Китай обходит санкции: LineShine — CPU-only суперкомпьютер на 1,54 EFLOPS

Результат, который меняет правила
В мае 2026 года китайский Национальный центр суперкомпьютинга (NSCC) в Шэньчжэне опубликовал данные, способные перекроить представление о вычислительной инфраструктуре для искусственного интеллекта. Суперкомпьютер LineShine показал 1,54 экзафлопс (BF16) при обучении ИИ-моделей — и он не использует ни одного GPU.
Полностью CPU-only архитектура на базе процессоров LX2 с архитектурой Armv9, предположительно разработанных Huawei, — это прямой ответ на американские санкции, запрещающие поставку передовых графических процессоров в Китай.
Подавляющее большинство ведущих суперкомпьютеров мира и AI-кластеров строится по гибридной схеме: CPU для оркестрации, GPU — для параллельных вычислений. Nvidia A100, H100 и их аналоги стали индустриальным стандартом. Но санкции 2019–2023 годов отрезали Китай от передовых чипов. Ответ оказался радикальным: вместо поиска GPU — масштабирование CPU до экзафлопсового уровня.
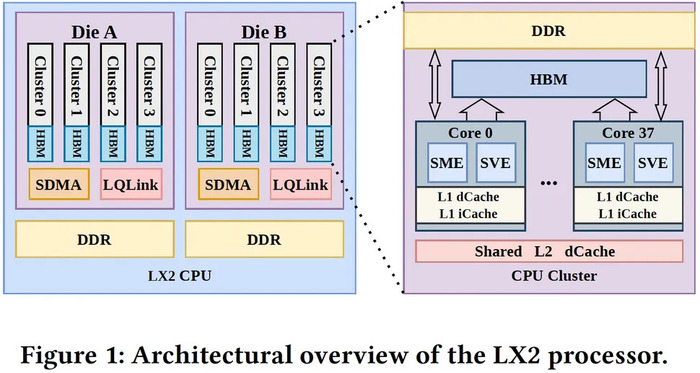

Архитектура суперкомпьютера LineShine — NSCC Shenzhen, 2026
Май 2019 Включение Huawei в Entity List — запрет на экспорт технологий США
Октябрь 2022 Ограничения на GPU с производительностью >480 GFLOPS (INT8) — A100 и H100 запрещены в Китае
Октябрь 2023 Расширение ограничений: даже «упрощённые» H20, L20, L40s под угрозой
Май 2026 LineShine демонстрирует 1,54 EFLOPS — CPU-only, без GPU, без Nvidia
Ключевые характеристики
Архитектура процессора: Armv9, 2 чиплета на LX2
Ядра на процессор: 304 (8 кластеров × 38 ядер)
Векторные/матричные расширения: SVE + SME (Scalable Matrix Extension)
Поддерживаемые форматы: FP64, FP32, BF16, FP16, INT8HBM (в-package)32 ГБ, до 4 ТБ/с (4 HBM-домена на чиплет)
Внешняя память: DDR5 (вне кристалла)до 256 ГБ NUMA-домены16 на процессор
Интерконнект: LingQi (LQLink), 1,6 Тбит/с на узел
Охлаждение: Жидкостное
Преимущества и недостатки CPU-only
Преимущества
Нет передач данных CPU↔GPU — единое адресное пространство
Огромные когерентные пулы памяти (HBM + DDR5)
Естественная интеграция с традиционными HPC-задачами
Независимость от CUDA и зарубежных акселераторов
Идеально для workload со сложным control flow
Поддержка RAG и длинных контекстных окон
Ниже энергоэффективность (TFLOPS/Watt) vs GPU
FLOPS utilization ~15% (против 40 - 60% у GPU-кластеров)
Огромная сложность масштабирования 40 960 процессоров
Топологически-ориентированное размещение памяти
Co-design ядер — дополнительная сложность Software/Hardware
Ограниченная доступность процессоров Huawei
Ключевой вывод
LineShine не замена GPU-кластерам. Это доказательство концепции: при достаточном масштабе (2,4 млн ядер), продвинутой архитектуре (Armv9 + SVE + SME) и глубокой оптимизации стека процессоры могут стать жизнеспособной альтернативой для определённого класса AI-задач.
Китай не смог получить доступ к Nvidia и создал собственную экосистему. Вопрос не в том, лучше или хуже LineShine по сравнению с El Capitan. Вопрос в том, что теперь у Китая есть независимый путь к экpафлопсовым ИИ-вычислениям — и этот путь будет только расширяться.
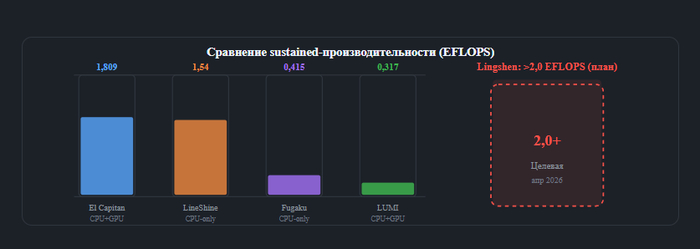
Сравнение sustained-производительности ведущих суперкомпьютеров мира. Lingshen — заявленная цель >2 EFLOPS