
Частота букв в русском языке
Буквы
Нам с коллегой Владимиром Терентьевым внезапно показалось любопытным узнать, как и как часто мы в русском языке используем те или иные буквы. Для этого был проанализирован Полный орфографический словарь русского языка.
Какая буква на каком месте?
Первая задача была в том, чтобы показать распределение использования буквы в разных частях слова.
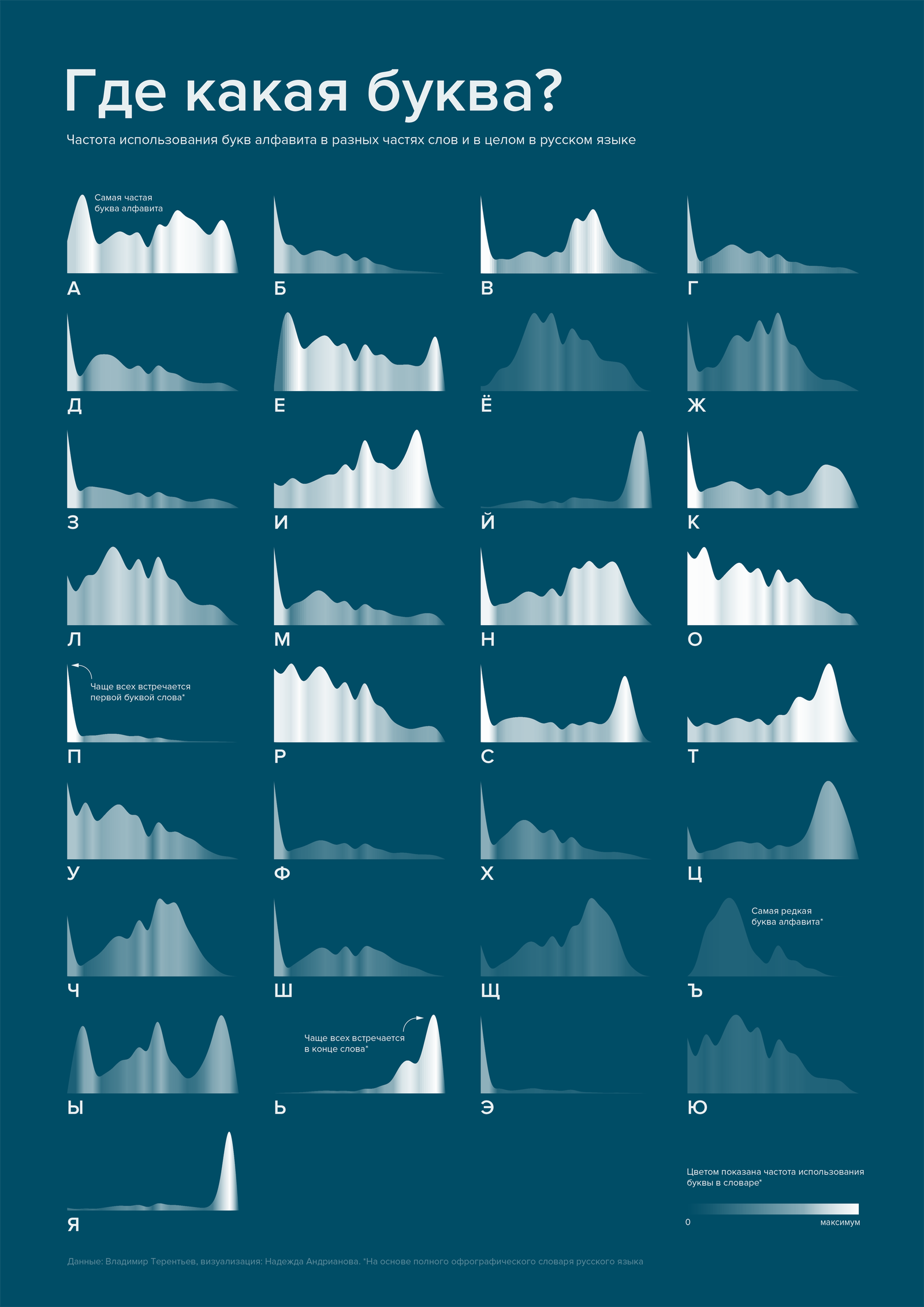
В качестве единиц измерения используется коэффициент: полученные данные были пересчитаны так, чтобы оценить положение буквы относительно слова, при этом не учитывая его длину. Кстати чаще всего в словаре встречаются слова из 9 и 10 букв, но попадаются и длиной в 29 знаков.

Как буквы сочетаются?
«Ть, ть, ть», — повторило привычное эхо
Еще нам показалось интересным узнать, как буквы сочетаются с другими, и какие пары используются в словах русского языка чаще.
В данном случае уже можно говорить о буквальной частоте встречаемости пар как о единицах измерения. Однако, я сохранила преемственность в легенде.

Свой финальный выбор я остановила на хитмапе. Изначально идея была визуализировать размерами букв, получить, фактически, облако сочетаний знаков. Однако, из-за сложности форм она не сработала, читаемость как данных, так и самих букв была очень низкой. Естественно, я попробовала с более простыми формами и сделала пузырьковую диаграмму, но полученный результат эстетически меня не устроил.
Nadya Andrianova















