На протяжении всей своей карьеры я видел организации, которые отслеживают множество технических сигналов о своих системах и сервисах, но не в состоянии ответить на вопросы о конечном потребителе. Например:
Как повлияло на клиентов то изменение, которое мы внедрили прошлой ночью?
Повлияло ли это улучшение производительности на наши коэффициенты конверсии?
Мы тратим много времени и денег на создание сервисов для клиентов. Однако вместо того, чтобы проверять, достигаем ли мы желаемого эффекта для клиентов, мы фокусируемся на отслеживании состояния нашей технологии.
Если бы мы были поварами в ресторане, это было бы похоже на измерение нашего успеха по чистоте посуды, а не по тому, нравится ли или не нравится нашим клиентам еда, которую мы для них приготовили.
Отслеживание пользовательского опыта и поведения клиентов должно быть первым, что мы наблюдаем. Это лучший показатель надежности. Любое другое отслеживание надежности находится на один или более уровней дальше от клиента. Системный мониторинг может показывать проблемы, которые не влияют на клиента, и наоборот — в мониторинге все может выглядеть хорошо, но клиенты все еще могут страдать.
Я думаю, что это одна из причин существования SLOs (Service Level Objectives). Они ставят перед собой задачу сосредоточиться на клиентах при создании функций и услуг. Они включают отслеживание действий клиента в продакшне и получение обратной связи для принятия решений.
Не поймите меня неправильно… нам по-прежнему нужен подробный мониторинг инфраструктуры, платформы и приложения, чтобы помочь диагностировать проблемы и понимать, что происходит “под капотом”. Но если вы не знаете, как ведут себя клиенты, и вы не знаете, могут ли они использовать ваши услуги или нет — тогда устранение этого пробела является приоритетом.
Антипаттерн № 2— несогласованность окружений
Многие организации имеют сильно (или не очень) различные конфигурации и различающийся инструментарий для контроля наблюдаемости prod и preprod стендов, это несоответствие может привести к ряду проблем.
Во-первых, команды упускают возможность попрактиковаться в использовании своих инструментов и способов для наблюдаемости до того, как функционал начнет использоваться на проде. Это огромная упущенная возможность выявить проблемы до того, как они повлияют на реальных клиентов. Это также способствует увеличению разрыва между разработкой и эксплуатацией.
Во-вторых, инструменты наблюдения могут сами влиять на надежность и производительность (и даже вызывать серьезные инциденты). Если они существуют только на проде — нет возможности обнаружить эти проблемы до того, как они повлияют на реальных клиентов.
Имейте в виду, что алертинг — это немного другая история. В предпродакшн-средах вы по-прежнему можете получать все те же оповещения, что и на проде, но отправлять их нужно в соответствующие каналы: вы же не хотите будить людей в 3 часа ночи из-за проблем на dev-стендах.
Если лицензирование вашего инструментария наблюдаемости делает его невозможно дорогостоящим для запуска в любой среде, кроме прода, то, возможно, пришло время рассмотреть другой инструмент. Помните, что дело в результате. Если инструмент не позволяет вам достичь желаемого результата, то пришло время поискать что-то другое (или попробовать новый подход).
Антипаттерн № 3 — непонимание вашей экосистемы в целом
Этот антипаттерн связан с непониманием более широкого контекста системы, в котором находится наш компонент. Это может включать:
Непонимание, как работают нижестоящие сервисы, от которых вы зависите. Чтобы достичь своих целей в отношении клиента, вам, вероятно, необходимо отслеживать надежность этих сервисов.
Непонимание, кто является потребителями ваших услуг и что важно наблюдать (и что не важно).
Непонимание того, какая часть системы является наиболее критической с точки зрения бизнеса или технологически важной. Это может привести к тому, что вы потратите слишком много времени на настройку наблюдаемости для компонентов, которые вряд ли выйдут из строя или повлияют на ваших клиентов, или оставите “слепые зоны”, которые впоследствии могут вызвать серьезные инциденты.
Отслеживание только метрик на стороне сервера, когда значительную работу выполняют браузеры или мобильные устройства клиентов — это делает вас слепыми к полной надежности, производительности и удобству работы клиентов. Это также может скрыть проблемы, такие, как проблемы с выполнением JavaScript.
Отслеживание только рабочих нагрузок определенного типа. Например, отслеживать только поведение внешних клиентов, и забывать о своем собственном внутреннем персонале, который зависит от ваших сервисов для выполнения своей повседневной работы.
Антипаттерн № 4 — отсутствие согласованного идентификатора для трассировки
Когда происходит инцидент или возникает узкое место в производительности большой и сложной распределенной системы, невероятно полезно иметь возможность отслеживать взаимодействие с отдельным клиентом прямо в системе. Поскольку системы, с которыми мы работаем, постоянно усложняются, это становится более важным, чем когда-либо (и более сложным).
Решить эту проблему просто. Просто убедитесь, что компонент верхнего уровня генерирует уникальный токен (trace или correlation ID), который передается на всем пути решения. Обычно он передается как заголовок HTTP. Изучите спецификацию B3 Propagation для примера.
Антипаттерн № 5 — большая и тупая метрика
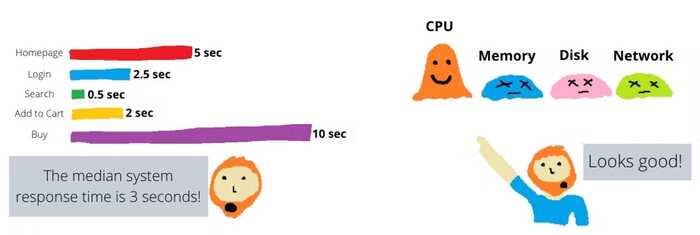
Иногда мы отслеживаем метрики настолько высокого уровня или агрегируем их по стольким измерениям, что полученные числа теряют всякий смысл и ценность.
Один из классических примеров - в сложном приложении, которое предоставляет сотни сервисов, сгруппировать все метрики вместе и сообщить об общем времени ответа для всех них. Это общее время ответа включает в себя взаимодействие с клиентами, которые получают статический контент из кеша и операции, которые требуют значительного времени для обработки.
Допустим, вы отслеживаете такой показатель, и ваш мониторинг показывает вам, что время отклика 95-го процентиля составляет 780 миллисекунд. Что вы узнали из этого числа? Как это вам помогает? Какое понимание это дает? Какие действия нужно предпринимать сейчас?
Наблюдаемость — это понимание. Чтобы достичь этого, нужно отслеживать время ответа по каждой конкретной операции взаимодействий с клиентами, в идеале тех, которые имеют наибольшее значение для вашей организации.
Другой пример “большой тупой метрики” возникает при мониторинге инфраструктуры. Я часто вижу мониторинг, который смотрит только на одну метрику: общий процент использования CPU. CPU важен, но это не единственный аппаратный ресурс, есть еще три, которые необходимо учитывать — это память, диск и сеть. И даже при отслеживании CPU, иногда нужно знать, какой именно процесс потребляет процессорное время, какие ядра процессора активны в определенный момент времени, или используется ли CPU системными или пользовательскими процессами. Бездумное отслеживание только одной метрики может в конечном итоге навредить.
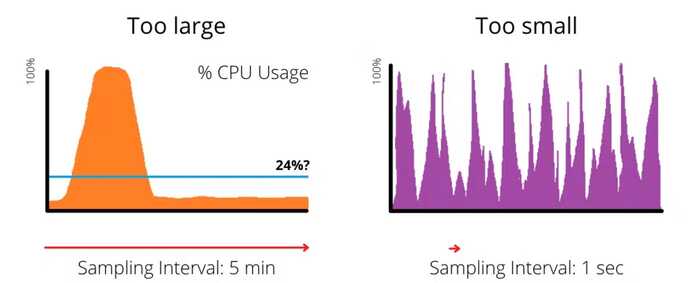
Антипаттерн № 6 — плохие интервалы выборки
Интервалы выборки похожи на кровати из сказки “Маша и три медведя”. Вы не хотите, чтобы они были слишком большими или слишком маленькими, но хотите, чтобы они были именно такими, как нужно.
Давайте воспользуемся примером % загрузки процессора. Что, если вы решили фиксировать среднюю загрузку CPU на сервере каждые пять минут? В течение этого времени может быть период длительностью в одну минуту, когда нагрузка на CPU составляет 100%, а все остальное время она составляет 5%. Ваш мониторинг показал бы среднюю нагрузку на CPU в 24% за это пятиминутное окно, что верно, но мы не увидим того факта, что был период, когда наши клиенты, скорее всего, пострадали. Использование процессора на уровне 24% также вводит в заблуждение, потому что создается впечатление, что загрузка была довольно постоянной, тогда как на самом деле она происходила скачками.
С другой стороны, что было бы, если бы вы замеряли использование CPU каждую секунду? Статистически, будут периоды в одну секунду, когда использование CPU достигает 100%, но, в зависимости от контекста, это, вероятно, не окажет значительного влияния на пользователей. Что касается загрузки процессора, то речь идет о длительных периодах высокой нагрузки, которые приводят к возникновению очередей. Однажды я работал с командой, которая была зациклена на “максимальной загрузке процессора” как на своем ключевом показателе, что привело к массовой перегрузке инфраструктуры.
Антипаттерн № 7 — неверное понимание метрик
Важно не принимать метрику за чистую монету, не имея четкого представления о том, что именно она значит.
Один из примеров, который я вижу постоянно, — это отслеживание “доступной памяти” на сервере и утверждение, что “произошла утечка памяти”, когда уменьшается объем доступной памяти. Доступная память — это действительно “свободная” память, которая еще не выделена ни одному процессу. То, что “свободная” память закончилась, не означает, что на сервере нет доступной памяти для процессов.
Процессам может быть выделена память, но на самом деле эта память все еще доступна для использования другими процессами или операционной системой при необходимости. Низкий уровень доступной памяти не всегда означает, что есть проблема с памятью.
Приложения часто разрабатываются таким образом, чтобы занимать как можно больше памяти для повышения эффективности; это нормальное поведение, особенно для СУБД. Если вы действительно хотите отслеживать объем памяти, делайте это на уровне платформы или приложения. Например, отслеживайте heap memory usage в JVM.
Еще один пример — это отслеживание использования CPU контейнера. В контексте контейнера, что такое “% загрузки CPU”? Что это значит? В своем выступлении на Neotys PAC 2020 “Видеть — значит знать, измерение CPU throttling в контейнерных средах” Edoardo Varani продемонстрировал (с доказательствами), что % загрузки CPU не является хорошим показателем того, насколько используется контейнер. Он смог создать ситуации, когда загрузка CPU контейнера составляла 100%, но производительность приложения не снижалась, или при 50% загрузке процессора приложение стояло в очереди на процессорное время. При мониторинге контейнеров смотрите на % Throttled Time как на более точный показатель того, насколько используется контейнер.
Антипаттерн № 8 — “ленивые” синтетические транзакции
Давайте будем честны: синтетические транзакции — это просто модный термин для автоматического теста, который выполняется регулярно. Он постоянно проверяет работоспособность сервисов и отслеживает их здоровье даже в тех случаях, когда не происходит никакой активности со стороны клиентов.
Большинство веб-приложений, предназначенных для клиентов, содержат последовательность шагов, которые приводят к какому-то результату для клиента. Обычно в этом процессе используется информация о сессии. Например, для интернет-магазина клиент может:
Перейти на целевую страницу
Найти товар
Просмотреть товар
Добавить товар в корзину
Купить товар
“Ленивая синтетическая транзакция” перейдет на страницу… и все. Это легко реализовать, но не дает никакой гарантии, что желаемый результат (покупка клиентом товара) может быть достигнут. Если мы не можем это доказать, мы не выполняем свою работу.
Эффективная синтетическая транзакция должна доказать, что все отдельные сервисы, необходимые для покупки товара, вместе работают должным образом. По моему опыту, я видел, как это реализовано в виде скрипта, который шаг за шагом выполняет процесс покупки товара.
Конечно, это требует гораздо больше работы. Нужно управлять данными и создавать и поддерживать нетривиальные тестовые инструменты. Я понимаю, что это может вызывать определенные затруднения и нежелание прилагать такие усилия, но, с другой стороны, синтетическая транзакция, которая не дает нам уверенности в качестве обслуживания клиентов, не служит своей цели.
Существует множество творческих способов сделать это более управляемым. Можно, например, повторно использовать автоматические тестовые инструменты, которые уже были созданы. Возможно создание специальных тестовых точек входа для запуска в продуктивной среде, чтобы упростить проверку всех сервисов.
Антипаттерн № 9 — чумовые дашборды
Дашборды предназначены для отображения информации, которая используется часто. Они не предназначены для ответа на единичные вопросы. Для этого инженерам нужны навыки анализа данных “на лету”.
Это навык, которого, по моему опыту, недостаточно в отрасли. Для многих людей, если нет созданного дашборда для ответа на вопрос, то и ответа на этот вопрос нет.
Я не говорю, что это легко. У любой продуктовой команды обязательно найдется множество инструментов и языков запросов, которые необходимо изучить, не говоря уже о том, что нужен опыт, чтобы знать, какие данные смотреть и как их анализировать в каждой конкретной ситуации. Поиск значимых закономерностей в больших наборах данных сам по себе является специализацией.
Один из основных концептов SRE — отношение сигнал/шум. Сигнал — это данные, которые дают нам представление о том, на основании чего мы можем действовать. Шум — это все остальное, и чем больше шума, тем сложнее найти сигнал. Иметь сотни неиспользуемых дашбордов — это шум. Из-за этого инженерам будет сложнее понять, куда обратиться, чтобы получить ответы на их вопросы.
Каждый созданный вами дашборд становится техдолгом, который вы несете в будущее. Если дашборды не используются и не приносят пользы, то они занимают время, которое можно потратить на более полезную работу. Я считаю, что стоит фиксировать метрики ваших дашбордов: как часто они просматриваются? Сколькими людьми? Просто не добавляйте метрики на дашборд, который никто не смотрит.
Антипаттерн № 10 — бесполезные алерты
Если вы не готовы проснуться в три часа ночи и фиксить проблему — то не создавайте на эту проблему алерт!
Каждый алерт, который не требует немедленных действий, учит ваших инженеров не воспринимать их всерьез. Я уверен, вы слышали о мальчике, который кричал “волки, волки!” — вот это и есть платформа мониторинга, которая кричит “крупный инцидент!”.
Если вы получаете много сообщений о сбоях, которые не требуют немедленных действий, то пришло время скорректировать ваши правила алертинга. Каждое ложное срабатывание будет истощать терпение, не говоря уже о том, что вам нужно иметь достаточно свободного времени, чтобы заниматься проактивной работой по обеспечению надежности. Если вы постоянно боретесь с незначительными проблемами, то это будет сложно.
Как и в случае с другими моими замечаниями в этой статье, вернемся к удовлетворенности клиента — если ваши клиенты по-прежнему могут эффективно использовать ваши услуги (и нет угрозы этому в ближайшем будущем), то почему вы паникуете или просыпаетесь посреди ночи?
Антипаттерн № 11 — накопление данных
Иногда я сталкиваюсь с командами, у которых есть собственная платформа наблюдаемости, и они не хотят ей делиться с остальной организацией.
Честно говоря, я встречал это очень редко, но когда это происходит, это свидетельствует о патологической культуре, которая включает в себя боязнь неудачи, страх перед изменениями и командный и контрольный подход. Такая культура не только создает пропасти между командами, но и подрывает психологическую безопасность и, в конечном счете, производительность ваших команд.
Я считаю, что данные о наблюдаемости должны быть свободно доступны для изучения и анализа любому сотруднику вашей организации. Записи с информацией о клиентах, конечно, требуют особого внимания, но большинство других данных о наблюдаемости не представляют существенного риска для безопасности.
Антипаттерн № 12 — разобщенные данные
Иногда у нас есть все необходимые данные о наблюдаемости, но они распределены по всей организации в разных инструментах и хранилищах. Также может отсутствовать согласованное использование стандартов или идентификаторов трассировки.
Наличие нескольких инструментов само по себе не является проблемой. Я считаю, что лучше иметь несколько разных инструментов, используемых командами, которые мотивированы, обладают собственной наблюдаемостью и чувством автономии, чем обязательное использование одного инструмента для всех. По-прежнему существует проблема, связанная с объединением всех этих данных, но это то, что мы можем решить творчески.
Настоящая проблема здесь не в том, что у вас слишком много инструментов, а в том, что команды относятся к своей наблюдаемости как к частному ресурсу, а не как к продукту для всей организации.
Антипаттерн № 13 — закидывание проблем инструментами
Проблемы решают не инструменты, а люди.
Инструменты просты в понимании и внедрении, но они никогда не дают хороших результатов без изменения методов работы. Этот анти-паттерн является личным раздражителем для меня, потому что я вижу его постоянно, где бы я ни был.
Если вы начинаете использовать какой-то инструмент, не встраивая его в культуру ваших команд и в то, как они работают, то вы не получите от него максимальной отдачи. На самом деле, я бы пошел дальше, и сказал бы, что вы практически не получите никакой пользы от этого инструмента, и это может обойтись вам в итоге в значительную сумму.
Предположим, у вас есть новый инструмент, но вы ничего не меняли в своих способах работы. Кто будет вникать в этот инструмент? Кто будет изучать его? Кто будет его настраивать? Каких результатов вы хотите добиться с помощью этого инструмента? Кто будет инструментировать ваш код, чтобы собирать метрики и события, которые важны для вас и ваших клиентов?
Один небольшой пример, с которым я сталкивался много раз за последние несколько лет, касается одностраничных приложений. Одностраничные приложения имеют один и тот же URL для каждого взаимодействия с клиентом, поэтому сам URL не дает понимания того, что делает клиент. В большинстве случаев вам нужно инструментировать свой код, чтобы определить, что делают клиенты. Если вы не можете ответить на базовые вопросы о том, что делают ваши клиенты, то насколько полезны ваши инструменты? Вам нужно вкладывать время людей, чтобы получить ценность от инструментов.
Антипаттерн № 14 — обязательные инструменты
Когда организация обязывает использовать определенный инструмент, это лишает команд автономии и ответственности за его использование. Это не приводит к лучшим результатам. Если говорить откровенно, я видел это в прошлом, когда продавец инструмента продавал идею высшему руководству, и решение о внедрении принималось без консультации с инженерами, которые должны были этот инструмент использовать.
Команды разработчиков и инженеров должны участвовать в процессе принятия решений. Принятие решений должно основываться на желаемых результатах, которые вы хотите видеть. Какие проблемы предполагается решить этим инструментом? Какие возможности он дает? Как мы должны скорректировать наши методы работы, чтобы получить максимальную выгоду от его использования?
Я предпочитаю видеть множество команд, использующих множество инструментов, но с чувством ответственности за свою наблюдаемость, а не один согласованный инструмент, навязанный кучке неохотно выполняющих свою работу команд.
Антипаттерн № 15–”избранные”
Последний антипаттерн заключается в том, что только избранная группа людей имеет доступ к платформе наблюдаемости и вносит свой вклад в нее.
Наблюдаемость ценна, когда все ей пользуются и получают от нее пользу. В прошлом я видел большие стратегические продуктовые команды, в которых есть один инженер, который настраивает весь мониторинг и он же является единственным, кто в него смотрит. Обычно это старший инженер по эксплуатации или технический руководитель, и никто другой не вовлечен в наблюдаемость.
Если только один или два человека вносят свой вклад в наблюдаемость, они могут в конечном итоге рассматривать ее как свой личный набор инструментов, а не как продукт для организации. Это приводит к появлению непонятных дашбордов и мониторингу, который ни для кого не представляет никакой ценности. Еще хуже, когда этот маленький круг людей — единственные, у кого есть доступ или лицензии на использование платформы observability.
Более мягкой версией этого, что я видел в практически каждой организации, с которой работал, является то, что наблюдаемость полностью принадлежит инженерам DevOps или SRE, и только они вносят в нее вклад. Разработчики либо не заинтересованы, либо не участвуют в этом. Наблюдаемость так же важна для delivery, как и для эксплуатации. Нам нужно изменить культуру, сделав мониторинг вещью, которой кто-то будет пользоваться.
Наблюдаемость должна быть открытой и доступной для всех сотрудников организации. Давайте способствовать культуре сотрудничества и работы вместе на пути к лучшим результатам.
Сегодня мы многое обсудили, и я не ожидаю, что каждый анти-паттерн найдет у вас отклик. В любом случае, вот то, что я хочу, чтобы вы запомнили:
В первую очередь сосредоточтесь на клиенте. Если вы не знаете, смогут ли ваши клиенты пользоваться вашими услугами, вернитесь назад и сначала убедитесь в этом, прежде чем настраивать низкоуровневый технический мониторинг.
Все дело в результатах. Ваша организация пытается чего-то достичь. Все, что мы делаем в области технологий, должно быть направлено на достижение этого, и наблюдаемость тоже сюда входит. Используйте наблюдаемость, чтобы отслеживать, добивается ли ваша организация успеха в своих начинаниях.
Относитесь к наблюдаемости как к продукту для вашей организации. Откройте платформу наблюдаемости для других, чтобы они могли использовать ее, убедитесь, что она хорошо работает в широком контексте организации, будьте внимательны к тому, как вы ее создаете.
Найдите время, чтобы понять свой уникальный контекст. Это включает в себя ваших клиентов, бизнес, архитектуру, технологии, способы работы и людей. Определите, какого результата вы хотите достичь, и постепенно повышайте свою наблюдаемость, чтобы поддерживать этот результат. Сделайте это процессом непрерывного совершенствования.