

Особенности национального проектирования БД
Ковыряли таблицы на работе на предмет того как заполняются анкеты клиентов, попалось на глаза интересное описание поля
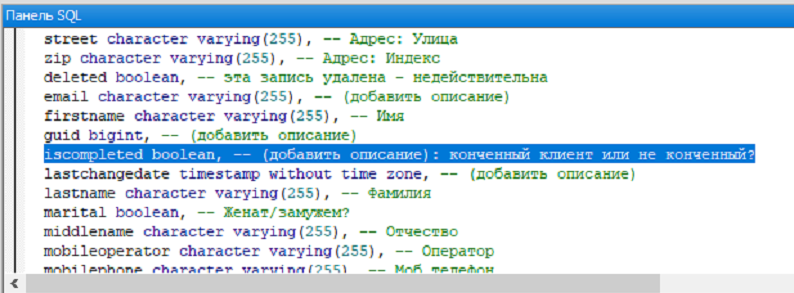
Ковыряли таблицы на работе на предмет того как заполняются анкеты клиентов, попалось на глаза интересное описание поля
1. bigint для guid не хватит
2. MobileOperator - нормализировать
3. Marital - на int8 перевести, если нет, то на smallint, т.к. практика показывает, что потом добавится "разведён", "вдова" и прочее
4. deleted заменить на state, тоже такого же типа, как в 8, и там уже статусы расписать: new, changed, syncronized, deleted, etc.
5. Сабжевый iscompleted также заменить на int и хранить там enum признаков: "конченый", "не платит вовремя", "много пиздИт", "много пИздит", etc
2. Зависит от назначения. Если эти данные используются только для отображения вместе с юзером и важна скорость выборки то незачем это делать.
4. Вполне возможно что запись может быть new и в тоже время удалена. Лучше таки этот флаг отдельно хранить.
5. isCompleted лучше переименовать в completed по аналогии с deleted
2. Зависит от назначения. Если эти данные используются только для отображения вместе с юзером и важна скорость выборки то незачем это делать.
Даже если только для отображения - вытащить маленький список на клиент и им заполнять комбики
Вполне возможно что запись может быть new и в тоже время удалена
Если она и new и удалена, и оба два надо хранить - храни enum, нафиг лишние поля плодить?
4. deleted заменить на state, тоже такого же типа, как в 8, и там уже статусы расписать: new, changed, syncronized, deleted, etc.
1. если syncronized - признак обмена, то какого лешего его хранить в том же поле, что и new, changed, deleted?
2. new, changed - нет смысла хранить, они вычисляются по полю типа дата/время последней модификации (lastchangedate).
так что deleted - там единственное поле без косяков (+lastchangedate)
остальные поля определены через жопу: то слишком большое, то маленькое, то строка вместо справочника.
Думаю разработчик БД из вас так-себе.
И DBA вправе набить морду "автору" этой таблички..
Я так полагаю что хранить строку фиксированной длинны проще с точки зрения её обработки, извлечения и хранения. Меньше нагрузка на проц и диск, отсюда и прирост скорости.
Т.е. там еще и лузерский выбор хранения данных?
извините, не заметил.
Я так полагаю что хранить строку фиксированной длинны проще с точки зрения её обработки, извлечения и хранения. Меньше нагрузка на проц и диск, отсюда и прирост скорости.
Мне дико интересно, а откуда такая информация взялась?
И да, всем апологетам "для ФИО достаточно 32 символов на каждого" стоит учесть, что однажды к вам придёт Максимилиан Иоганнес Мария Губертус рейхсграф фон Шпее.
Ага, то есть всех Ивановых, Сидоровых, Кузнецовых и прочих мы будем в char(100) хранить. А like-поиск вести не только по фамилии, но и по комментарию.
Охуенно, чо.
Твоя реализация - полное г....
Иди кури курс по реляционкам.
В моем случае в поле коментарий забивается нормальное ФИО, юзер делает тикет в трекере, я фиксю и альтерирую табличку, потом юзер исправляет так как надо.


