Go и Горутины
Горутины в языке программирования Go — это легковесные потоки, используемые для выполнения функций параллельно с другими горутинами в одном и том же адресном пространстве процесса. Горутины являются одной из ключевых особенностей Go и предоставляют очень эффективный способ для обработки параллельных задач и асинхронного выполнения.
Легковесность
Горутины очень легковесны по сравнению с традиционными потоками. Создание горутины требует всего несколько килобайт стека, который может увеличиваться и уменьшаться по мере необходимости. Это позволяет создавать тысячи и даже миллионы горутин в одном приложении без значительного потребления ресурсов.
Мультиплексирование на меньшем количестве ОС потоков
Горутины мультиплексируются на меньшем количестве потоков операционной системы. Это значит, что даже при блокировке одной горутины (например, при ожидании ввода/вывода), другие горутины продолжат выполняться на других потоках ОС, что обеспечивает высокую производительность и эффективность использования ресурсов.
Планировщик
Go имеет свой встроенный планировщик, который распределяет горутины по доступным потокам операционной системы. Планировщик использует механизм M:N, где M горутин мультиплексируются на N потоков операционной системы. Планировщик Go работает на уровне пользовательского пространства и оптимизирован для работы с большим количеством горутин.
Синхронизация и коммуникация
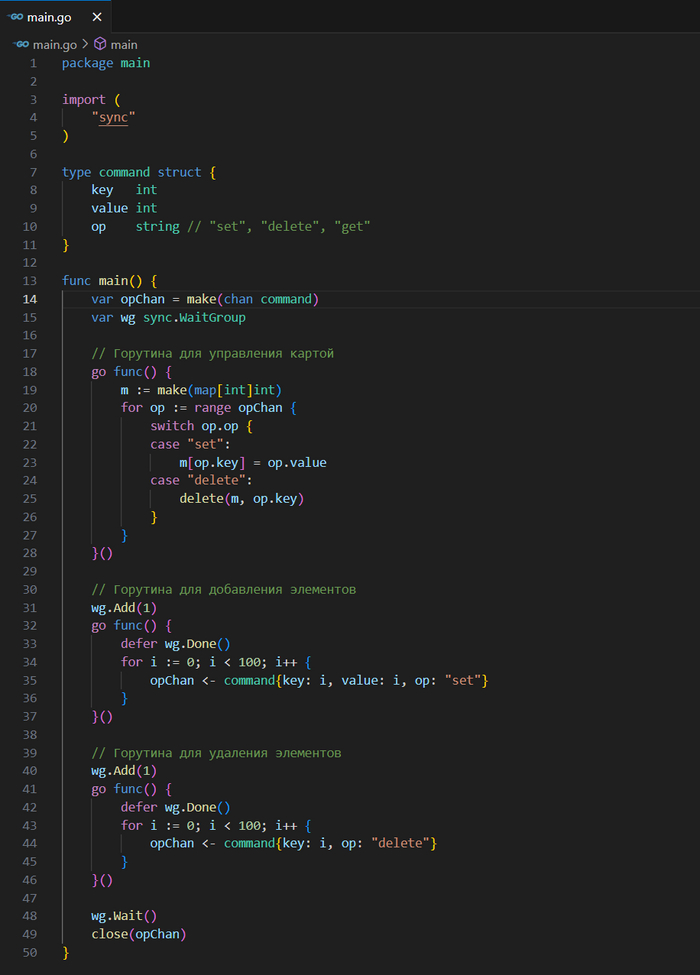
Для синхронизации и обмена данными между горутинами в Go используется концепция каналов. Каналы позволяют безопасно передавать сообщения между горутинами, обеспечивая при этом синхронизацию доступа к данным.
Каналы в Go — это средства для синхронизации и коммуникации между горутинами, позволяя им безопасно обмениваться данными. Работа с каналами в Go обеспечивает синхронизацию доступа к данным без необходимости использования блокировок или других механизмов синхронизации, что делает код более простым и безопасным.
Блокировка
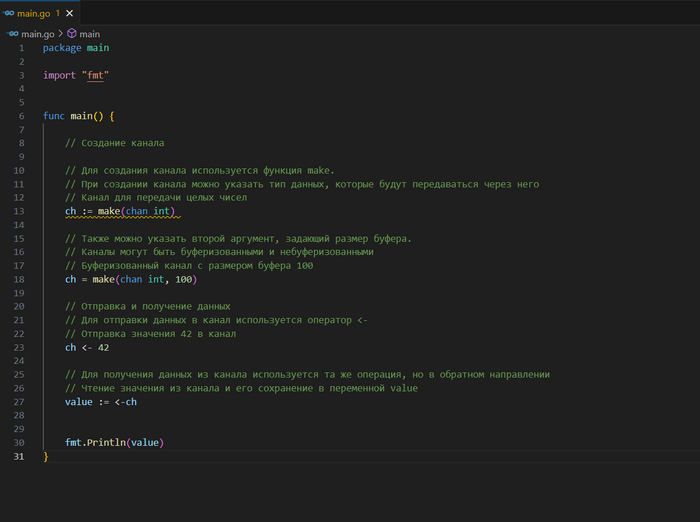
Небуферизованные каналы блокируют отправляющую горутину до тех пор, пока другая горутина не прочитает из канала, и наоборот — получающая горутина блокируется до тех пор, пока значение не будет отправлено.
Буферизованные каналы позволяют отправлять значения в канал без блокировки до тех пор, пока буфер не будет заполнен. Аналогично, данные могут быть прочитаны из канала, если он не пуст.
Закрытие канала
Канал можно закрыть с помощью функции close, чтобы указать, что больше нет значений для отправки. После закрытия канала нельзя отправлять в него данные, но можно продолжать получать данные, которые были в нем до закрытия:
close(ch)
Попытка отправить данные в закрытый канал вызовет панику.
Проверка, закрыт ли канал
При чтении из канала можно использовать вторую переменную, чтобы проверить, закрыт ли канал:
value, ok := <-ch // ok будет false, если канал закрыт и в нем больше нет значений
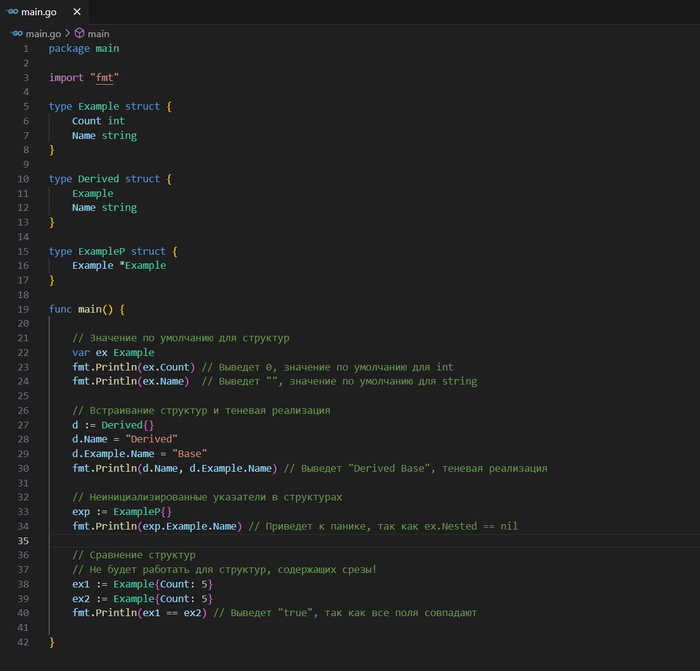
Использование каналов для синхронизации
Каналы могут использоваться не только для обмена данными, но и для синхронизации выполнения горутин, например, чтобы дождаться завершения работы нескольких горутин перед продолжением выполнения основной программы.
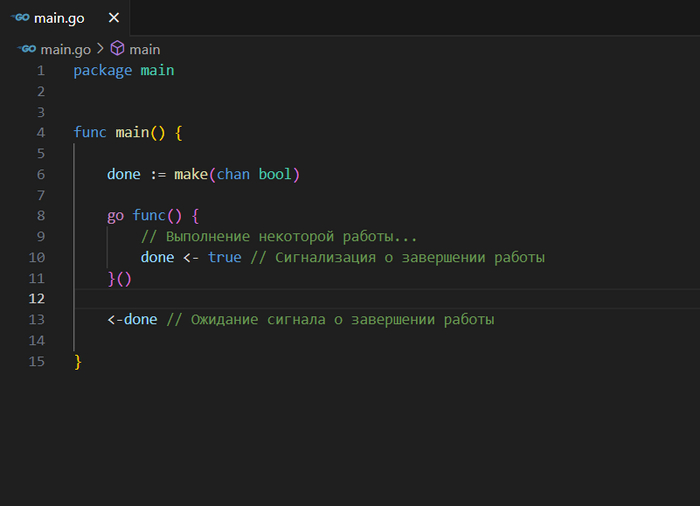
package main
func main() {
done := make(chan bool)
go func() {
// Выполнение некоторой работы...
done <- true // Сигнализация о завершении работы
}()
<-done // Ожидание сигнала о завершении работы
}
Давайте рассмотрим простой, но весьма показательный пример, который может использоваться в продакшене: параллельную загрузку данных из нескольких источников с помощью горутин и каналов. Этот подход часто используется при работе с внешними API или при выполнении других I/O-операций, требующих асинхронности и конкурентности.
Цель
Мы хотим параллельно запросить данные из трех разных источников. Для упрощения примера представим, что эти "запросы" просто спят (time.Sleep) разное количество времени для имитации задержки сети. После "запроса" каждая горутина отправляет результат в канал. Основная горутина ожидает все результаты и затем продолжает выполнение.
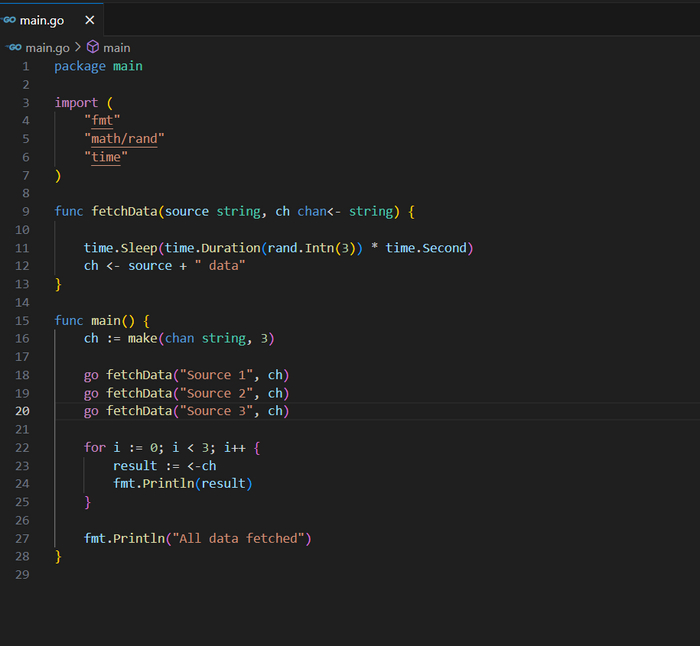
package main
import (
"fmt"
"math/rand"
"time"
)
func fetchData(source string, ch chan<- string) {
time.Sleep(time.Duration(rand.Intn(3)) * time.Second)
ch <- source + " data"
}
func main() {
ch := make(chan string, 3)
go fetchData("Source 1", ch)
go fetchData("Source 2", ch)
go fetchData("Source 3", ch)
for i := 0; i < 3; i++ {
result := <-ch
fmt.Println(result)
}
fmt.Println("All data fetched")
}
Подводные камни
Утечки горутин
Горутины, которые никогда не завершаются, могут привести к утечкам памяти. Это часто происходит, когда горутина ожидает на канале, который никогда не будет закрыт, или ожидает на блокировке, которая никогда не освободится.
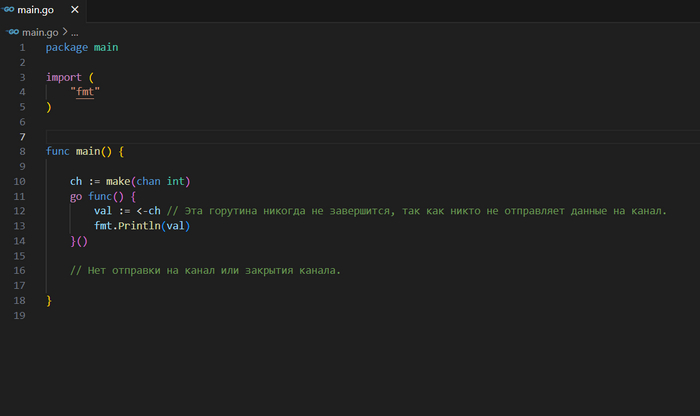
Как избежать: Убедитесь, что все горутины имеют чёткие условия завершения и что все каналы, на которых они ожидают, будут в какой-то момент закрыты.
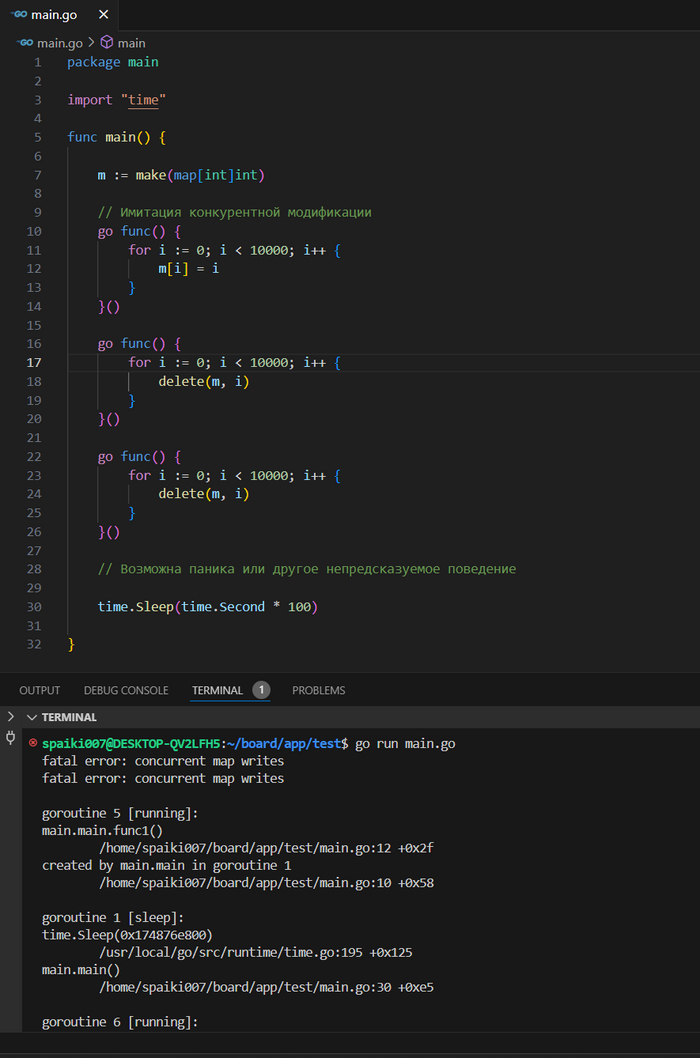
Проблемы с синхронизацией и гонки данных
Доступ к общему состоянию из нескольких горутин без надлежащей синхронизации может привести к гонкам данных, что делает поведение программы непредсказуемым.
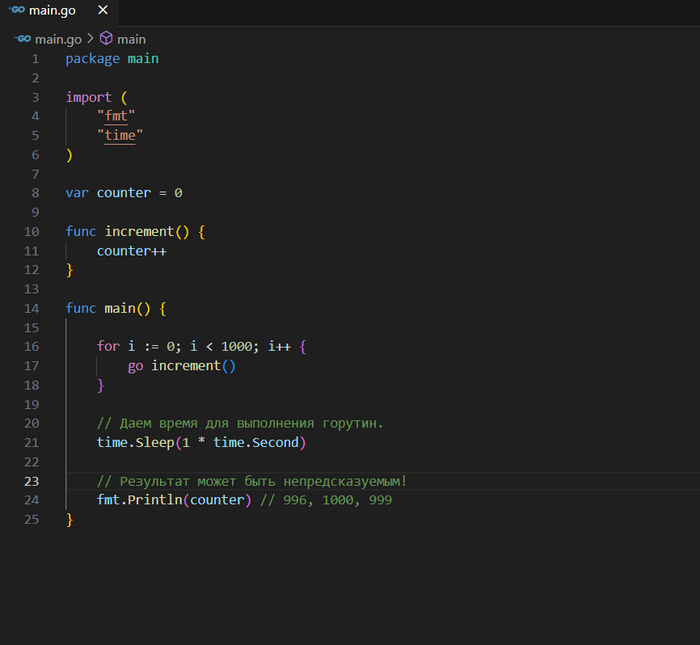
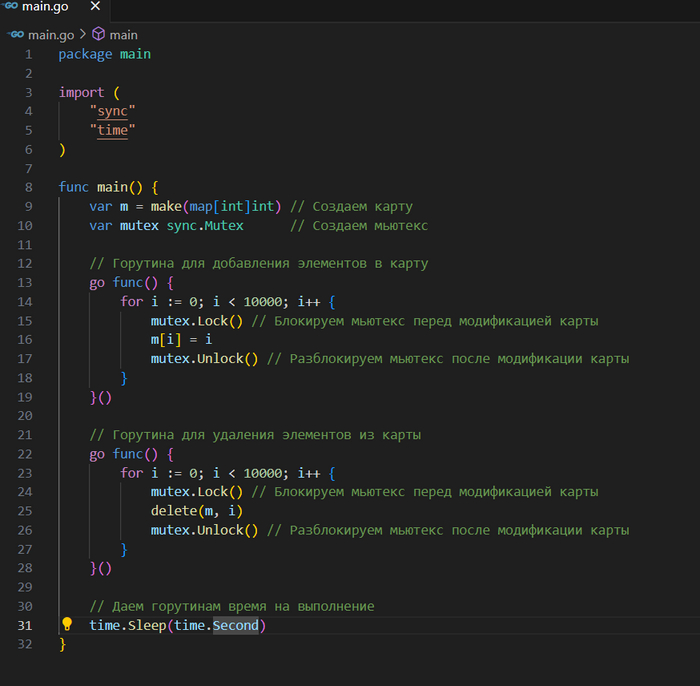
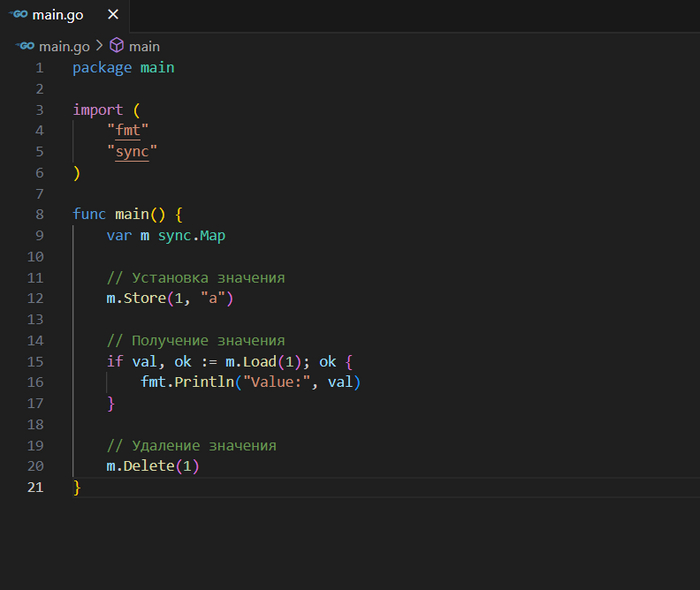
Как избежать: Используйте мьютексы (sync.Mutex) или каналы для синхронизации доступа к общим ресурсам.
Мёртвая блокировка (Deadlock)
Мёртвая блокировка может произойти, когда две или более горутин ожидают друг друга, образуя цикл ожидания, из которого невозможно выйти.
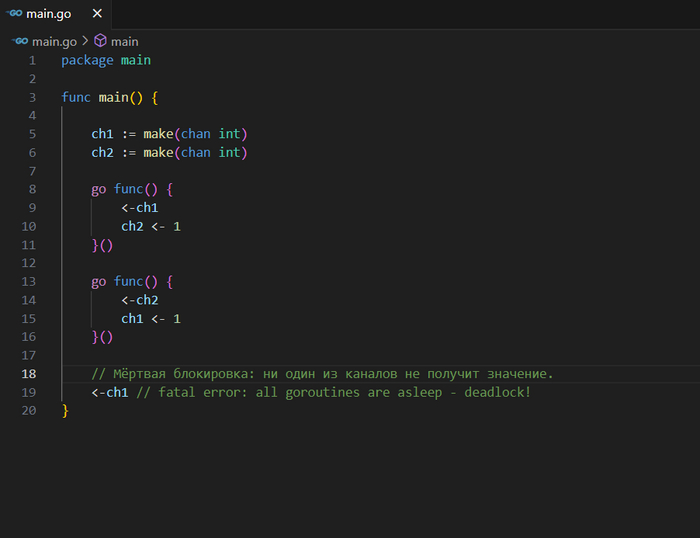
package main
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go func() {
<-ch1
ch2 <- 1
}()
go func() {
<-ch2
ch1 <- 1
}()
// Мёртвая блокировка: ни один из каналов не получит значение.
<-ch1 // fatal error: all goroutines are asleep - deadlock!
}
Как избежать
go vet — это инструмент командной строки в Go, предназначенный для анализа исходного кода на предмет общих ошибок, таких как гонки данных, неправильное использование синтаксиса, несоответствия типов и многое другое. Он не заменяет тесты, но может помочь выявить потенциальные проблемы в коде на ранних этапах разработки.

Race Detector - Запуск приложения с включенным детектором гонок (-race флаг компилятора) может помочь выявить некоторые виды блокировок и условий гонки, хотя его основная цель — обнаружение гонок данных.
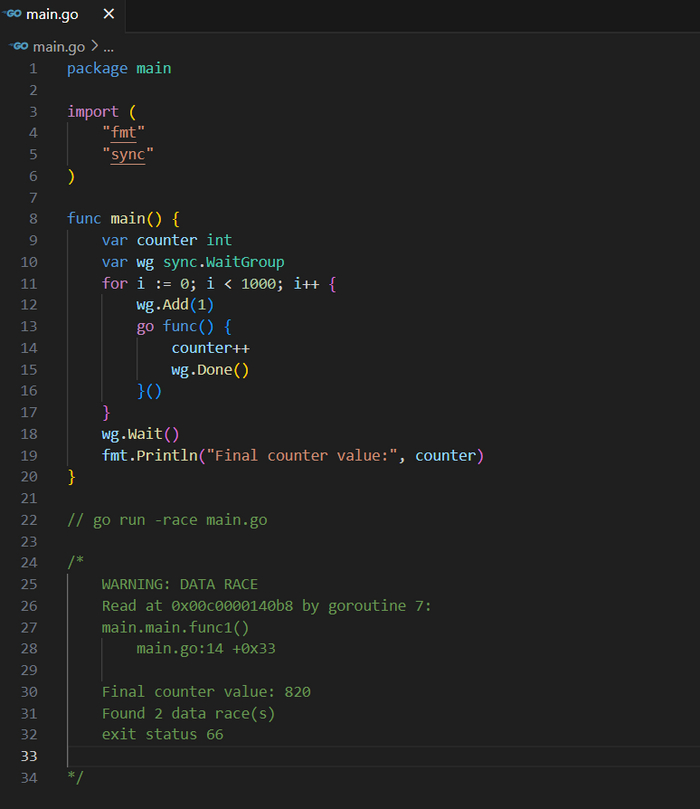
package main
import (
"fmt"
"sync"
)
func main() {
var counter int
var wg sync.WaitGroup
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
counter++
wg.Done()
}()
}
wg.Wait()
fmt.Println("Final counter value:", counter)
}
// go run -race main.go
/*
WARNING: DATA RACE
Read at 0x00c0000140b8 by goroutine 7:
main.main.func1()
main.go:14 +0x33
Final counter value: 820
Found 2 data race(s)
exit status 66
*/

правильный вариант
package main
import (
"fmt"
"sync"
)
func main() {
var counter int
var wg sync.WaitGroup
var mutex sync.Mutex // Добавляем мьютекс для синхронизации
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
mutex.Lock() // Захватываем мьютекс перед изменением счётчика
counter++
mutex.Unlock() // Освобождаем мьютекс после изменения счётчика
wg.Done()
}()
}
wg.Wait()
fmt.Println("Final counter value:", counter)
}
Дебаггеры и инструменты профилирования: Использование инструментов, таких как pprof или отладчиков, которые могут помочь вам визуализировать и анализировать блокировки и другие проблемы синхронизации в вашем коде.
Создадим файл main.go с простым кодом, который намеренно создаёт нагрузку на CPU и память, чтобы мы могли увидеть что-то интересное в отчётах pprof.
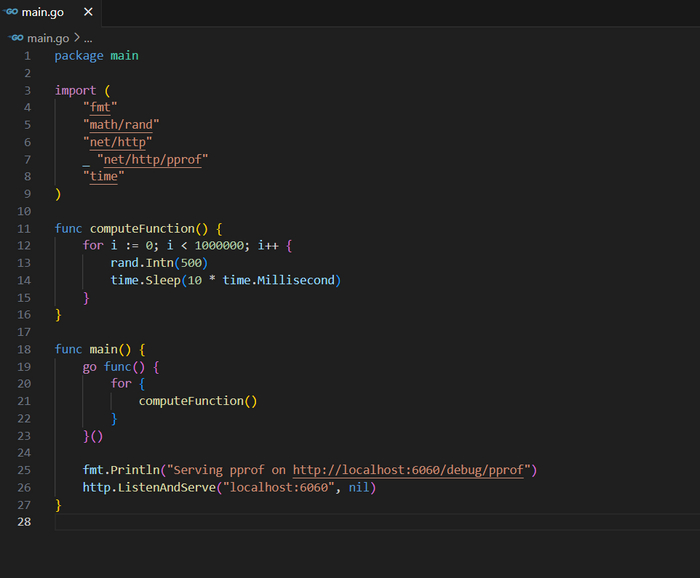
Этот код запускает бесконечный цикл, который выполняет функцию computeFunction, создающую нагрузку. Кроме того, он запускает HTTP-сервер с поддержкой pprof на порту 6060. Запустите программу
go run main.go
Откройте другой терминал и используйте go tool pprof для сбора различных видов профилей (CPU, память, блокировки и т. д.) с вашей работающей программы.
Профиль использования CPU
go tool pprof http://localhost:6060/debug/pprof/profile?seconds=30
Эта команда соберёт информацию о производительности CPU за последние 30 секунд.
Профиль использования памяти
go tool pprof http://localhost:6060/debug/pprof/heap
Эта команда соберёт информацию о выделении памяти программой.
После сбора профиля pprof откроет интерактивную консоль, в которой вы можете выполнять различные команды для анализа собранных данных, например:
top показывает топ функций по использованию ресурсов.
list [function name] показывает детализацию использования ресурсов для указанной функции.
web генерирует граф вызовов в виде SVG и открывает его в вашем браузере (требует Graphviz).
Установить Graphviz можно так
sudo apt-get update && sudo apt-get install graphviz
Эти команды помогут вам выявить узкие места в производительности и оптимизировать ваш код.

Когда вы используете pprof с Graphviz для визуализации графов на Debian (или любой другой Unix-подобной системе), местоположение сохранения графа зависит от того, как вы вызываете команду визуализации. Если вы используете команду web в интерактивном режиме pprof, она обычно открывает SVG-файл непосредственно в вашем браузере, не сохраняя его локально. Однако, если вы хотите сохранить граф в файл, вы можете использовать другие команды в pprof, такие как svg или png, для создания файла определенного формата. В интерактивном режиме pprof введите команду для сохранения в SVG:
(pprof) svg > cpu-usage.svg
Эта команда создаст файл cpu-usage.svg в текущем рабочем каталоге. Если вы хотите сохранить файл в другом месте, укажите полный путь. Аналогично, если вы предпочитаете другие форматы, такие как PNG, используйте команду png.
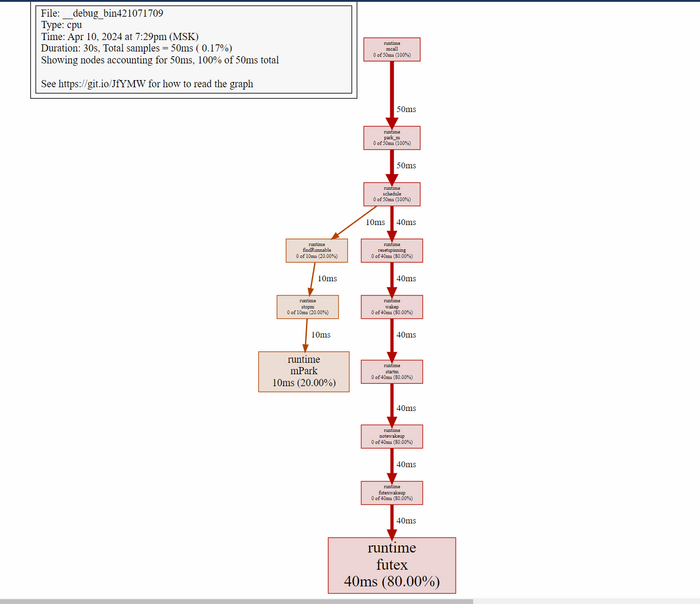
Внимательный анализ логики и дизайна: Часто лучший способ избежать мёртвых блокировок — это тщательно продумать дизайн вашей конкурентной логики, чтобы исключить взаимные блокировки на этапе планирования.