). Причем этот аудиоконтент должен быть именно тем, который нужен мне. Не “самым популярным в мире”, и не тем, который нравится условной знаменитости или дяде Васе. А тот, который нравится мне. Это уже скилл действительно хороших стримингов с крутым рекомендательным движком. У Яндекс Музыки и раньше был функционал с подобными возможностями, но после внедрения фичи “Моя волна” два года назад скилл прокачался еще сильнее.
"Нужно делать как нужно, а как не нужно делать не нужно”, streaming edition. Шутки-шутками, но именно к этому сводится основной функционал любого популярного современного стриминга (причем не только музыкального).
Ну и наконец, последний пункт. Я, как представитель вида homo sapiens, подвержен развитию и едва заметному (но постоянному) эволюционированию. Мои музыкальные вкусы тоже меняются. Обычно, если я включаю музло, которое слушал лет 5-7 назад, то ко мне в гости стучится испанский стыд. Хотя, надо признать, иногда наоборот кайфую от ностальгии - для такого у Яндекс Музыки есть отличный инструмент “Тайник” (это обновляющийся плейлист из треков, которые вы активно слушали некоторое время назад). Так вот, мои вкусы не стоят на месте, а поэтому я хочу, чтобы умный алгоритмический движок стриминга менялся вместе со мной и предугадывал мои предпочтения. Как именно? Ну, это уже не ко мне вопрос. Пусть компания свои искусственный интеллекты и дип машин-лернинги внедряет. А я пользователь, у меня лапки, не забываем.
Выполнение последнего пункта возможно только тогда, когда сервис помогает пользователю найти баланс между захватывающей и манящей новизной и привычной и уютной стариной. Или, если более умными словами, способствовать балансу между неофобией (боязнью новизны) и неофилией (стремлению к новшествам). Этот конфликт сидит в душе каждого пользователя, и сервису нужно уметь с этим работать.
Некоторым меломанам еще жизненно-важно сверхкрутое качество аудиодорожки. Но мне на это пофиг - у меня наушники Сяоми, купленные еще до ковида за 4к руб., и мне вполне хватает. Как и подавляющему большинству пользователей.
А теперь разберемся - что же такого важного придумала Яндекс Музыка
Итак, если п.1-3 из раздела выше с разной степенью паршивости умеют делать все современные стриминги, то адаптация к изменениям музыкальных вкусов из п.4. - это высший пилотаж.
И, ИМХО, именно в этом главная ценность недавнего обновления Яндекс Музыки.
Нет, само собой, сервис в целом очень круто поработал с ультраперсонализацией. Они окончательно закрепили за системой персональных рекомендаций “Моя волна” статус главного и основного инструмента. Существенно прокачали её способность точно угадывать с рекомендациями за счет глубинных нейронных моделей. А также вывели именно эту дорожку на основной экран (как я говорил выше, теперь достаточно нажать одну кнопку, и в ухо польется релевантная музыка).
Но лично для меня главное даже не это. Самое ядерное нововведение - это способность “Моей волны” воспринимать контекст и понимать логику развития музыкальных вкусов. То есть теперь алгоритмы будут заточены не только на подбор треков, которые актуальны для вас прямо сейчас. Они будут предугадывать, что вам с большой вероятностью зайдет в ближайшем будущем (из того, что вы пока еще не слушаете). После чего движок будет потихоньку проталкивать такие новинки в вашу "Мою волну".
Причем ребята из Яндекс Музыки обещают, что это будет делаться не абы как, а аккуратно и дозированно, чтобы пользователь продолжал слушать именно “свою музыку”, а новизна завозилась потихоньку.
Таким образом, пользователь будет пропитываться новым, но не испугается перемен. Будет найден тот самый баланс между неофилией и неофобией (с небольшим перевесом в сторону неофилии, само собой).
Когда алгоритм закидывает непривычный для вашего уха трек в вашу персональную подборку. Здесь сервис постарается сделать так, чтобы костюмчик этого парня значимо отличался от окружения, но не "разъедал глаза" уж совсем.
Должен сказать, что это очень смелый заход от сервиса. Что ж, буду тестировать фичу - благо, работать в ближайшее время придется много, так что явно понадобится поток качественного музона для повышения производительности. Но сразу предупрежу разрабов из Яндекса: мои вкусы весьма специфичны, а векторы их развития бывают хаотичными, так что умной железяке Яндекс Музыки придется напрячься! Вот тогда и отвечу на главный вопрос из начала статьи. А заодно оценю, удастся ли сервису балансировать между захватывающим новым и уютным привычным (с небольшим сдвигом в сторону нового, само собой).
Кстати, выше я говорил исключительно о “спросе”, т.е. о пользовательских фичах. Но с обновлением “Моей волны” связан и важный нюанс со стороны “предложения” - кардинально меняется оффер Яндекс Музыки для артистов.
Поскольку рекомендательная система будет целенаправленно разнообразить выдачу, то начинающим музыкантам будет проще получить охваты. Более того, аудиомодель (это сам технологический движок сервиса, отвечающий за воспроизведение аудиодорожки) подточили таким образом, что в "Мою волну" теперь может попасть даже совсем новый исполнитель. Который буквально вчера залил свой первый трек на площадку.
Следовательно, абсолютно всем артистам на сервисе будет легче заиметь новых постоянных слушателей. А это уже значимый буст для всей национальной музыкальной индустрии. Который очень нужен прямо сейчас, когда многие зарубежные исполнители и лейблы изымают свою продукцию из российских сервисов.
Короче говоря, если последние годы Яндекс Музыка планомерно отходила от концепции каталога, но все же оставалась в первую очередь им (хотя и с высокой персонализацией и продвинутым рекомендательным движком), то с последним обновлением каталог окончательно уступил адаптивным персонализированным рекомендациям. И правильно - ведь каталоги имеют свойство устаревать и терять актуальность, не говоря уже о том, что требуют лишних усилий от юзера. Так зачем держаться за эту концепцию, когда умная ИИшечка теперь лучше самого пользователя знает, что нужно включать? Если дивный новый мир все-таки решил настать, то нужно брать от него лучшее.
Вишенкой на торте обновления стал редизайн. Теперь вместо красной “нотки” на эмблеме красуется желтая вспышка (или, как говорят сами ребята из Яндекс Музыки, “яркий импульс”), символизирующий воодушевление и эмоциональный подъем, с которыми мы сталкиваемся, когда начинаем слушать “тот самый” трек. Проще говоря, если алгоритм попадает в яблочко.
Было - стало. Думаю, правильно сделали, что отказались от “нотки”. Ноты, эквалайзеры, микрофоны и прочая музыкальная айдентика есть у всех музыкальных сервисов, но она не отражает главное преимущество. А вот импульс - очень даже.
Но это маркетинговая “лирика”, пусть и важная. А “физика” - она в способности сервиса удовлетворять потребность пользователя лучше конкурентов. И именно она интересует меня больше всего, ведь в первую очередь я продуктовый аналитик.
Если сервис может с высокой эффективностью лить мне в ушки треки, идеально подходящие под мои предпочтения, ситуацию, настроение и состояние души, то все остальное уходит на второй план. При таком раскладе становится не так уж критично, что из библиотеки убрали какие-то отдельные композиции конкретных артистов. Ведь ключевая ценность стриминга для меня все же не в них. Как и для большинства “обычных” пользователей.
Тем не менее, кое-чего мне в сервисе все же не хватает. Распишу основные пункты - вдруг прислушаются и зарелизят со следущими обновлениями:
Чего бы я еще хотел от своего музыкального стриминга (Яндекс Музыка, если вы меня читаете, то записывайте)
С вами рубрика “что в кайф сделайте, а что не в кайф не делайте” или “советы крупной корпорации от диванного эксперта”.
Итак:
Будет круто, если треки из Яндекс Музыки можно будет ставить на рингтон звонка и будильника. Яндекс, запилите раздел с рингтонами. Их даже можно продавать, либо же сделать доступ к ним доп фичей для усиления оффера Яндекс Плюса. Если рингтоны будут в отдельном разделе, то юзабилити сервиса это не испортит. Впрочем, я не уверен в технической возможности сделать такую штуку (если кто знает, просветите меня в комментах).
У Яндекса, как известно, есть такси-агрегатор. Приезжает к вам водитель, который любит слушать свой музон (не шансон и блатные романсы, а что-то более прогрессивное, допустим). А у вас в Яндекс Музыке уже есть свой плейлист. Вы нажимаете на кнопку в приложении Яндекс Такси, и сервис делает усредненный плейлист из ваших предпочтений и предпочтений таксиста. Не ставит таксисту вашу музыку, которая ему может совсем не нравиться (зачем тогда мучить человека?), а именно усредненный, который понравится обоим слушателям. В итоге все довольны, а вы с уважаемым водителем теперь можете дружить семьями. Профит!
Тот момент, когда алгоритм смэтчил в предпочтениях Хадн Дадн и Мурата Тхагалегова.
Я использую музыкальный стриминг Яндекса не только для, собственно, Музыки. Я еще слушаю там подкасты. Понимаю, что сделать сугубо рекомендательный сервис для подкастов непросто, но можно попробовать внедрить отдельные продвинутые элементы. Например, можно с помощью ИИ делать краткие выжимки некоторых крутых подкастов, и периодически просовывать их между моей подкаст-библиотекой (разумеется, чтобы сразу после прослушивания выжимки я мог через одну кнопку провалиться в её полную версию). Особенно круто, если внутри выжимки подсвечивать, что нового я узнаю, и какие новые скиллы приобрету.
Уверен, у вас еще есть крутые предложения потенциальных фич и пользовательских примочек. Предлагаю накидать их в комментах.
Если вам понравился разбор, то заглядывайте на мой канал Дизраптор. Там я регулярно докапываюсь до сути новых продуктов, бизнес-моделей и инноваций понятным человечьим языком и с юмором.