



Мини-ребус на ночь глядя:)
Хотите почувствовать себя настоящим древним египтянином? Освойте египетскую систему записи количества зерна!
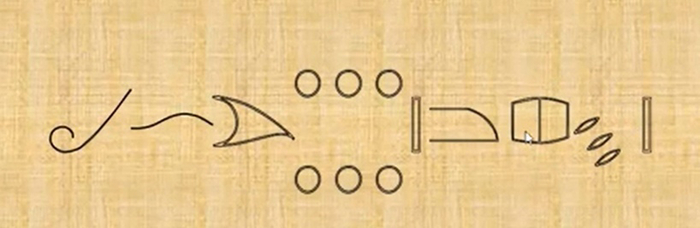
На картинке написано некое число. Попробуйте расшифровать, какое. Пояснения — в статье по ссылке в закреплённом комментарии. Пишите ваши варианты:)

Концепт сверхпроходимохода
После его выхода на долго прекратился выход G серии как мало перспективный
Производители помельче свернулись вовсе.
Уже известный что в серию эта модель не дойдёт, начали немного оживать


Показать полностью
1

Головоломки на Пикабу!
У нас новая игра: нужно расставлять по городу вышки связи так, чтобы у всех жителей был мобильный интернет. И это не так просто, как кажется. Справитесь — награда в профиль ваша. Ну что, попробуете?

Стул из 2 000 пластиковых пакетов из рек Бали
Индонезийская некоммерческая организация Sungai Watch представила шезлонг Ombak, созданный в сотрудничестве с американским дизайнером Майком Руссеком, изготовлен из выброшенных пластиковых пакетов. Для каждого кресла требуется около 2 000 штук.

Сбор пакетов осуществляется компанией Sungai Watch, которая стремится устранить пластиковое загрязнение океана, используя собственную систему плавучих барьеров для улавливания отходов, которые плывут по рекам Индонезии.
С момента своего основания три года назад организация установила 270 барьеров и собрала более 1,8 миллиона килограммов пластика, что привело к образованию огромного запаса материала.
Пластиковые пакеты являются наиболее часто собираемым материалом, но и наименее востребованным с точки зрения будущей стоимости, что заставило команду сосредоточиться на создании коллекции продуктов из этого легкодоступного ресурса.

«Сбор и накопление пластиковых отходов решает одну часть проблемы загрязнения окружающей среды пластиком, вторая проблема заключается в том, что делать со всем этим пластиком», - говорит Келли Бенчегиб, которая вместе со своими братьями Сэмом и Гэри основала компанию Sungai Watch.
«Собрав сотни тысяч килограммов пластика, мы начали рассматривать его как отличный материал для повседневных товаров, которые нам всем нужны и которыми мы пользуемся, - от мебели до мелких товаров и даже предметов искусства», — добавила она.

Компания Sungai Design создала две вариации шезлонга Ombak - с подлокотниками и без. Их делают на Бали с использованием процессов, направленных на минимизацию отходов при производстве.
Пластиковые пакеты тщательно промываются для удаления любых примесей, после чего измельчаются и подвергаются тепловому прессованию для получения твердых, прочных листов.
На высокоточном оборудовании вырезаются различные компоненты, которые тщательно формируются, чтобы минимизировать расход материала и не оставлять обрезков.
Панели соединены скрытой металлической конструкцией, в результате чего получилась чистая и визуально легкая форма с простой реечной конструкцией.

Ombak в переводе с индонезийского означает "волна", а название указывает на стремление Sungai Design очищать реки и океаны.
В соответствии с этой целью Sundai Design обязалась минимизировать свой углеродный след и внедрить процессы аудита и отслеживания источников пластика, используемого в ее продукции.
Компания планирует выпустить другие изделия из того же материала и, как социальное предприятие, будет жертвовать часть своих доходов Sungai Watch на развитие проекта, направленного на очистку рек в Индонезии и за ее пределами.
Стул был разработан таким образом, чтобы свести к минимуму использование материалов и не оставлять обрезков.
«У этого материала такой большой потенциал», — добавил Сэм Бенчегиб.
«Когда вы выбираете стул из нашей коллекции, вы не просто выбираете предмет мебели; вы принимаете участие в превращении отходов в красивый, функциональный предмет искусства, который нашел свое место в вашем доме».
Ежегодно на Индонезию приходится 1,3 миллиона из восьми миллионов тонн пластика, попадающего в океаны, что делает ее одним из худших в мире загрязнителей моря.
Показать полностью
3


В Казани научились эффективнее прогревать нефть в пласте при помощи кислоты

Специалисты Казанского федерального университета усовершенствовали технологию внутрипластового горения. Для этого они использовали олеиновую кислоту.
Внутрипластовое горение — метод нефтедобычи, при котором нефть в пласте разогревают при помощи электронагревателей, газовых горелок или реакций окисления. Нагреваясь, нефть становится менее вязкой, что упрощает процесс ее извлечения.
Как объясняют авторы разработки, олеиновая кислота при нагреве быстрее начинает взаимодействовать с кислородом, содержащемся в воздухе. Начинается реакция окисления, в ходе которой выделяется тепло, запускающее процессы окисления нефти. Если закачать кислоту в пласт с углеводородами, это тепло будет разогревать их.
Как показали эксперименты, добавление всего 1–2% олеиновой кислоты в нефть снижает температуру ее окисления с 244–367 до 233–354 градусов. За счет этого процесс нагрева становится более экономичным, быстрым и простым, так как на него затрачивается меньше внешней энергии.
— Михаил Варфоломеев. Руководитель лаборатории методов увеличения нефтеотдачи, заведующий кафедрой разработки и эксплуатации месторождений трудноизвлекаемых углеводородов Казанского федерального университета.
За счет более быстрой инициации окислительных процессов в нефти в итоге образовалось меньше тяжелых компонентов — асфальтенов. Их выход в присутствии олеиновой кислоты снизился с 6,04 до 2,32%. Выход легких компонентов, наоборот, увеличился с 29,64 до 41,05%.
Сейчас научный коллектив работает над созданием комбинированных систем, в которых инициаторы окисления будут закачивать вместе с катализатором, чтобы необходимые реакции в нефти протекали еще быстрее и стабильнее.
Больше новостей об энергетике читайте на сайте журнала Энергия+: https://e-plus.media/news/
Показать полностью

Под горой Ачишхо у Красной поляны археологи нашли 2 дольменообразные гробницы

На склоне горы Ачишхо рядом с Красной Поляной были обнаружены две гробницы. Сейчас ими занимается множество исследователей, поскольку подобных находок не было уже 30 лет.
Эксперт Андрей Кизилов отметил, что находки принадлежат эпохе бронзового века. Гробницы похожи внешне, в одной из них было захоронено три человека.
В involta.media добавили, что уже проведена фотограмметрическая съемка камеры гробницы, чтобы построить 3D-модель строения перед предстоящими раскопками.
Показать полностью
Ответ на пост «Как работает нейросеть? Рассказывает журнал "Лучик"»
Простите поклонники лучика, но не мог пройти мимо. Я не буду разбирать каждый абзац этой статьи и комментировать его, только в конце приведу цитаты и свои комментарии к ним. На мой взгляд статья очень размыто отвечает на главный вопрос, поставленный в заголовке: как работает нейросеть? Я не в курсе на какую возрастную аудиторию рассчитан материал, но с учетом того, что в статье приведена функция y = kx + b, полагаю, я могу использовать немного математики.
Авторы предлагают аналогию вроде такой: нейросеть - это набор нейронов-чисел, а учатся они, если им показать много примеров. Прежде чем переходить к нейронам, я расскажу как они учатся. Это может показаться странным, но просто принцип обучения что в нейросетях, что в простых моделях машинного обучения одинаков. Для примера рассмотрим как раз уже приведенную функцию y = kx + b. Перенося ее на реальный мир можно взять в качестве примера задачу расчета стоимости жилья в зависимости от площади квартиры. Тогда y - стоимость, x - площадь квартиры, а решаем мы задачу т.н. линейной регрессии (это для сильных духом, постараюсь обходиться без терминов). Далее слайды, которые рисовал сам, простите.
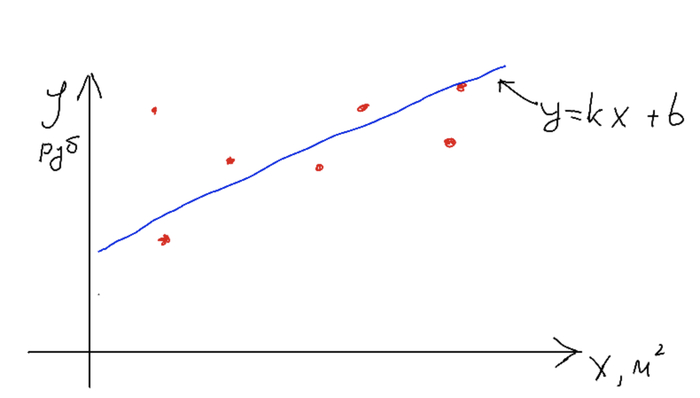
Нужно получить модель, которая по набору иксов (метраж квартиры) дает правдоподобную стоимость. Точки на графике - наши реально существующие данные. Прямая - наша функция. Обучив модель, мы можем подать ей на вход один x и получить ожидаемый y.
В случае применения машинного обучения мы должны просто настроить неизвестные параметры нашей функции (k и b), чтобы получить оптимальную прямую. Главный вопрос - как? Для этого мы должны ввести понятие ошибки модели, чтобы понять, хороши ли она выполняет свою задачу. В нашем примере ошибка - это разность между предсказаниями и реальной стоимостью.
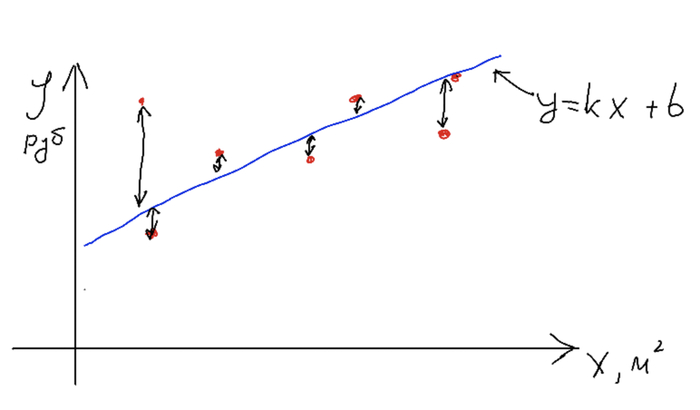
Ошибка модели - средняя разность между реальными значениями и предсказанными по модулю или в квадрате. Формальным языком: L = (y' - y)^2 / n, где n - количество примеров в данных, y' - предсказания, а y - реальные значения y для наших x).
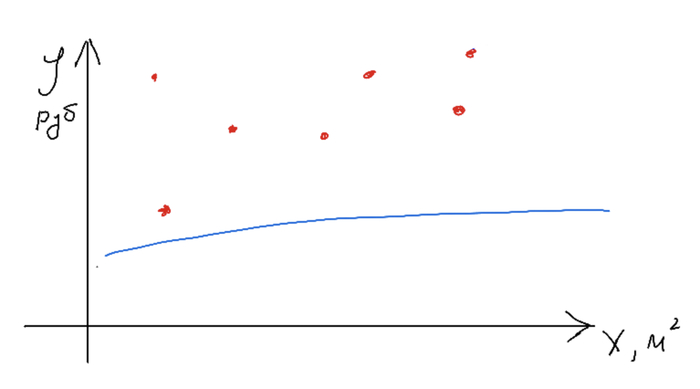
Назовем функцию вычисления ошибок функцией потерь (точнее, она так и называется). Оптимальная модель будет выдавать минимальную среднюю разность, т.е. значение функции потерь будет минимальным. С оценкой определились, теперь переходим к процессу обучения. Для этого мы строим одну случайную прямую, считаем разность между предсказаниями и данными, определяем в какую сторону нам нужно сдвинуть нашу прямую, и сдвигаем, меняя наши k и b на небольшое значение. На какое - задается параметрами модели, обычно этот шаг небольшой, чтобы не перескочить наше оптимальное положение.
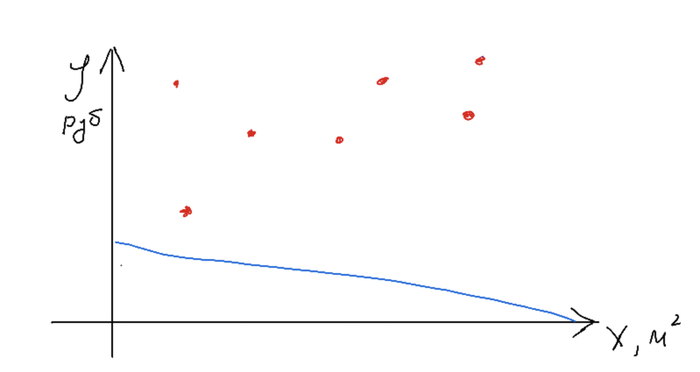
Случайная прямая
Один шаг обучения
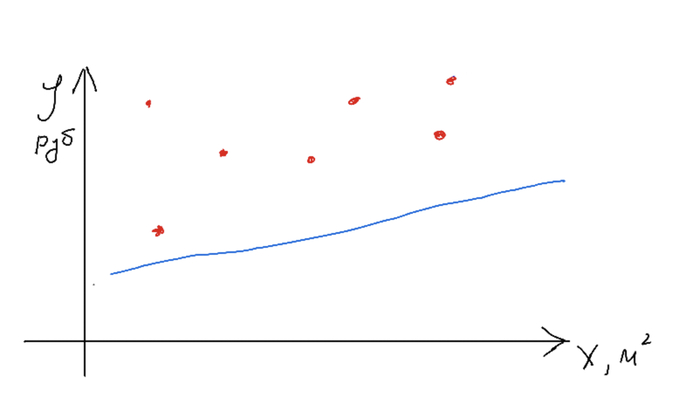
Второй шаг обучения ( и так далее)
Небольшое отступление, которое можно пропустить. Пытливый ум спросит меня, а как мы определяем в какую сторону двигаться на каждом шаге? Отвечаю - просто смотрим на знак. Раньше я упомянул, что для расчета мы используем квадрат или модуль разностей для каждого отдельно взятого примера и усредняем их. Но тогда все наши расчеты будут положительными. Трюк в том, что при обучении мы используем не саму функцию потерь, а производную от нее или т.н. градиент (блин, обещал же без терминов). Геометрически производную можно изобразить так:
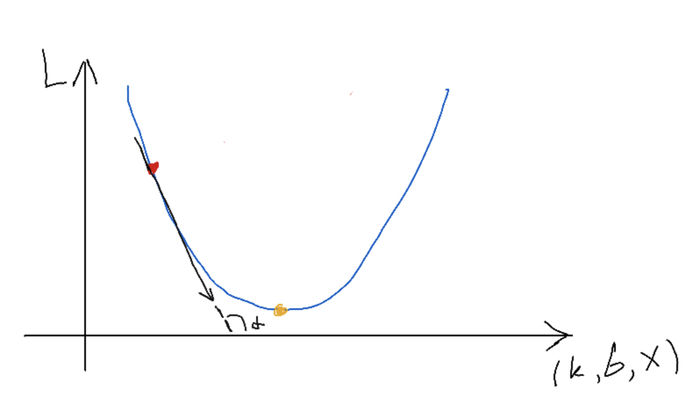
Производная - это тангенс угла наклона касательной к функции потерь в выбранной точке. Производная показывает направление роста функции.
На графике изображена функция потерь при разных значениях для нашей задачи - это парабола. Причем левая ветвь соответствует ситуации, когда мы задаем случайную прямую ниже наших точек, правая - выше. Наша задача попасть из красной точки в желтую, т.е. в минимум функции. Определив градиент, мы двигаемся в сторону уменьшения функции, достигая минимума. Математически, при расчете производной (dL = (2 / n) * (y' - y) * x) мы избавляемся от квадрата и можем получать отрицательные значения (и получаем в нашем примере) и тогда двигаемся в противоположную от знака сторону, прибавляя небольшие значения к нашим коэффициентам k и b.
Возвращаясь к объяснению на пальцах. В реальной жизни параметров, влияющих на стоимость квартиры больше, чем просто ее метраж. Тогда мы переходим в многомерное пространство. В реальной жизни у нас есть другие задачи, например то же отделение фотографий кошек от фотографий собак (задача классификации). Или генерация изображений. Но во всех этих задачах используется один и тот же принцип: мы должны определить функцию потерь - определить как мы вычисляем ошибки предсказаний модели и посчитать разницу между предсказаниями и реальными значениями и изменить значения коэффициентов, в зависимости от смещения предсказаний. Для задачи классификации животных (кошек и собак) мы на самом деле строим точно такую же прямую, просто эта прямая не проходит через точки в пространстве, а старается разделить их. Точками в этом случае могут выступать значения пикселей наших картинок, в таком случае, для обычного изображения кошечки, например, разрешением 512х512, мы работаем в 786432-мерном пространстве (потому что 3 (если используем цветное изображение RGB) * 512 * 512 = 786432) и подбираем в этом пространстве не прямую, а плоскость. И уравнение этой плоскости будет таким y = b + k1 * x1 + k2 * x2 + ... + k786432 * x786432. А функция потерь будет другая, но об этом я уже не буду говорить.
Теперь, когда мы поняли как мы учим, можно понять, что такое нейрон в нейросетях. На самом деле, ответ уже понятен. В процессе обучения мы настраиваем коэффициенты некой функции, нейрон тогда - это просто математическая функция от входных данных. Возвращаясь к статье лучика, на этой картинке нейрон - это как раз таки серый кружочек. А желтые - это значения входных данных. Они могут быть в то же время выходными данными с нейронов предыдущего слоя нейросети.
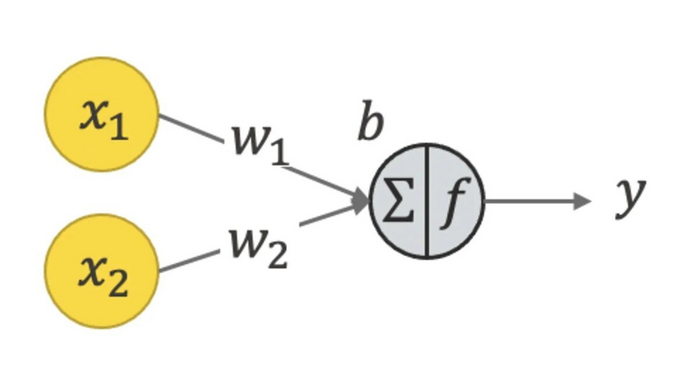
x1, x2 - значения входных данных, w1, w2, b - коэффициенты (я использовал выше k и b)
А сколько нейронов в нейросети? Много и зависит от архитектуры. Входной слой просто принимает данные и вычисляет взвешенную сумму, передавая результат на внутренние слои. На примере тех же изображений - количество нейронов на первом слое будет зависеть от параметров изображения, а именно от количества пикселей, но количество нейронов скрытых (внутренних) слоев мы устанавливаем сами. Мы можем поставить один нейрон на первый скрытый слой, который будет суммировать все данные, но толку от такой сети будет мало. На выходном слое количество нейронов зависит от нашей задачи. Для генерации нам нужно в каждом пикселе сетки предсказать реальное значение цвета, значит нейронов будет столько же, сколько пикселей нам надо получить. Если мы говорим о задаче классификации, то на выходном слое будет столько нейронов, сколько у нас классов - т.е. 2 для кошек/собак, например. Рассматривать необычные слои, вроде сверток, не будем, но они есть.
А зачем вообще нужны нейросети? Я уже выше описал, что все задачи так или иначе формализуются в набор известных функций. Но преимущество нейросетей в том, что они универсальны как раз за счет общих принципов построения. А взаимодействие нейронов на разных слоях позволяет расширить пространство настраиваемых параметров, что в свою очередь позволяет уловить связи в данных на разных уровнях. Например, разные слои нейросети, обученной на задаче классификации изображений, могут улавливать разные паттерны: например контуры, формы или цвета. Что как раз-таки используется для передачи стиля - мы замораживаем глубинные веса обученной нейросети (те, которые отвечают за пространство, форму и т.д.) и дообучаем на одном стилевом изображении только те слои, которые отвечают за "мазки кисти" и цвета.

Несколько примеров современных нейросетей и как они обучены:
Генерация изображений. Существует множество архитектур сетей для генерации. Причем я говорю о генерации без текстового описания. Например, т.н. GAN-ы. Они обучены генерировать изображения из шума, как и сказано в статье. Но они не обучаются специально запоминать формы, объемы, углы, цвета. Они обучаются генерировать изображение так, чтобы результат не отличался от данных, с которыми мы его сравниваем.
Векторизация текстов - я выделил этот пункт отдельно, т.к. все сети, работающие с текстами, должны уметь переходить от тестов к точкам в пространстве - векторам чисел. Описывать, как это происходит примерно так же долго, как я описывал линейную регрессию. Но для простоты скажем, что нейросети учатся предсказывать пропущенные в тексте слова, настраивая при этом числа в пространстве векторов, где каждый вектор соответствует отдельному слову. Это классическая задача классификации, а значит мы снова строим разделяющие плоскости.
Генерация текстов. И снова множество архитектур. Есть даже не нейросетевые (смотрите цепи Маркова, которые просто считают попарные вероятности слов в тексте). Нейросетевые пытаются предсказать одно следующее слово на основе предыдущих.
Генерация изображений по тексту. Здесь мы объединяем известные подходы и идея такая: раз мы уже знаем, как векторизовать текст, то будем использовать вектора текста как входные данные, а готовые изображения, как идеал, который нужно научится генерировать из шума. Для обучения таких моделей используется огромное количество картинок с описаниями к ним. Кстати, поэтому было много претензий к русскоязычным генеративным моделям, которые генерировали, например, американские флаги по запросу "Родина". Просто сложно создать большой датасет размеченных изображений своими силами, все используют открытые датасеты, и, например, переводят тексты и всячески обогащают данные.
Теперь можно перейти к самому интересному - цитаты из статьи.
Компьютерный нейрон – это просто... число!
Уже выяснили, что нет.
«А если собаки и кошки раскиданы вперемешку, а?» – спросите вы. Ну что ж, тогда нам может потребоваться не одна линия. И возможно не две и не три, а целый десяток или даже сотня. Важно понять, что рано или поздно мы сможем с помощью обыкновенных чисел и прямых «поделить» наш лист так, чтобы нейросеть уже знала наверняка – что именно она «видит», кошку или собаку, в чью именно область она «ткнула пальцем».
Я зацепился за это определение. Потому что если нам известно только 2 класса, то будет только одна "линия" на выходе. Да, каждый нейрон строит свое собственное решение, но он во-первых, не видит какую-то свою область данных, а во-вторых, его решение агрегируется с решениями всех остальных нейронов на выходном слое. То, что описано - это скорее работа классических деревьев решений, которые действительно нарезают пространство на сколько угодно областей.
Проблема номер один – для обучения нейросети нужно очень много информации. Чтобы научить нейросеть отличать кошку от собаки, ей нужно показать тысячи (лучше миллионы) самых разных кошек и собак. Воспитанник детского садика в возрасте трёх лет кошку с собакой не спутает, даже если видел их всего лишь пару раз в жизни...
С миллионом явный перебор. Кроме того, существуют техники дообучения, позволяющие переиспользовать обученные модели с гораздо меньшим набором данных.
Проблема номер два: нейросети совершенно не умеют анализировать собственные творения, объяснять, «что здесь нарисовано и почему», в частности, они не умеют считать! Из-за этого компьютерные изображения постоянно рисуют людей то с шестью, то с восемью пальцами. Или кошек то с тремя, то с пятью лапами.
Вообще-то, объяснять уже умеют. Но только узкий класс мультимодальных сетей (если мы обучим модель генерировать текст по изображению - обратная задача генерации изображения по тексту - то сможет). А с пальцами проблема в общем тоже пофикшена улучшениями архитектур и увеличением количества параметров моделей. Были бы деньги обучать такие модели.
Проблема номер четыре: нейросеть не умеет работать при нехватке информации, «достраивать недостающее». Скажем, человеческий детёныш, даже малыш, увидев кошачий хвост, торчащий из-под дивана, тут же уверенно «распознает» спрятавшегося котёнка и побежит ловить его! Нейросеть такое «неполное» изображение понять не в состоянии. Человек, исказивший внешность (скажем, надевший маску или загримированный) для современной нейросети опять же становится неузнаваемым.
Умеет и достраивает. И распознает и людей в масках узнает. Опять же, на это влияют как архитектура, так и способ получения данных. Всегда можно аугментировать изображения (например в части тренировочных изображений кошек и собак обрезать все, кроме хвостов и тогда такая нейросеть сможет по хвосту определить животное).
Проблема номер пять: нейросеть совершенно не понимает законов нашего мира – скажем, тех же законов оптики. Она никогда не сможет различить на картине человека – и его отражение в зеркале (для живого человека – задачка пустяковая). Она никогда не сможет различить человека или его лицо в кривом зеркале (как это делаем мы на аттракционе «Комната смеха» в городском парке, или когда разглядываем самих себя в новогодние шарики).
Аналогично - аугментация данных решает проблемы с кривыми зеркалами.
Проблема номер шесть: нейросети чрезвычайно чувствительны к разного рода помехам, дефектам, «шуму». Скажем, если на старой фотографии часть изображения залита грязью, чернилами, испорчена пятнами или царапинами, сильно выцвела, если карточка разорвана или разрезана напополам – уверенное узнавание тут же становится неуверенным и вообще ошибочным. Для человека сломанная на части кукла – всё равно кукла; для нейросети – это уже совершенно другой, неизвестный объект
Формально - да. Именно поэтому при обучении специально добавляют шум, аугментируют данные, выключают часть нейронов. И тогда модель справляется.
Проблема номер семь: нейросети на текущий момент ужасающе «однопрограммны». Если нейросеть настроена на распознавание лиц – она будет уметь только распознавать лица. Переучить её на написание текстов или музыки будет чрезвычайно сложно, часто вообще проще написать и обучить совершенно новую сеть. Если она умеет отличать квадраты от треугольников – даже не пробуйте попросить её отличить кошку от собаки или самолёт от парусной лодки...
В целом верно, но не совсем. В рамках одной моды и архитектуры - работа с текстом, или изображениями, или музыкой - переучить нейросеть не проблема. И даже мультимодальные модели существуют и активно развиваются. Но да, архитектура генератора музыки и генератора изображений и данные для этих сетей настолько разные, что просто в тупую подменить данные нельзя. Удивительно.
Проблема номер восемь: связи между компьютерными нейронами случайны, поэтому нейросети лишены запоминания созданных образов. На приказ «нарисуй мне дерево» нейросеть охотно откликнется и будет рисовать деревья снова и снова, но... каждый раз это будет «другое дерево». И если вы напишете команду «нарисуй мне такое же дерево, как в прошлый раз, только на берегу реки», нейронная сеть не поймёт вас. Она опять нарисует «новое случайное дерево».
Связывать случайность (кстати, они не случайны, а заданы архитектурой) связей между нейронами и неспособность запоминать созданный образ - максимально некорректно. То, что здесь описано, на самом деле решаемо. Но это решение за пределами архитектуры нейросети. Это как предъявлять претензии микроволновке, за то, что она не включила сама кнопку, типа, могла бы и запомнить. У нее нет инструментов запоминания результата, как нет у голой нейросети - она получает данные на вход, генерирует выход и все.
В целом, я догадываюсь, что изначальная статья была рассчитана на детей младшего школьного возраста. И я по размышлению выкинул из моего разбора несколько цитат, которые на самом деле оказались верны, просто сильно упрощают представление. И то, что я описал может быть не всем понятно и требует более глубокого погружения.
Показать полностью
8
Резидент "Сколково" Spawn перерабатывает мусор при помощи грибницы и создает мебель

Резидент "Сколково" Spawn придумал способ создавать мебель, перерабатывая мусор. Для этого используются грибницы.
Для инновационного способа переработки мусора учеными-микологами было выведено более 250 штаммов грибов. Грибницы перерабатывают отходы и выдают изделия, которым можно придать любую форму.
В involta.media добавили, что сейчас стартап перерабатывает целлюлозосоджержащие композиты.
Показать полностью
1

Лента Экспертов: присоединяйтесь и делитесь опытом
Присоединяйтесь к обсуждению самых разных тем: как выбрать комплектующие для ПК, куда съездить на майские праздники, можно ли решить юридический вопрос и вернуть деньги, как спасти лимонное дерево или какой велосипед купить на весну–лето.