Видео запеченное с данными, вам с каким соусом подавать?
Приветствую жителей уютного мира Пикабу и людей которые решили на меня подписаться.
Пишу в продолжение к моему предыдущему посту о программе для запихивания и извлечения произвольных файлов (данных) внутрь видео файлов.
Предыдущий пост http://pikabu.ru/story/vpikhivaet_lyubyie_dannyie_v_video_il...

Цель данного поста - спросить у вас что вы хотели бы в данную программу добавить, а что изменить.
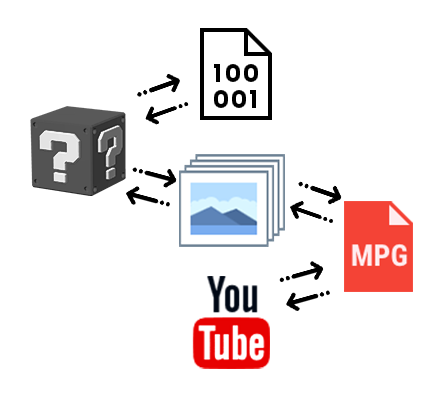
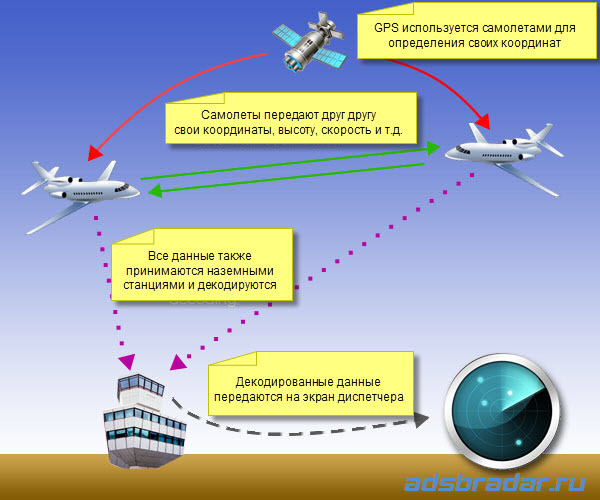
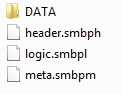
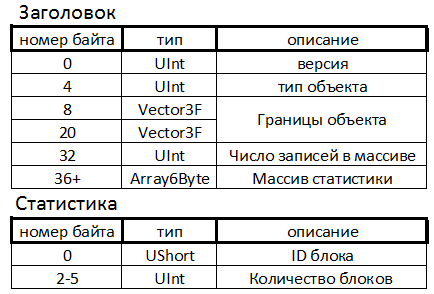
На данный момент я заканчиваю переписывать внутреннюю структуру алгоритма с бOльшим упором на модульность под вдохновением используемой в некоторых программах системы нод. Конечно, до структур как в Blender или UE4 мне еще далеко. Получается что-то вроде как на этой картинке.

Это значительно облегчит мне добавление новых плюшек и выбор существующих согласно настройкам пользователя.
К слову, также я решил обособить заголовок данных - информацию о параметрах файла (имя, размер) - от самих данных, и теперь заголовок кодируется в более помехоустойчивом режиме чем сами данные. К тому же в заголовок добавлена информация о режиме кодирования, так что теперь не придется вручную выставлять настройки для декодирования.
Сейчас внутренняя структура уже может повторить алгоритм реализованный в предыдущей версии, остается переделать обвязку "морды" программы для соответствия внутреннему миру.
Так же я решил избавить пользователя от выбора формата пикселей (теперь по умолчанию используется YUV420P, но внутренности все еще позволяют его изменять) и добавить новые опции - выбор пресета кодирования H264 (влияет на соотношение скорость/размер/качество) и выбор режима постоянного битрейта или постоянного качества (те кто занимался перекодированием видео или стримом игр уже знакомы с этими настройками)

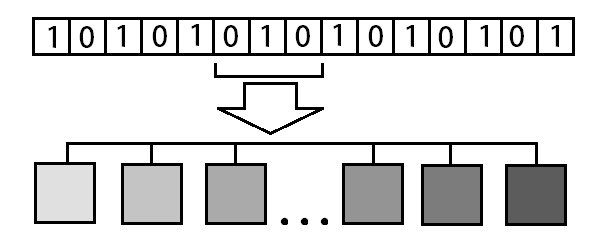
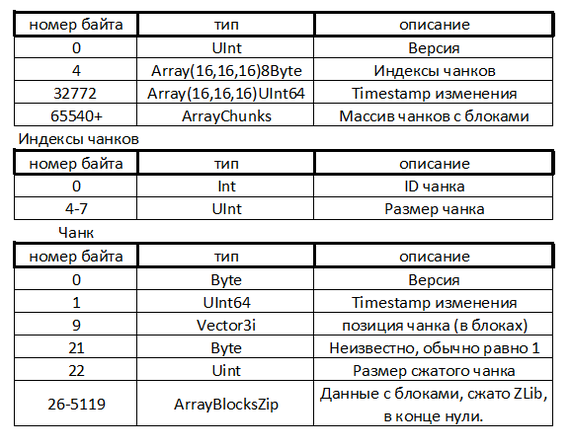
Ах да, еще один пункт добавился. Реализованный ранее алгоритм позволяет запихнуть в квадрат 8х8 лишь несколько (Density) бит информации и только один раз. Но я тут пыхнул правильной травы переосмыслил прочитанные ранее алгоритмы используемые для несколько иной задачи и сделал заготовку для использования дискретного косинусного преобразования (DCT), и тут получается что в квадрате 8х8 появляется сразу несколько ячеек (Cell Count) куда можно вставить наши биты (Density). При числе ячеек = 1 будет использоваться предыдущий алгоритм, если > 1 то алгоритм c DCT
Следующая картинка визуализирует влияние чисел дискретного косинусного преобразования на получаемую картинку, каждый квадратик соответствует отдельному числу в матрице 8х8:
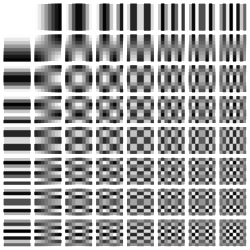
Правда, на практике испытания я провести еще не успел и данный алгоритм еще только предстоит приспособить к текущей структуре программы и понять можно ли его вообще использовать в реальных условиях.
Собственно, после проверки работоспособности данного алгоритма и я собираюсь выпустить следующую версию программы.
А теперь вопросы к вам, дорогие читатели:
Добавить сжатие? А надо ли? Думаю, пользователь и сам может заранее сжать файл если хочет. Ну, так то можно опционально (по выбору пользователя) делать поблочное сжатие входного файла каким-нибудь ZIP.
Как вы думаете как будет лучше сделать визуализацию оценки возможной ошибки для показа пользователю? В последней версии пользователю выводилась только максимальная из всех найденных оценок ошибки в виде дробного числа от 0 (лучше некуда) до 1 (скорее всего есть ошибки).
Поясню - на стадии вытаскивания информации из кадров есть возможность примерно посчитать отличие получаемого числа от идеала. Получаемая оценка - что-то вроде отношения сигнал-шум которое строится без использования проверки на наличие ошибок.
Например, можно сделать шкалу распределения шума в файле, но нужны ли такие сложности...
Восстановление ошибок - да, я помню, в комментариях к прошлому посту мне советовали его реализовать, в планах добавить (опциональный) код Рима-Соломона или что-то другое. Займусь этим после реализации алгоритма с DCT.
Стеганография... тоже можно попробовать, только не понятно какой алгоритм в данном случае лучше использовать. Но это добавлять только в самом-самом конце после всех остальных плюшек, если только не найдется алгоритм на добавление которого не потребуется много времени и он окажется в достаточной мере скрытным.
Что-то еще визуализировать? Как это должно выглядеть?
Добавить еще что-то полезное или интересное в алгоритм?