


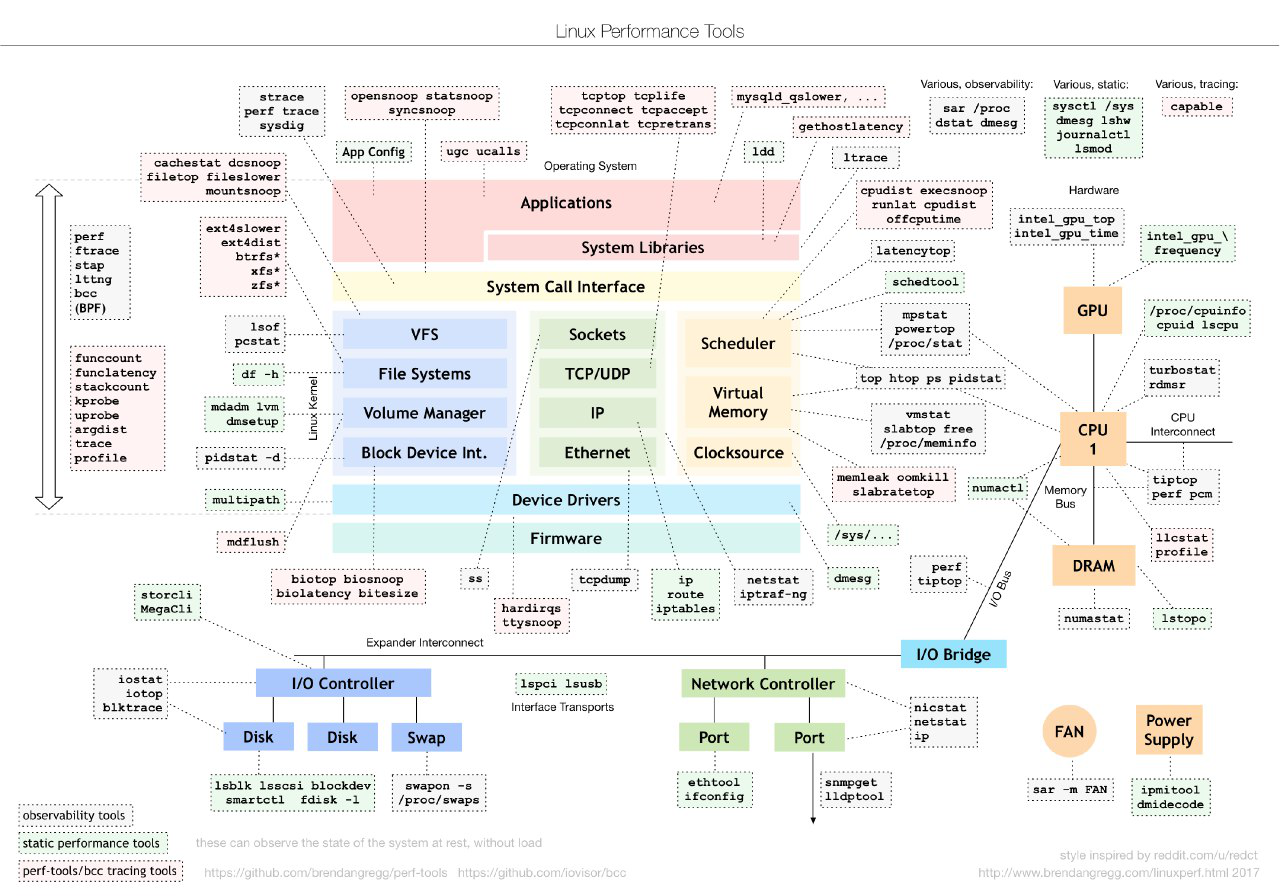
Памятка Linux админу по основным утилитам диагностики
UPD: В комментариях @rickardo подкинул ссылочку на качество
UPD: В комментариях @rickardo подкинул ссылочку на качество
Я на работе так делаю, если выяснение причины занимает больше получаса. Стандартный образ со всем необходимым софтом развертывается за 40 минут, да и готовые машины всегда есть в запасе. Юзеру мешать работать выясняя проблему можно часами. И да, что бы исключить проблему с железом, я просто меняю системный блок, а проблемный уношу на диагностику.
На самом деле в большинстве случаев да, проще переустановить. Причём что винду, что линукс. Разбираться имеет смысл если речь идёт о сервере, да и то бывают исключения. Ну либо если проблема массовая. В остальных случаях за 20 минут перенакатить образ будет существенно быстрее, чем выяснять что именно сломалось.
На рабочих станциях далеко не всегда SSD, а скорость развёртки ограничивается, обычно, сетью и загруженностью сервера образов.
Ну в настоящее время стоимость новых HDD сопоставима со стоимостью SSD. Да, размеры будут различаться, но в корпоративном секторе это не критично. Все файлы должны лежать на файловом сервере а не на компах пользователей. Плюс надёжность SSD, как показывает практика, значительно выше
Харды расходный материал, поэтому перевести большую часть рабочих станций на SSD - вопрос пары лет.
Если упирается в сетку или загруженность сервера образов - значит либо они устарели, либо изначально были спроектированы неправильно.
Хотя я вполне понимаю, что у нас есть куча контор, которые в следствии скупости руководства или принадлежности к госсектору не имеют таких возможностей и приходится работать с тем, что есть.
> Все файлы должны лежать на файловом сервере а не на компах пользователей
Огонь горячий, а вода мокрая.
> Харды расходный материал, поэтому перевести большую часть рабочих станций на SSD - вопрос пары лет.
Если пользовательские машины стоят и работают, никто не будет их прото так менять.
> Если упирается в сетку или загруженность сервера образов - значит либо они устарели, либо изначально были спроектированы неправильно.
Ну нафига на пользовательских системах гигабит? Чисто ради того, чтобы время от времени образ переразворачивать на 10 минут быстрее? Тем, кому он необходим, он проведён.
SSD может вдохнуть вторую жизнь и в старое железо.
Ну а гигабит штатно в материнки встраивают уже лет 10.
Разница в ценнике между 1GB и 100MB сетками минимальна.
Вариантов развития сети при 1GB куча. Например перевод сотрудников на тонкие клиенты существенно снижают затраты.
Пользовательские машины имеют тенденцию ломаться. И именно харды вылетают практически чаще всего. Конкуренцию им составляют разве что БП.
> Разница в ценнике между 1GB и 100MB сетками минимальна.
Разница в стоимости коммутаторов примерно двухкратная. Хотя в целом соглашусь - современную сеть имеет смысл делать гигабитной.
> Вариантов развития сети при 1GB куча. Например перевод сотрудников на тонкие клиенты существенно снижают затраты.
Тонкие клиенты, требующие гигабитный поток? Это где такое чудо?
> Пользовательские машины имеют тенденцию ломаться. И именно харды вылетают практически чаще всего. Конкуренцию им составляют разве что БП.
Возможно, но они не настолько часто ломаются, чтобы проапгрейдить весь парк компьютеров в обозримые сроки.
> Тонкие клиенты, требующие гигабитный поток? Это где такое чудо?
Когда в начале рабочего дня пол сотни машин лезет грузить загрузочный образ, к примеру. Бездисковые рабочие станции поднимали?
> Разница в стоимости коммутаторов примерно двухкратная.
Бегло глянул на никсе. Идентичные устройства в гигабитном исполнении дороже примерно на треть, а не в половину.
Да и стоимость самого коммутатора не самый существенный пункт в смете локалки. Если это не локалка на 10-20 компов в маленьком офисе.
> Возможно, но они не настолько часто ломаются, чтобы проапгрейдить весь парк компьютеров в обозримые сроки.
Так главный вопрос начать. Нет, конечно найдутся самые стойкие машины, но если основной парк с пробегом 3-5 лет обновления хардов будет идти довольно бодро.
Минусующим: представьте что у вас рабочий день и довольно много задач - какой смысл тратить несколько часов на выяснение почему у пользователя глючит офис, если очевидно что это локальная проблема, а запустить reimaging занимает несколько минут и доступно техподдержке? То есть если дел нет, можно поковыряться, но обычно есть что-то более важное, чем можно заняться.
То же самое, например, с контроллером домена (если проблема не касается непосредственно AD) - смысл выяснять почему он не грузится, если можно его быстро и без последствий переставить? Сервера приложений, баз данных и т.п., обычно можно восстановить из бэкапа без потери данных.
Понятно, что это относится к ситуациям когда проблема связана с ОС/железом, а не с самим сервисом, но таких проблем хватает и тратить на них время нет смысла.
Для проф целей есть более удобный инструментарий. Например виртуализация всего и вся с репликацией виртуалок. Ёбнулся сервер? Поднялась реплика.
Ещё лучше кластер замутить....
Эммм... ни реплика, ни кластер не замена бэкапа. И если у вас навернулась виртуалка, реплика в принципе может помочь, но не всегда и сильно зависит от настроек репликации. А кластер в этом случае вам вообще не поможет.
(ЗЫ, чтобы не порождать недопонимание: я имею в виду "навернулась система внутри виртуалки", а не хост виртуализации или хранилище).
Есть. НО я и не утверждал, что это панацея. Просто один из вариантов оптимизации инфраструктуры.
linux как раз от винды тем и отличается что он просто так не ломается, для этого нужно либо что то изменить либо обновится. А если что то не хочет работать, то переустановка не поможет
> либо обновится
> просто так не ломается
Забавно
> для этого нужно либо что то изменить либо обновится
Внезапно, это и к винде относится.
Я не знаю что нужно делать с серверной виндой, чтобы всё это происходило. На практике, если не считать сбоев железа, случаев когда линукс при старте говорил "Ой, не могу смонтировать root" или по другим причинам уходил в невменяемое состояние, было как минимум не меньше, чем с таких проблем с виндой.
Вот, кстати, сходу не вспомню когда винда ломалась от этого (а серверов с виндой у нас довольно много), а вот у линукса любое обновление - это приключение, и иногда с фатальным исходом.
Из десктопного - свежий релиз десятки.
У серверной винды у меня однажды был случай. Но давненько было, и уже не вспомню, с каким конкретно обновлением это было связано. Благо, в тестовой группе было.
> Из десктопного - свежий релиз десятки.
Так не о десктопе же речь.
> У серверной винды у меня однажды был случай.
Я допускаю что могут возникнуть проблемы с обновлением, но именно как исключения.
Я, в основном, при сбоях загрузки наблюдал проблему с аппаратурой: глючный биос, сбой материнки, проблемы с дисками - это, наверно, 90+% случаев. Бывает сбой питания, или юзеры с шаловливыми ручками и физическим доступом к серверу (на филиалах) - но обычно это приводит только к кратковременному простою, пока сервер загружается.
Софт, который может привести к проблемам - пожалуй только антивирус, остальное всё, обычно, не настолько глубоко залазит в систему. Но даже с антивирусом это весьма редкое явление.
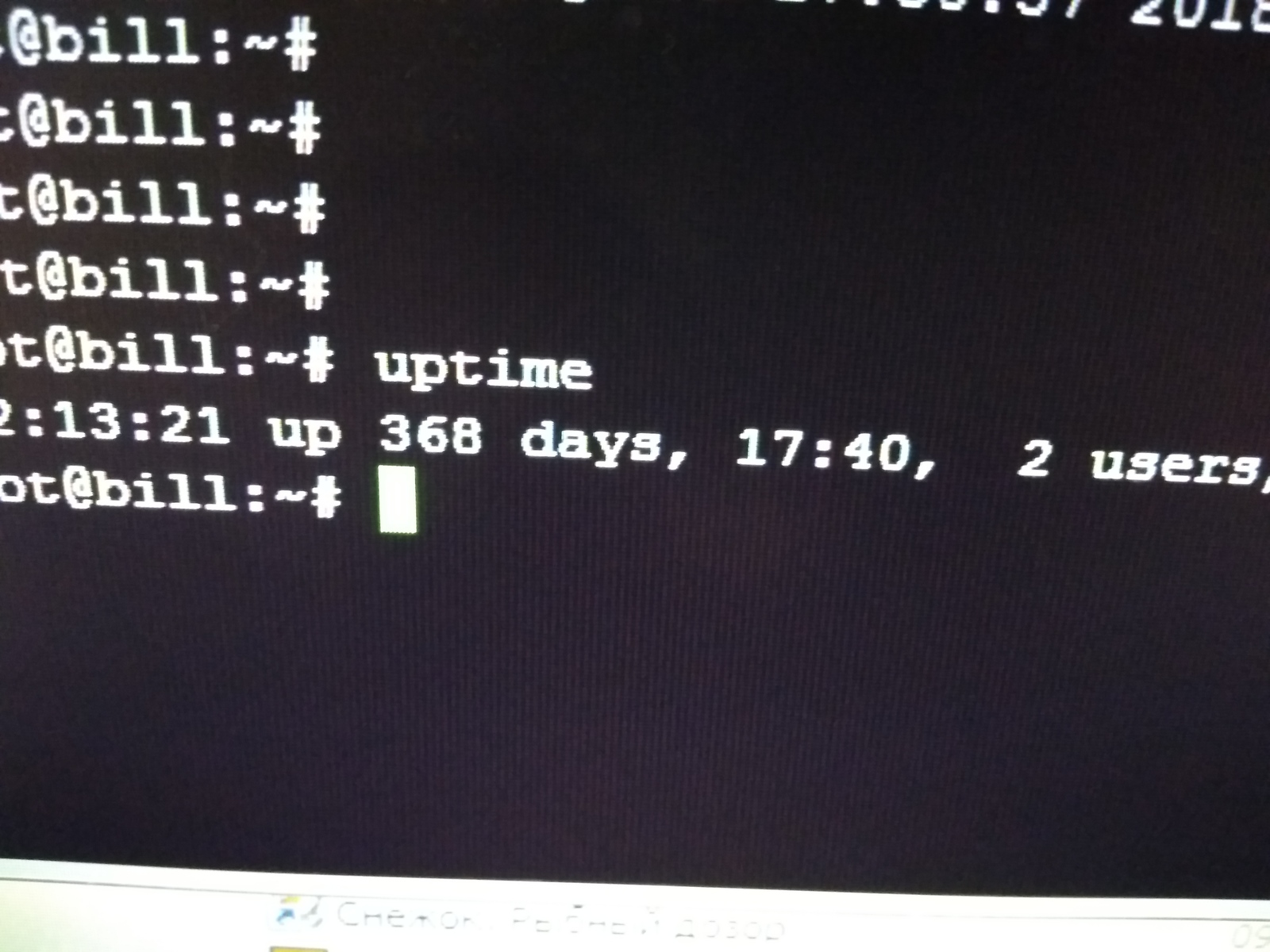
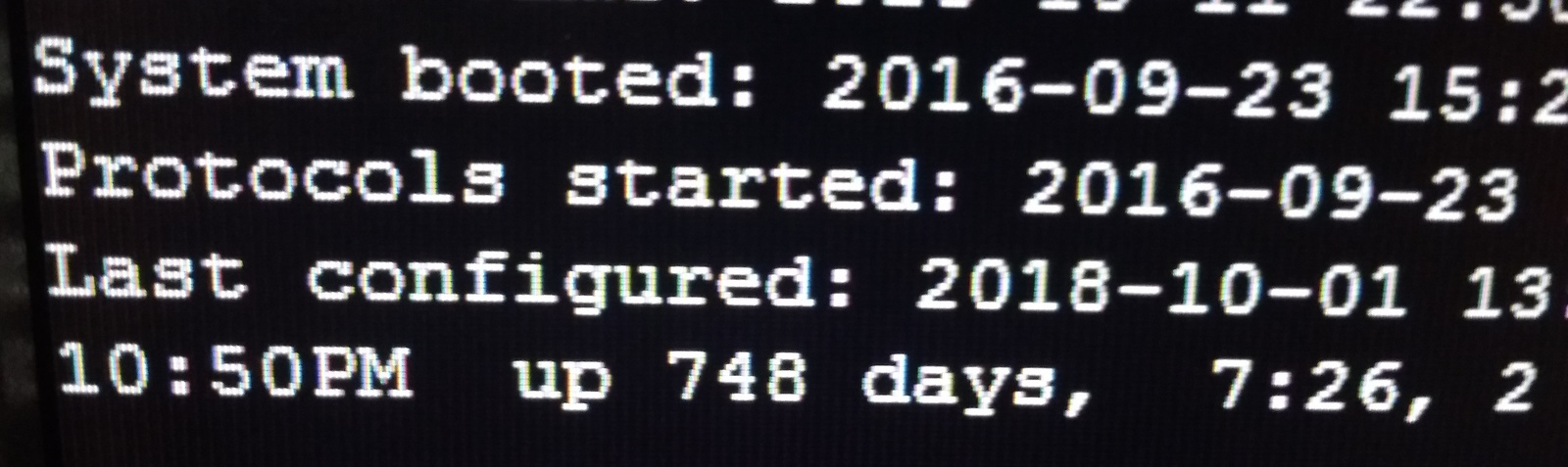
А смысл в таком аптайме? У нас сервера для установки обновлений примерно раз в месяц перезагружаются.
А я за шо? А если не обновится и не перезагрузить, что будет?
Смысл в том, что услуга не прерывается. На конкретно этом сервере кнопку включения нажимали 3 раза с 13 года, винты меняли, а нагрузка там ого-го. А рядом стоит виндовый сервер, практически без нагрузки, его раз 5 за два года переустановил, и раз 100 перезагрузили.
> А если не обновится и не перезагрузить, что будет?
Да ничего, только какой в этом смысл? Ну стоял сервак с 2003 виндой, как выяснилось без перезагрузок больше года. И что это доказывает?
> Смысл в том, что услуга не прерывается.
И?
> А рядом стоит виндовый сервер, практически без нагрузки, его раз 5 за два года переустановил, и раз 100 перезагрузили.
Значит либо железо кривое, либо руки.
Если нужны услуги с 99.999% то в любом случае реализуется отказоустойчивость, и в любом случае выделяется время на техработы. Так что про линукс с диким аптаймом лучше сказать, что он для сервисов, которые если упадут, то никто этого не заметит достаточно долго для их восстановления. И для которых не сильно важно исправление ошибок и уязвимостей.
Желаю вам что бы ваш провайдер поставил себе биллинг на винду, тогда не сможете всякую чушь в интернете писать
Отлично - как что не по вашему, так сразу истерика. Сказал бы что линуксоиды такие, но, к счастью, знаю достаточное количество адекватных линуксоидов чтобы не делать такие выводы.
> Какая истерика?
> вы.. ...тогда не сможете всякую чушь в интернете писать
> разговор админа с 1сником)))
Вот такая - нет аргументов, а только истерическое "чушь пишешь", "1сник".
Ну а что я могу сделать если вы пишите чушь? На вас подействуют доводы, что google, yandex, amazon да и практически все сервисы в интернете используют linux? Или то что если перезагрузить тот сервер который я вам показывал то будет прерывание услуги для 70 тысяч человек? Не думаю что это возымеет какое-то действие. А смысл серьезно разговаривать с человеком который спорит о том в чем не разбирается? 1сник он и в Африке 1сник, все лечит перезагрузкой или переустановкой
> Ну а что я могу сделать если вы пишите чушь?
А не могли бы вы конкретизировать, что именно счиаете чушью: что систему нужно обновлять? Или что система с требованием постоянной доступности должна поддерживать отказоустойчивость? Что надо обслуживать сервера? Что аптайм не более чем фаллометрический показатель?
Просто то что вы пишите фактически классический пример аргументации админа локалхоста: Винда отстой! Гугль, Яндекс, Амазон используют линукс! Если ты с этим не согласен то ты не разбираешься и вообще 1Сник!
> Или то что если перезагрузить тот сервер который я вам показывал то будет прерывание услуги для 70 тысяч человек?
То есть, если завтра у вас на сервере, допустим, всдуется конденсатор - то ваши "70000 человек" спокойно подождут конца ремонта?
Перецитирую себя: "Так что про линукс с диким аптаймом лучше сказать, что он для сервисов, которые если упадут, то никто этого не заметит достаточно долго для их восстановления"
Я же говорил не подействует)
Как раз эта ваша цитата и есть чушь.
Конденсатор там взутся не имеет никаких шансов, питание с двойным преобразованием, шестикратного резервированное и сам сервер собран далеко не из б/у запчастей. Но если он все таки выйдет из строя, то рядом стоят ещё 3, они все подхватят, но в силу больших потоков данных на это уйдет не меньше минуты, а минута это критично, и именно поэтому там стоит линукс который будучи грамотно настроен сам по себе никогда не падает.
И ещё раз по поводу вашей цитаты. Решения о использовании программных продуктов для критичных сервисов принимаются не просто так, потому что кто-то что-то не любит или кому-то что-то удобно. Проводится анализ, тестирование, сравнение, учитывается опыт эксплуатации, мнение различных специалистов. И выбор линукса практически всеми участниками отрасли далеко не случаен. Так что ваша цитата как раз относится к продуктам Майкрософта. Винду можно поставить там где нет критических нагрузок, где можно позволить перезагрузиться в любой момент, где не нужно online резервирование. Ниша винды это информационные сети предприятий, документооборот, видеонаблюдение и т.д.
> Как раз эта ваша цитата и есть чушь.
Но на вопрос что именно из перечисленного чушь, вы так и не ответили.
> Конденсатор там взутся не имеет никаких шансов, питание с двойным преобразованием, шестикратного резервированное и сам сервер собран далеко не из б/у запчастей.
В смысле это самосборный сервер? Мда...
> Но если он все таки выйдет из строя, то рядом стоят ещё 3, они все подхватят, но в силу больших потоков данных на это уйдет не меньше минуты, а минута это критично
Судя по описанию вы говорите о CDN для порносайта. Ну да, тут клиенты действительно ждать не будут.
> И выбор линукса практически всеми участниками отрасли далеко не случаен.
С учётом того, что стало понятно о какой отрасли идёт речь, вынужден согласиться - в этой отрасли действительно линукс рулит.
> . Винду можно поставить там где нет критических нагрузок, где можно позволить перезагрузиться в любой момент, где не нужно online резервирование.
Забавно слышать как кто-то повторяет твои слова (насчёт резервирования), не понимая в этом вообще ничего.
> Какие порно сайты?
> они все подхватят, но в силу больших потоков данных на это уйдет не меньше минуты, а минута это критично
Это описание Video CDN. И за пределами ютуба не так уж много сайтов занимаются раздачей непорнографического видео контента. Либо предложите свой вариант.
> Какой самосбор?
Вы вместо написания модели (или хотя-бы производителя) сервера говорите что он "сервер собран далеко не из б/у запчастей" - как это ещё называть?
> Вы прикидываетесь, или действительно такой?
Вы так и не ответили ни на один поставленный вопрос.
Так я вам отвечаю, вы читать читаете, а понять не можете, что то у себя в голове придумываете и выливаете это на меня. А уже сильно сомневаюсь в вашей адекватности.CDN какой то придумали, порнографию прикрутили
Ну так скажите свою версию, для чего именно у вас 4 сервера и 70000 человек нагрузки (интересно за какой период). Потому что пока вы выглядите как завравшийся админ локалхоста, троллить которого становится всё скучнее и скучнее...
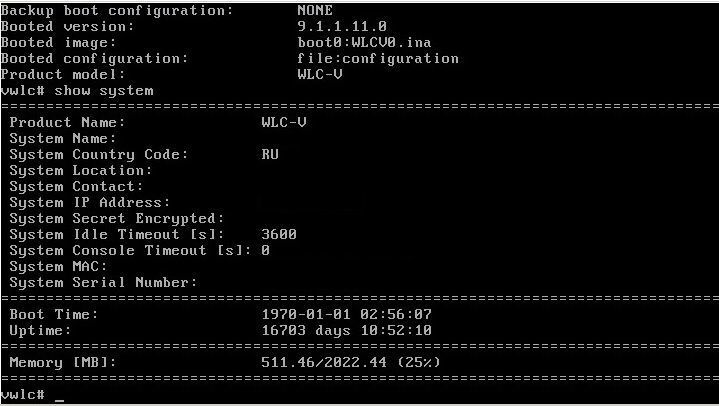
А, так это троллинг такой. Простите, я уж грешным делом подумал что вы просто глуповатый , хотя эту версию отметать так сразу наверное не стоит. Если бы вы хоть что то понимали в том чем так искрометно тролите то догадались бы по фотографии что это биллинг. А биллинг бывает у провайдеров услуг. В данном случае это биллинг оператора связи, и 70000 человек это единовременно.
Супермикро продаёт платформы. Т.е. по факту от самосбора не далеко ушло. Да и железо не самое лучшее, если честно. Бренды первого эшелона повылизанней будут.
Я другое имел ввиду. Если вы говорите "даже", значит это самое худшее из того что можно предположить))).
На счёт кластера, Майкрософт только недавно решил проблему с простоем при смене ролей, да и то в кластере типа sql все равно простой до 5 минут
На линуксе все в разы проще, база, реплика, два экземпляра биллинга на каждом сервере и vrrp. Красиво, изящно и работает без перебоев. Про минуту простоя я написал для того что бы быть честным, один раз во время тестов была такая задержка, больше не повторялось.
Ну, чисто технически существуют и fault tolerant серверы. Где отказоустойчивость организована аппаратно. Сам не сталкивался, но читал про такие.
Простой при использовании какого SQL Server'a? MSSQL? Oracle?
Хотя Oracle сейчас больше рекомендует собственный дистрибутив Linux'a.
Есть такие серверы, но стоят мама не горюй. Я уж лучше двухметровую стойку обычными забью.
Sql server это тип кластера такой, работает ли он с ораклом не знаю, и проверять лень.
Не, я понимаю, что это кластер SQL. Подобные решения есть и у MS и у Oracle. Причем, у последнего вроде бы даже простоя нет. Хотя, не мой профиль, так что гарантировать не могу.
Впрочем, емнип, эта фича есть только у Enterprise редакции. Лицензия которой стоит 47,5К$ за сокет.
Есть и у оракла и у vmware и работают лучше huperV, стоят конечно неприлично дорого, но дело не в этом, поприетарное ПО не отличается гибкостью и требует узкопрофильных специалистов.
Vmware, по сравнению с Oracle, стоит неприлично дёшево. А Hyper-V - так вообще практически даром.
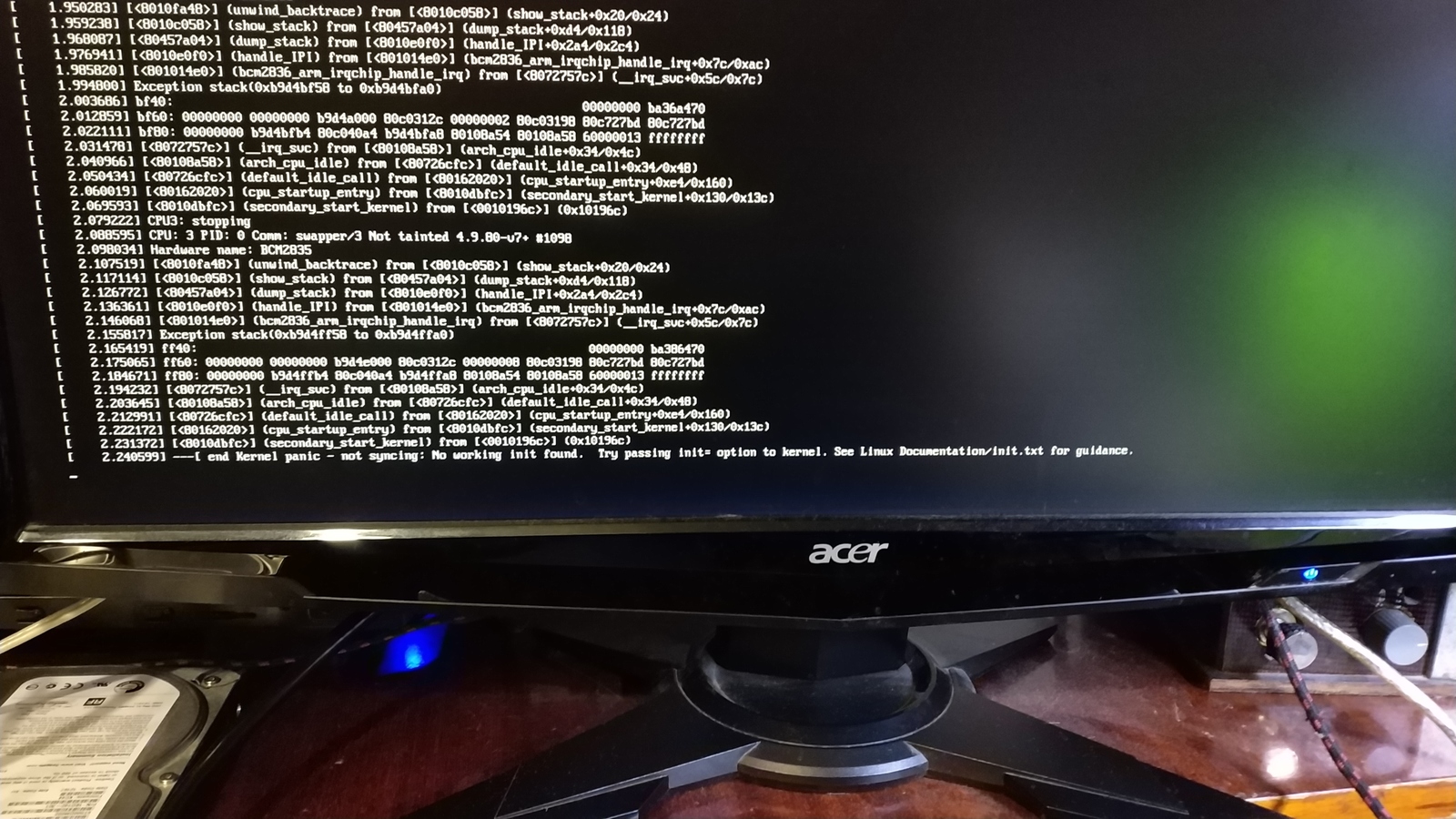
Ой, да ладно! Не ломается там, ага. Ну вот на вскидку с чем сталкивался, проблема с debian. После ребута просто отказался грузиться, выдав вот такой паник. И в чём тут дело?
Ага, знакомая история "Мы ничего не делали, оно само". root partition он у вас не видит. А почему, вспоминайте сами.
Это сервер, на котором крутился сайт. Перезапуск плановый, так что да, оно само. После очередного планового перезапуска сервер не поднялся.
Какая разница? Сбой электропитания, подвисший nginx, левая пятка начальника. Знаю только что оно работало до ребута, но было недоступно по rdp.
Сбой электропитания это плановая перезагрузка? Если у вас виснет nginx и вы лечите это плановой перезагрузкой, поздравляю, ваш админ вообще не отдупляет то чем занимается. А про левую пятку начальника вообще чушь.
Я вам расскажу как было на самом деле. Перезагрузку вы запланировали далеко не просто так, кто то натыкал своими кривыми рученками и перезагрузил, а оно не поднялось и теперь linux оказывается плохой, и я заодно с ним)))
Ты же говорил что плановый...
Сбой питания может привести в повреждению ФС и получаем панику.
Повисший Nginx как бы не причина для ребута. Да и на "работало до ребута" не тянет. Но если он повис из-за проблем с SD-картой, результат немного предсказуем.
Левая пятка начальника вообще зло.
Работал себе сервер, держал nginx, но по xrdp не доступен. Работает - не трогай, но у него есть плановая перезагрузка, после которой он не поднялся.
По итогу мы видим всё как обычно. Сервер который фиг знает как упал и никакими силами уже не поднимается и обвинения в криворукости. А линукс тут не причём.
Типичное линуксовое Ру комьюнити.
Ну вот опять... Он работал, но был недоступен. Ты уж определись, были ли проблемы до ребута.
По сути - у тебя малинка, которая прочитала ядро, но не может прочитать инит. Это или битая ФС, или умирающая карточка. Или ты правда ждал точный диагноз по фото?










GNU/Linux
1K постов15.5K подписчик
Правила сообщества
Все дистрибутивы хороши.
Будьте людьми.