Это перевод третьей статьи из серии расследований Data Colada про фальсификацию данных в статьях профессора Гарвардской школы бизнеса Франчески Джино.
Первую часть можно прочитать тут, вторую – тут.
Напоминаю, что этот пост является моим вольным пересказом расследования Data Colada; все картинки тоже оттуда.
Часть 3: Обманщики вне порядка
В этот раз речь пойдет о статье Джино и Вильтермута «Злой гений? Как нечестность может приводить к большей креативности» [“Evil Genius? How Dishonesty Can Lead to Greater Creativity”], опубликованной в 2014 году, а именно об Исследовании 4.
Авторы расследования из Data Colada уточняют, что, по имеющейся у них информации, соавтор Джино не проводил и не помогал со сбором данных для эксперимента, о котором пойдет речь. База данных получена несколько лет назад напрямую от профессора Джино.
Эксперимент проводился онлайн. Участники (178 человек) сначала выполняли задачу, в которой подбрасывали виртуальную монету и в которой можно было смошенничать. После этого участникам предлагалось два творческих задания. Далее сосредоточимся на результатах задачи «использования», в которой нужно было в течение 1 минуты придумать как можно больше творческих способов использовать газету (эта задача ранее применялась другими учеными как способ оценки креативности).
Гипотеза авторов подтвердилась: участники, которые сжульничали при подбрасывании монеты, придумали больше вариантов использования газеты (M = 8,3, SD = 2,8), чем участники, которые не обманывали (M = 6,5, SD = 2,3, p <,0001).
Но снова аномалия: неупорядоченные наблюдения
Как и в первой части расследования, фатальный признак фальсификации связан с сортировкой данных.
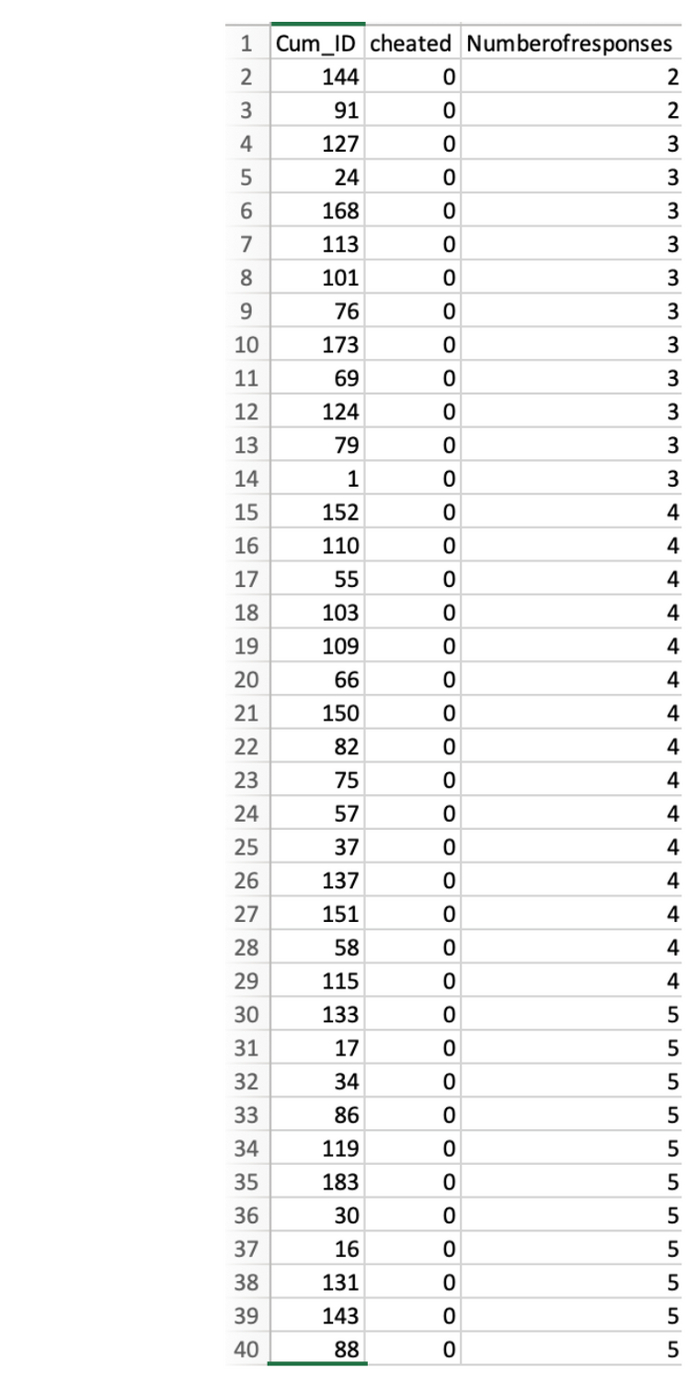
База практически идеально отсортирована по двум столбцам: сначала по столбцу «Обманывали», указывающему, обманывали ли участники в задаче на подбрасывание монеты (0 – не обманывали; 1 – обманывали), а затем по столбцу «Количество ответов», в котором указано, сколько вариантов использования газеты придумал участник.
Как и в первом расследовании, тот факт, что сортировка почти идеальна, и палит всю контору.
Давайте посмотрим, как сортируются данные. На приведенном ниже скриншоте показаны первые 40 наблюдений. Поскольку данные сначала сортируются по столбцу «Обманывали», все эти наблюдения представляют НЕмошенников, у которых, соответственно, в этом столбце 0 баллов. И далее они прекрасно сортируются по столбцу «Количество ответов» – все 135 человек.
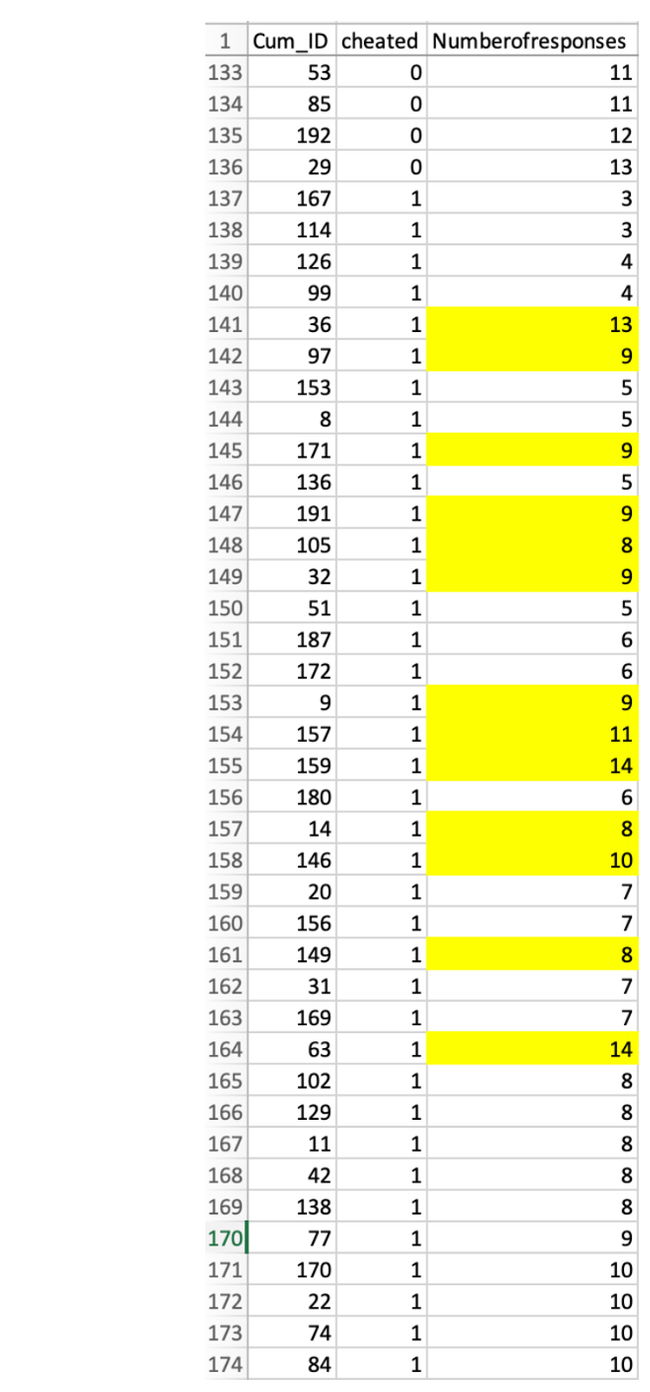
Посмотрим теперь на обманщиков.
О нет: несмотря на то, то 43 обманщика также отсортированы по числу ответов, среди них есть 13 наблюдений, расположенных не в том порядке, в котором они должны быть.
Это дает основание заподозрить, что эти 13 наблюдений были изменены вручную после сортировки для получения желаемого эффекта.
Здесь важно отметить три вещи
1. Не представляется возможным отсортировать набор данных таким образом, чтобы получить порядок, в котором находились данные. Они либо были первоначально введены таким образом (что маловероятно, поскольку данные исходно были файлом Qualtrics [онлайн-платформы для исследований], который по умолчанию сортируется по времени), либо они были изменены вручную.
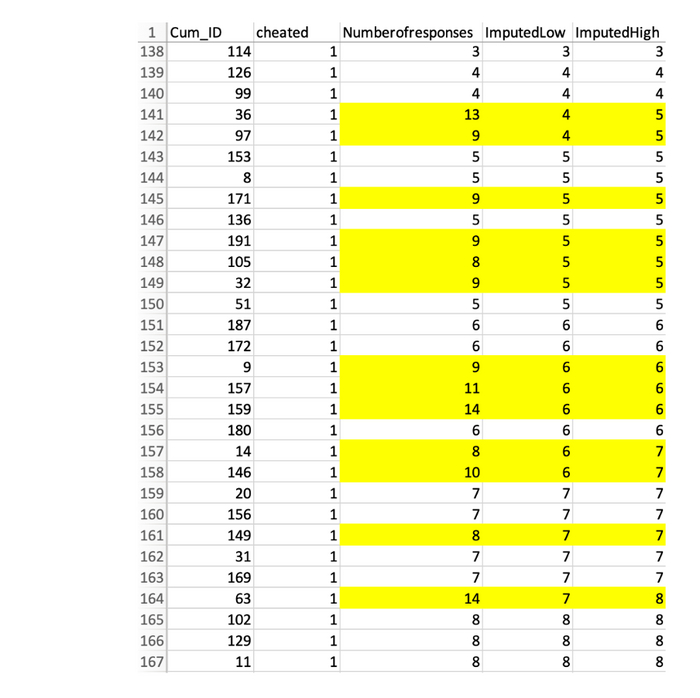
2. Напомним, что строки сортируются по столбцу «Количество ответов». Если значения, которые находятся не по порядку, были изменены, несложно выяснить, какими они были исходно. Например, в строке №141 есть «13». Строка над ней имеет «4», а первое по порядку значение после нее — «5». Следовательно, если данные были изменены, то можно предположить, что эта «13» раньше была либо «4», либо «5».
3. Появится чуть дальше, а сначала
Попробуем догадаться, как выглядели исходные данные
Ниже вы можете увидеть два новых столбца — «Предполагаемый минимум» и «Предполагаемый максимум», в которых есть два предполагаемых значения. В некоторых случаях точно известно, какое число менялось, в некоторых – оно находится в пределах ±1.
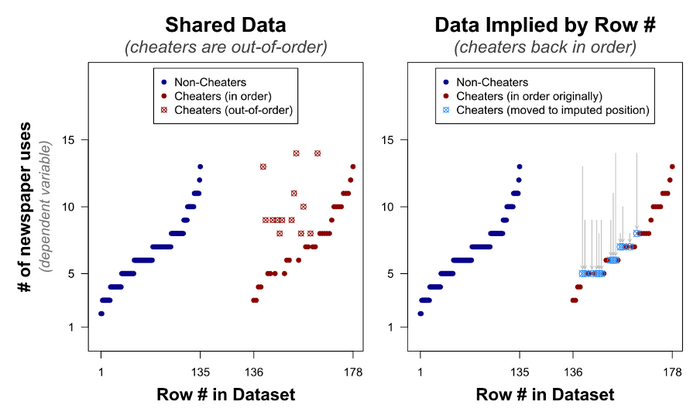
Посмотрим, есть ли различия между выложенным-сфальсифицированным датасетом (слева) и предположительно-реальным (справа) на графиках:
3. Существенная связь между мошенничеством и творчеством исчезает, когда вы анализируете предположительно-реальные значения, а не выложенные Джино и соавтором. Значение p меняется от < ,0001 до ,292 (для предполагаемых минимальных значений) и p = ,180 (для предполагаемых максимальных).
Если бы значения не изменили вручную, никакой существенной разницы между мошенниками и немошенниками бы не было.
Далее будет более хардкорный анализ для интересующихся
Представим, что на самом деле нет никакой разницы между мошенниками и немошенниками в их способности придумать, как можно использовать газету.
При отсутствии фальсификации данных мы ожидаем не только, что среднее количество ответов будет одинаковым, но и что распределения целиком для обеих групп будут одинаковыми. Например, значение, которое находится на 20-м процентиле, должно быть одинаковым как для мошенников, так и для немошенников. И это также верно для 50-го процентиля, 80-го, 90-го и так далее.
Что ж, посмотрим на распределения обеих групп после фальсификации (слева) и предположительно-реальные (справа).
Тест Колмогорова-Смирнова для непараметрического сравнения целых распределений показывает p = ,456, что не позволяет отклонить гипотезу о том, что эти два распределения одинаковы (то есть они одинаковы).
Хорошо, но насколько впечатляет этот нулевой результат? Он принимается в качестве доказательства, что 13 наблюдений, «возвращенных к реальности» – на самом деле были сфальсифицированы.
Но, возможно, это неправда. Может быть, не имеет значения, какие 13 наблюдений вы измените? Что, если вы измените любые другие 13 наблюдений (из мошеннической группы) на ту же величину? Получим ли мы такие же похожие распределения и, например, такое же высокое значение p в тесте Колмогорова-Смирнова?
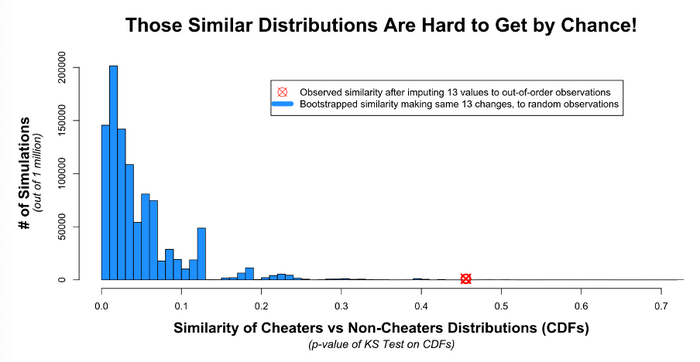
Data Colada провели несколько консервативных симуляций миллион раз. Каждый раз оценивалось сходство мошенников и немошенников с помощью теста Колмогорова-Смирнова и отслеживалось его p-значение.
Посмотрите на красную точку, обозначающую p-значение после изменения тех самых 13 наблюдений. Нужно было быть чрезвычайно, невероятно удачливым, чтобы выбрать именно их и получить настолько похожие распределения по группам исключительно случайно.
Не существует (почти) никакого другого набора из 13 значений, которые вы могли бы изменить на ту же величину, чтобы получить два настолько похожих распределения. Этот результат довольно убедительно подтверждает, что сфальсифицированные ячейки и их исходные значения были определены правильно.
«Мы считаем, что у Гарвардского университета есть доступ к файлу Qualtrics, который мог бы полностью подтвердить (или опровергнуть) наши опасения. Мы сообщили им, какой файл получить, какие ячейки проверить и какие значения они найдут в файле Qualtrics, если мы окажемся правы. Мы не знаем, сделали ли они это, и что они нашли, если сделали. Все, что мы знаем, это то, что 16 месяцев спустя они потребовали отозвать статью».
Четвертая часть расследования пока не вышла, но ждем с нетерпением!