Материал очень объёмный и, что самое важное, структурированный. Часть материала представлена в видеоформате, часть – в виде текстов с примерами. Есть также матрицы картинок, множество файлов с примерами и домашние задания для закрепления изученного материала. Как вы понимаете, вся информация не поместится в один пост.
Материал рассчитан на новичков. Мы начнём с самых основ и будем постепенно переходить к более сложным техникам. В завершение курса мы изучим продвинутые плагины, которые будут полезны всем.
По сути, это авторский курс, но не спешите бросать камни – курс абсолютно бесплатный. Зачем я это делаю? Во-первых, мне просто доставляет удовольствие делиться знаниями, во-вторых, несмотря на бесплатность курса, я не отказываюсь от пожертвований, и все, кто сочтёт нужным, могут меня поддержать.
Актуальный список уроков всегда доступен на платформе Sponsr (бесплатно).
Для решения вопросов приходите в мой чат поддержки – TechnomagiX
⚡ Модуль 1. Что такое Stable Diffusion?
Что узнаете:
✅ Как генерируются изображения.
✅ На каких картинках обучалась нейросеть
✅ Ограничения SD
⚡ Модуль 2. Установка программы и первый запуск
Что узнаете:
✅ Как установить SD на свой компьютер
✅ Как запустить SD на удалённом сервере
⚡ Модуль 3. Онтология промпта (семантическая сеть и микросюжет)
Что узнаете:
✅ Виды промптов
✅ Что такое тип промпта
✅ Что такое объект промпта
✅ Что такое модификатор в промпте
⚡ Модуль 4. Prompt-инжиниринг базовый
Что узнаете:
✅ Как влияют ключевые слова
✅ Что такое негативный промпт
✅ Как управлять стилями
✅ Какие есть виды сэмплеров
✅ Как применять основные настройки: CFG, SEED, Step, восстановление лица и множество других настроек
⚡ Модуль 5. Синтаксис в prompt-инжиниринге
Что узнаете:
✅ Что такое токены
✅ Как влияют особые символы
✅ Как применять расширенный синтаксис для управления промптом
⚡ Модуль 6. Модель
Что узнаете:
✅ В чём различия между моделями
✅ Где скачивать модели
✅ Безопасность при использовании моделей
✅ Зачем нужен вариационный автоэнкодер
⚡ Модуль 7. Генерация матриц
Что узнаете:
✅ Как использовать скрипты
⚡ Модуль 8. Чтение метаданных изображения
Что узнаете:
✅ Как извлекать промпт из любого изображения
✅ Как организовать хранение изображений
✅ Программы и расширения для работы с метаданными
⚡ Модуль 9. IMG2IMG (Генерация картинки из картинки)
Что узнаете:
✅ Как создавать вариации из картинки
✅ Как работать с масками
✅ Скрипты для IMG2IMG вкладки
✅ Раскадровка и пакетная работа с картинками
⚡ Модуль 10. Работа с моделями
Что узнаете:
✅ Как объединять модели
✅ Как перенести особенности одной модели в другую
✅ Как создать inpaint модель
⚡ Модуль 11. Масштабирование и исправление изображений
В этом видео я расскажу о самой лучшей нейросети на сегодняшний день - Stable Diffusion WebUI Forge, аналог Avtomatic1111.
✨ Что вы узнаете: - Процесс установки и откуда скачать Stable Diffusion WebUI Forge - Об интерфейсе и основных настройках Forge скачать, как установить, - О новых расширениях встроенных расширениях - О новой модели для и Control net - Photomaker Желаю приятного просмотра)
Привет, друзья! В этом видео я расскажу вам о революционном инструменте InstantID, который позволяет создавать невероятные изображения с использованием вашего лица!🌟 Будь то аниме аватар или художественное изображение, InstantID делает сходство поразительным. 🎭 Вы узнаете, как работает эта технология, как ей пользоваться на Huggingface, запустить в Colab, и если у вас есть видеокарта с 12+ ГБ видеопамяти, я покажу вам портативную версию и установку в Automatic 1111! 🎨
Всем привет! В этом видео вы узнаете о новом способе восстановления рук в Stable Diffusion, который называется "Hand Refiner" и работает через ControlNet в Automatic 1111. Разбираемся, действительно ли новый препроцессор решает проблему кривых рук, рассказываю как он работает и как его можно применять - есть аж три разных способа! Также затронем тему установки ControlNet.
Другие расширения больше не понадобятся. Теперь вы можете вручную нарисовать маску на плохих руках в режиме inpainting и использовать модель depth ControlNet для их исправления с препроцессором hand_refiner.
Выполните следующие действия:
1. Генерируем изображение, на котором будут плохо проработаны кисти рук
2. Заходим в img2img Inpainting и рисуем маску на плохой руке
3. Включаем ControlNet и выбираем depth_hand_refiner во вкладке preprocessor и depth модель.
4. Запускаем генерацию получаем исправленные руки 🤘
Стоит добавить, что по инпеинтить место крепления новых исправленных рук все равно пару раз придется.
HandRefiner также хорошо работает и с ADetailer и даже на SDXL моделях, но модель CN Depth надо будет переключить на совместимую.
Для установки вам просто нужно обновить расширение ControlNet внутри вашего A1111, все остальное загрузиться автоматически.
Друзья, всем привет, долгожданное продолжение обзора на графическую нейросеть Fooocus, уже версии v2.1. Это видео полностью посвящено Input Image.
Вы узнаете как работают вариации, чтобы сделать похожее изображение, и апскейл, чтобы увеличить картинку. Как работает каждый ControlNet на вкладке Image Prompt, и поймете когда какие использовать, чтобы совместить несколько изображений или сделать обложку с текстом, и узнаете как заменить лицо. Поймете как использовать InPaint и OutPaint, чтобы изменить то, что уже нарисовано, или раздвинуть границы изображения.
Друзья, всем привет, в прошлой статье Fooocus v2 — бесплатный Midjourney у вас на компьютере, вы познакомились с рисующей нейросетью которая вполне способна заменить Midjourney, узнали как её установить, как пользоваться, за что отвечают все настройки и как работают режимы, как писать запросы, чтобы нейросеть вас понимала.
Из этой части вы узнаете как с помощью нейросети Fooocus можно дорисовать любое изображение выйдя за его границы, изменить любую деталь на изображении, узнаете как добавить на свою генерацию текст, наложить свое лицо или как создать изображение по вашему референсу. Сегодня я расскажу про раздел Input Image.
Вкладка Upscale or Variation
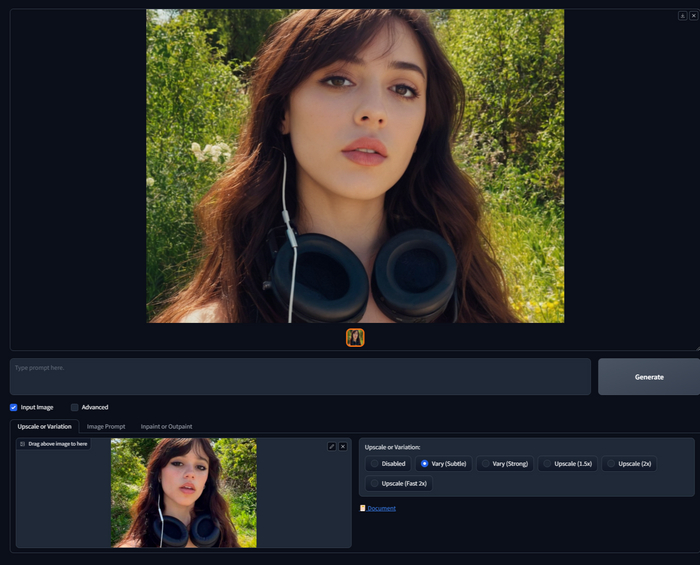
Ставим галочку на Input Image и попадаем в мир роскоши и комфорта, на вкладку где вы можете либо создать вариации уже существующего изображения, либо увеличить изображение. Это может быть как то, что вы сгенерировали, так и ваша фотография. Чтобы что-то заработало нам надо загрузить изображение, я для примера возьму фотографию Джены Ортеги, которая играла Уенсдей в одноименном сериале от Нетфликс.
Variation - Вариации
Допустим нам нельзя использовать фотографию Джены, например в коммерческой публикации, но она идеально соответствует нашей задаче, для рекламы наушников например. Выбираем в таком случае Vary (Subtle), чтобы получить то же самое, что изображенона загруженном изображении, в нашем случае девушку в лесу в наушниках, нам даже запрос писать не нужно, нейросеть сама поймет что нужно сделать. Если будем использовать Vary (Strong), то такого сходства с загруженным изображением уже не получим, оно будет просто "на тему", режим Vary (Strong) лучше работает для того, чтобы сделать вариацию генерации, где используется запрос.
Вариации отличный и простой способ получить собственную версию любого изображения, но что делать, если изображение нужно использовать, например для печати, как увеличить его разрешение?
Upscale - Увеличение
A picture of a beautiful girl with headphones around her neck walking in the woods
В положении Upscale происходит увеличение изображения, можно выбрать увеличение в 1.5 или 2 раза, есть еще 2x Fast, но он делает ощутимо хуже. Важно понимать, что новые детали таким образом не появятся, изображение просто будет увеличено с некоторым количеством едва заметных артефактов. Если необходимо вы можете несколько раз по кругу закидывать полученное изображение в апскейл, для этого просто перетащите его сверху в форму ниже. А мы переходим дальше, к самому мощному инструменту.
Вкладка Image Prompt
close-up female portrait. road, retrowave colors
Вкладка Image Prompt позволяет вам использовать в качестве подсказки изображение, и сделать это большим количеством способов, используя различные модели ControlNet. Комбинируя разные способы вы можете получить совершенно любое изображение. Вот в примере выше я взял фотку Джены, текст на прозрачном фоне, пейзажик и ретро фотографию жигулей. С первой картинки я получил надпись, со второй позу, расположение и эмоцию девушки, с третьей часть фона и с четвертой часть палитры. Невероятный результат, по очень простому запросу. Ниже я расскажу как работает каждый из режимов, чтобы увидеть эти дополнительные настройки нажмите на галочку Advanced.
ImagePrompt - Стиль и содержимое
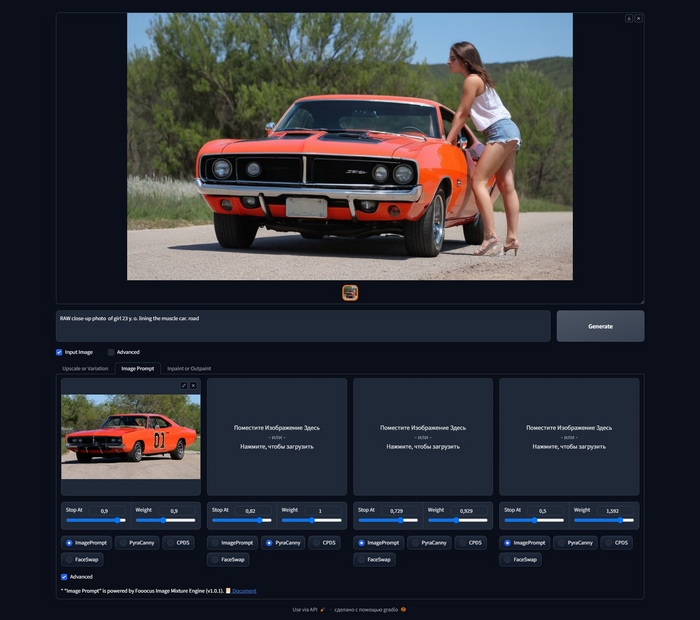
Режим Image Prompt он же СontrolNet IP adapter создан для того, чтобы вы могли использовать в качестве запроса изображение, при том забирает с референсного изображения Image Prompt не только стиль, но и содержимое, т.е. улавливает контекст. Покажу на простом примере. Загружаем фотографию ретро автомобиля, пишем простой запрос RAW close-up photo of girl 23 y. o. lining the muscle car. road, я не пишу в запросе ни модель машины ни цвет, но получаю фотографию девушки рядом с очень похожей машиной, на ту что я загрузил в качестве референса.
RAW close-up photo of girl 23 y. o. lining the muscle car. road
Таким же образом можно взять стиль с любого изображения. Еще пример: я нашел классную картинку с разрушенным городом на PromptHero, это сайт где можно найти интересные примеры и запросы для нейросетей. Картинка атмосферная, мне нравится, но она сделана в миджорни и её запрос мне не поможет. К тому же мне нужна такая же только с перламутровыми пуговицами горизонтальная и с плюшевым медведем. Задачка кажется сложной.
Чтобы получить похожую картинку только по запросу придется постараться. Можно поступить проще, загружаю это изображение в Image Prompt, пишу запрос Photo of a gloomy ruined city, close-up of a teddy bear, и получаю сразу же отличный результат, ровно такой, каким я себе представлял. Драматичная темная картинка с плюшевым мишкой который героически идет к светящемуся зданию, сразу хочется узнать что будет дальше.
Photo of a gloomy ruined city, close-up of a teddy bear
Но что делать, если результат не устраивает, всегда можно подкрутить Stop At, он отвечает за то, когда нейросеть перестанет смотреть на то изображение которое вы загрузили. По умолчанию стоит на 0.5. т.е. половину всей генерации фокус придерживается загруженного изображения, а потом уже генерирует как хочет. Часто бывает полезно увеличить или наоборот уменьшить это значение.
Увеличивать стоит если вы хотите хорошо перенести визуальный стиль. А уменьшить, если вам достаточно лишь общей композиции, так вы дадите нейросети больше свободы. Кроме того можно увеличить влияние изображения, с помощью ползунка Weight, чем больше вес, тем сильнее влияние на генерацию, выше интенсивность влияния, но одновременно с этим уменьшается и креативность нейросети, поэтому находите баланс.
Когда использовать Image Prompt? Когда надо скопировать стиль, атмосферу, освещение, а при высоком Weight и композицию изображения.
PyraCanny - Контуры
Canny создает так называемую карту, того, что изображено на картинке которую вы загружаете. Это карта состоит только из ключевых контуров, на ней отсутствует информация о цвете или стиле. Эти контуры лягут в основу вашей будущей генерации.
Например я сгенерировал милого кролика, но мне хочется сделать кролика в другом стиле, при этом я хочу полностью сохранить его пропорции. Загружаю кролика в Image Prompt, выбираю PyraCanny, ставлю Stop At на 0.9 или даже на 1, чтобы сохранить пропорции до конца генерации. И просто по промпту Bunny начинаю переключать различные встроенные в фокус стили, пока не найду то, что мне нравится. Про стили подробно рассказывал в первой части. Вот такой получается результат у меня.
Bunny + стили
Очень полезный инструмент, чтобы сделать вариации персонажей, иконок в разных стилях. Кстати вам не обязательно загружать готовое изображение, вы можете загрузить и контурный набросок сделанный от руки и Фокус попытается сгенерировать по нему изображение.
Еще PyraCanny отлично подходит чтобы стилизовать текст. Все что вам нужно, это сделать PNG изображение текста, на прозрачном фоне, для этого подойдет любой редактор, онлайн могу посоветовать photopea.com он удобный и бесплатный. Я предпочитаю делать обводку тексту, так обычно интереснее стилизуется. Чтобы текст был читаемым и не прыгал стоит поставить Stop At на 1 и Weight на 1.2, а иногда и выше, если текст искажается или недостаточно виден.
Когда использовать PyraCanny? Когда надо скопировать содержимое изображения, персонажа, архитектуру, черты лица или композицию, или добавить текст.
CPDS - Глубина и контрастность
confused Keanu Reeves as John Wick in the desert, holding a gun
CPDS создает карту на основе резкости и контрастности загруженного изображения. После обесцвечивая изображения, остается только информация о силуэте, очертаниях и резкости и глубине. Это позволяет перенести в вашу генерацию любую сложную сцену или позу, не ограничиваясь при этом строгими контурами как это делает Canny.
Для примера я взял знаменитую сцену с Траволтой из фильма Криминальное чтиво и воссоздал с участием других персонажей: Гомера Симпсона, Гэндальфа, Джона Уика, Дарта Вейдера и еще нескольких.
Получилось отлично, а главное достаточно просто, запросы были в духе confused Homer Simpson.
Когда использовать CPDS? Когда нужно перенести силуэты и глубину, воссоздать сложные сцены, позы, глубину в пространстве.
FaceSwap - Замена лица
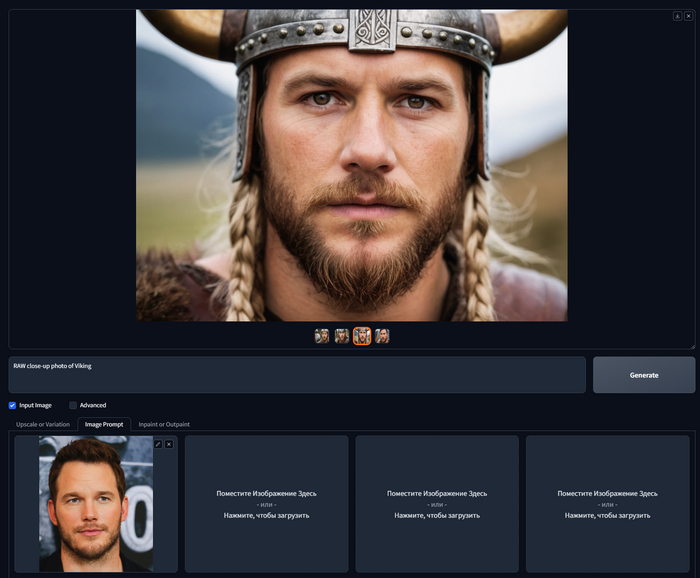
Вот мы добрались и до единственной ложки дегтя, то, что разработчик называет FaceSwap, на самом деле никакой не FaceSwap, а просто IP Adapter, как и Image Prompt, но обученный на лицах, он их вырезает и пытается встроить в генерацию. Но, честно говоря, это работает плохо. Такое ощущение, что пьяный друг кому-то рассказал как вы выглядите, и генерация это результат по мотивам такого описания. Определенно есть какое-то сходство, но есть и различие , которое пугает эффектом зловещей долины. Как я не крутил настройки так и не смог заставить этот режим работать хорошо. Разве узнаете вы на этой фотке Криса Пратта, Звездного лорда из Стражей галактики? Я нет.
RAW close-up photo of Viking
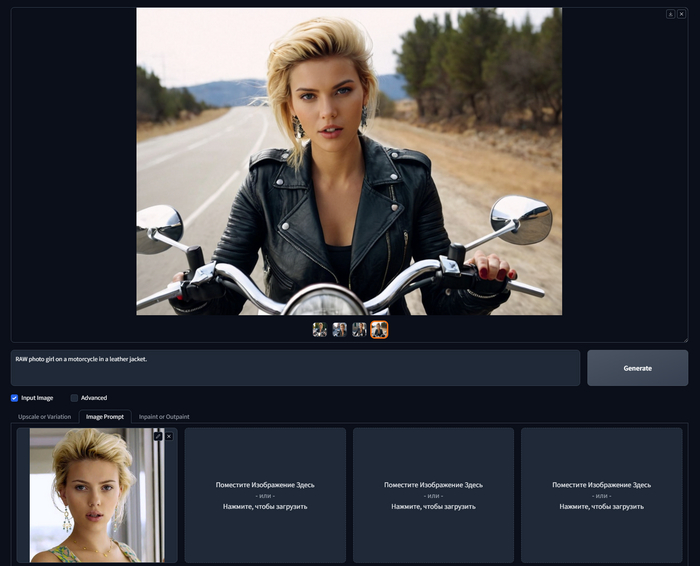
Хотел бы я сказать, что с женщинами получается лучше, но нет, вместо Скарлетт Йоханссон на мотоцикле, у меня получается её троюродная сестра, видимо.
RAW photo girl on a motorcycle in a leather jacket
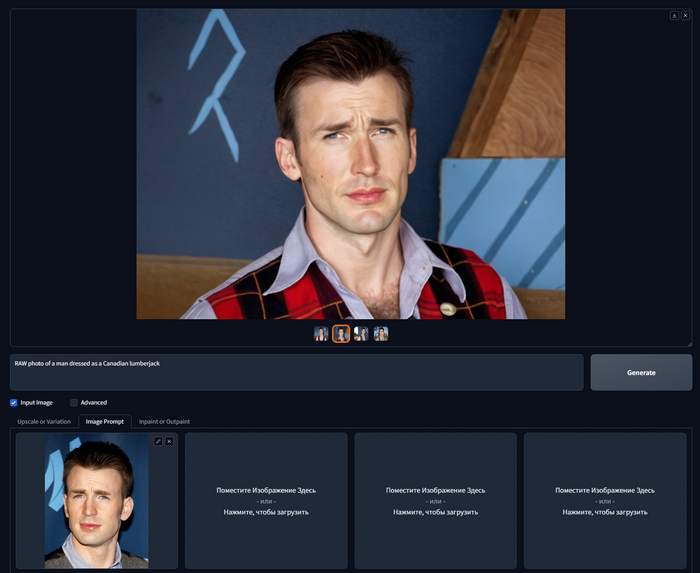
Если вы думаете что получится просто поднять Weight, то и тут вас ждет разочарование, если его поднять, то композиция, ракурс и цвета будет наследоваться с загруженного изображения, а то что вы пишите в запросе практически не будет учитываться. Для примера я загрузил фотку Криса Эванса, и выкрутил вес до 1.4, да так лицо действительно чуть больше похоже, это уже не родственник, а конкурс двойников. Но теперь все время пролезает кусок фона с референса, а ракурс лица невозможно изменить.
RAW photo of a man dressed as a Canadian lumberjack
Настоящий же FaceSwap очень аккуратно и тщательно смешивает черты лица с оригинала с загруженным лицом и практически всегда дает отличный результат, я об этом рассказывал в статьеСтань героем мемов! Делаем гифки со своим лицом с помощью нейросетей, посмотрите, очень интересная.
Я не могу назвать реализацию замены лиц в фокусе действительно работающей. Будем надеяться что в будущем разработчики либо улучшат этот редим, либо сделают тот классический FaceSwap который мы знаем по другим приложениям.
Когда использовать FaceSwap? Когда вы хотите чтобы у всех ваших персонажей было похожее лицо или типаж, либо готовите базовую картинку для замены лица в другом приложении, например в ReActor.
Различные комбинации
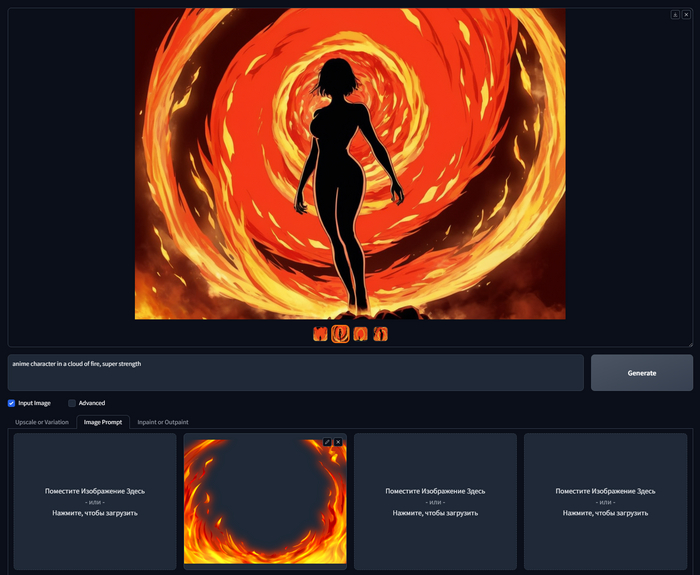
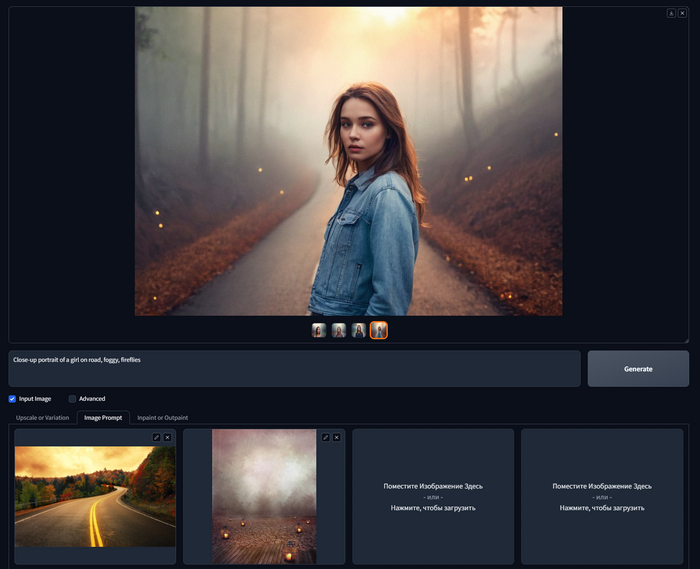
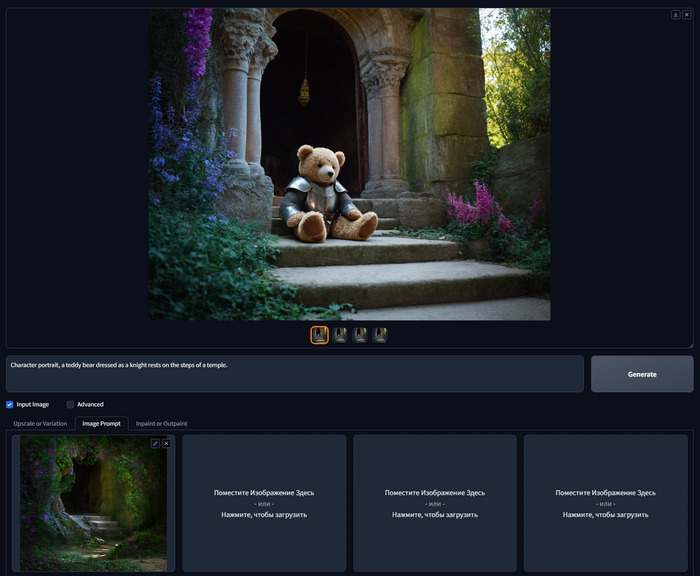
Самое классное, что вы можете комбинировать возможности Image Prompt как угодно, загружайте разные изображения, добавляйте текст, стили, и конечно управляйте запросом. Вот еще несколько классных примеров, которые были бы сложно получить только по текстовому описанию.
anime character in a cloud of fire, super strength
Close-up portrait of a girl on road, foggy, fireflies
Character portrait, a teddy bear dressed as a knight rests on the steps of a temple.
Специально для моих подписчиков на Бусти я собрал пак из 1 800 необычных и интересных изображений - референсов, для использования в Image Prompt. В этом материале многие изображения как раз оттуда. Теперь добавить необычный эффект, сделать интересный фон или стиль можно в пару кликов и без сложных запросов. Подпишитесь на Бусти и вы, там много полезных материалов, записи обучающих стримов и доступ в наш закрытый чат. Только поддержка подписчиков позволяет мне писать такие подробные гайды и инструкции для вас друзья. А мы двигаемся к двум оставшимся, но не менее крутым функциям, впереди Inpaint и Outpaint.
Вкладка Inpaint or Outpaint
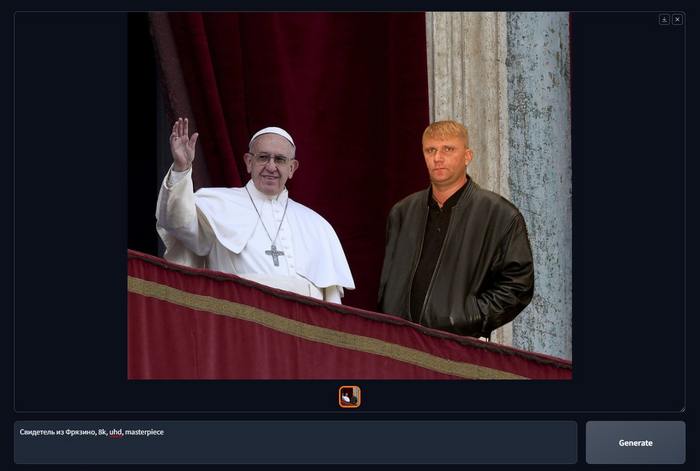
Конечно Свидетель из Фрязино уже был на этом фото c Папой Франциском, когда я его нашел, сгенерировать его не получится, но на этом примере я могу показать как можно изменить реальное изображение, прежде чем мы приступим к аутпеинтингу.
Inpaint - Изменяем изображение
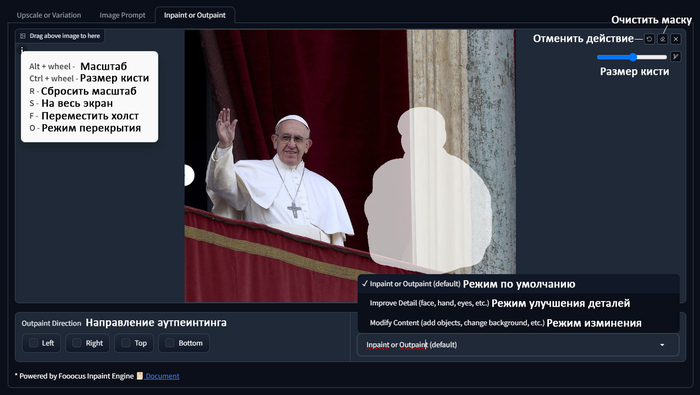
Шпаргалка по быстрым клавишам и основным функциям
Как часто бывает, что на хорошей фотографии есть что-то, чего там быть не должно, раньше исправить такое фото было сложно. Теперь же есть инпеинтинг, простая механика - закрашиваем то, что нам не нравится маской, пишем что хотим вместо того, что под маской и получаем отличный результат. При том использовать запрос не обязательно. У инпеинтинга есть три режима:
Inpaint or Outpaint (default) - режим включенный по умолчанию, он же используется на аутпеинтинга. Подходит в целом для любой задачи, но разрешение в этом режиме будет ниже чем в двух других.
Improve Detail (face, hand, eyes, etc.) - режим улучшения деталей, отлично подходит для улучшения детализации лица, рук, глаз или других объектов.
Modify Content (add objects, change background, etc.) - режим изменения, в этом режиме удобно изменять или добавлять, то чего на изображении не было.
В режимах Improve и Modify появляется дополнительное поле, в котором можно указать конкретные изменения, это сделано чтобы вам не пришлось менять основной запрос, а потом вспоминать что там было.
Например, если мы хотим избавиться от персонажа на фото, то просто запустим генерацию с пустым запросом, либо с описанием той поверхности которая находится рядом, например стена или природа. Точно так же мы можем заменить персонажа на любого другого, достаточно лишь описать его. Конечно если делать это так же грубо как я на этих примерах, то будут заметны артефакты. Но если у вас есть тачпад, то вы сможете очень аккуратно нарисовать маску.
Но, этим не ограничиваются возможности инпеинтинга, еще вы можете: заменить фон, поменять одежду или прическу, улучшить лицо, добавить то, чего не хватает, удалить то что есть, возможности ограничиваются только вашей фантазией. На мой взгляд инпеинтинг самая мощная механика в работе с изображениями, а в фокусе она к тому же максимально удобно реализована.
Outpaint - Расширяем изображение
Атупеинтинг позволяет выйти за границы изображения, работает он очень просто. Вам достаточно выбрать сторону, в которую надо расширить изображение, влево, вправо, вверх, или вниз, вы конечно можете поставить сразу все 4 галочки, но так качество будет хуже, лучше делать одну сторону за раз. Вы можете как указывать запрос, так и нет. Допустимо немного изменять запрос между итерациями аутпеинтинга, чтобы добиться желаемого результата.
Вы можно делать аутпеинтинг много раз подряд, перетягивая сгенерированную картинку вниз, но важно помнить что каждый раз разрешение изображения становится больше и в какой-то момент у вас просто не хватит видеопамяти.
Аутпеинтинг прекрасная механика которая не только позволяет изменить размер кадра и соотношение сторон, заглядывая за границу несуществующего, но и отличный инструмент для создания больших детализированных изображений. Как это, его разрешение 4674х2772, но для вашего удобства я превратил его в видео. Есть конечно косячки на склейках, но их можно убрать множеством других способов.
Друзья, на этом мы закончили изучать возможности Input Image в Фокусе, поздравляю вас! Теперь вы знаете как делать вариации, увеличивать изображения или генерации, как использовать вкладку Image Prompt и все виды ControlNet, чтобы получить уникальное изображение созданное по вашему референсу, содержащее текст или даже похожее на вас. И конечно же вы теперь сможете изменить что-то в уже существующем изображении с помощью инпеинтинга или заглянуть за границы изображения с помощью аутпеинтинга.
Cinematic still of cat holding shopping bag full of vegetables with paws, shopping with smile in a market
Делитесь тем что у вас получается в нашем чате нейро-энтузиастов и увидимся на стримах, ближайший, уже 28 ноября в 20:00 на Бусти, вход как и всегда свободный, подпишитесь чтобы не пропустить начало. Разберем Фокус по косточкам, отвечу на все вопросы.
А еще я рассказываю больше о нейросетях у себя на YouTube, в телеграм и на Бусти. Буду рад вашей подписке и поддержке. Всех обнял.
Всем привет, из этого видео вы узнаете о простой и понятной технике, которая поможет значительно разнообразить ваши работы.
Вы узнаете как можно использовать градиентные изображения в качестве основы для ваших генераций двумя способами, с контролнет и без, на моделях 1.5 и SDXL.
TL;DR Что тут вообще происходит, это обзор на технику улучшающую качество создаваемых изображений в Automatic 1111(видео с установкой), это популярная оболочка для нейронной сети создающей изображения по текстовому описанию - Stable Diffusion.