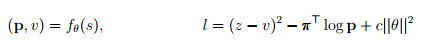Ведение
Игра в шахматы наиболее хорошо изученная сфера в истории искусственного интеллекта. Лучшие шахматные программы базируются на сложных техниках поиска, предметно-ориентированных адаптациях и оценочных функциях, которые давали эксперты по шахматам целые десятилетия. В противоположность этому AlphaGo Zego недавно достигла сверхчеловеческого мастерства игры в го с помощью переобучения с "чистого листа" во время игр против самой себя. Ниже мы покажем этот подход в отдельном алгоритме для программы AlphaZero, которая может достичь сверхчеловеческого мастерства во многих сферах. Начиная со случайных ходов и абсолютно без каких либо дополнительных знаний, кроме правил самой игры, AlphaZero достигла за 24 часа сверхчеловеческого уровня игры в шахматы и cёги (японские шахматы) настолько хорошо, насколько этого удалось достичь ранее в го, и затем AlphaZero убедительно сокрушила считающуюся мировым чемпионом программу в каждом из случаев (шахматы, сеги, го).
*В оригинальном тексте AlphaZero - это "алгоритм", в переводе я постарался употреблять AlphaZero в значении "программа", потому что так лучше звучит на русском. В итоге получилось, что AlphaZero и другие подобные названия могут употребляться как в значении "алгоритм", так и в значении "программа". Пожалуйста не путайтесь и не благодарите. Также AlphaZero, AlphaGo и AlphaGo Zero - три совершенно разных понятия.
Основной текст
Исследования в области компьютерных шахмат настолько же стары, насколько стара и сама компьютерная наука. Бэббидж, Тьюринг, Шеннон и вон-Нейман изобрели оборудование, алгоритмы и теорию для анализа и игры. Шахматы впоследствии стали супер-вызовом для целого поколения исследователей в области искусственного интеллекта. Их кульминацией стали компьютерные программы, которые показали себя на сверхчеловеческом уровне. Однако, эти системы очень сильно приспособлены под свою область и не могут быть использованы для других задач без серьезного вмешательства человека.
Уже давно настоящей амбицией в исследованиях было создание искусственного интеллекта, который сможет самообучиться, зная только базовые правила. Недавно AlphaGo Zero достигла сверхчеловеческого мастерства в го, получив все свои знания с помощью глубоких сверточных нейронных сетей, тренируясь исключительно играя против самой себя. Далее мы покажем эффективность похожего, но общего алгоритма (который мы называем AlphaZero) в играх в шахматы и сеги также хорошо как и в го без всяких дополнительных баз знаний, кроме правил этих игр. Это продемонстрирует, что в конечном счете самообучающиеся алгоритмы могут достичь сверхчеловеческой эффективности во многих областях.
Ориентир для искусственного интеллекта был поставлен в 1997 году, когда DeepBlue обыграла мирового чемпиона среди людей - Каспарова. За последние два десятилетия компьютерные программы оставили позади "человеческий" уровень игры. Эти программы вычисляют ходы, пользуясь экспертными оценками шахматных гроссмейстеров и определяют эффективность ходов с помощью альфа-бета поиска, который расширяет поисковое дерево, используя большое количество умных эвристик и предметно-ориентированных адаптаций. За эталон такой программы мы возьмем победителя чемпионата компьютерных движков 2016 года программу Stockfish (другие сильные программы, включая DeepBlue, имеют похожий принцип работы).
Сеги существенно более сложная игра, чем шахматы, если ее рассматривать с вычислительной точки зрения. Для нее нужна бОльшая доска, также любые фигуры, съеденные оппонентом, могут быть вновь выставлены в любом месте на доске. Сильнейшая программа для игры в сеги, Elmo, совсем недавно победила чемпиона мира среди людей. Программы для шахмат и сеги используют похожие алгоритмы, основанные на высоко-оптимизированном альфа-бета поиске в движке с множеством предметно-ориентированных адаптаций.
Го хорошо подходит для нейронных сетей, использованных в AlphaGo, потому что правила игры идеально ложатся на принципы нейронной сети (вычисление весов раздельных структур сверточных нейронных сетей). Более того действия в игре также просты (камень может быть положен в любое доступное место) и исходы игры ограничены бинарно (победа или поражение), что помогает тренировать нейронную сеть.
Шахматы и сеги, возможно, менее подходят для архитектуры нейронной сети, использующейся в AlphaGo. Правила завязаны на позицию (пешка может двигаться только вперед, рокировка различна на королевском и ферзевом фланге). Эти правила также включают длинные ходы (королева может за один ход попасть с одного конца доски на другой или поставить королю мат также находясь на другом конце доски от него). Пространство действий для шахмат включает все возможные ходы для всех фигур каждого игрока. Сеги в добавок позволяет возвращать съеденные фигуры обратно на доску. Шахматы и сеги в дополнение к победе и поражению могут закончиться ничьей. В самом деле, считается, что идеальная игра в шахматы обоими игроками приводит к ничьей.
Алгоритм AlphaZero - это более общая версия алгоритма AlphaGo Zero, которая впервые была представлена в контексте игры го. Алгоритм заменяет базу экспертных оценок, которые обычно используются в шахматных программах, на собственные знания, полученные самообучением с чистого листа.
Далее будет неинтересный кусок математических понятий, который к тому же получился корявым, т.к. пикабу не позволяет в тексте писать формулы. Эти несколько абзацев можно пропустить. В любом случае, любите математику, и может быть в будущем нейронная сеть вас пощадит.
Вместо внешней оценочной функции и эвристик ходов AlphaZero обращается к глубокой нейронной сети "(p, v) = fθ(s)" с параметром θ. Эта нейронная сеть принимает на входе позицию на доске s, а на выходе предоставляет вектор эффективностей ходов p с компонентами "pa = Pr(a|s)" для каждого действия a, и скалярную переменную v вычисляющую исход z из позиции s, "v ≈ E[z|s]". AlphaZero получает эти данные, из игр против самой себя, затем они используются для поиска.
Вместо альфа-бета поиска с предметно-ориентированными адаптациями AlphaZero использует для поиска дерево Монте-Карло. Каждый поиск состоит из серии симуляций игр, которые обходят дерево от корня к ветвям. Каждая симуляция выбирает для каждого состояния s ход a с наименьшим количеством посещений, наибольшей эффективностью и наибольшим значением, в соответствии с текущим fθ. Поиск возвращает вектор π, представляющий эффективности ходов.
Параметр θ получен с помощью самообучения, его начальное значение было выбрано случайно. Выбора ходов для каждого игрока происходил с помощью поиска в дереве Монте-Карло. В конце каждой игры конечная позиция sT оценивалась в соответствии с правилами исхода игры: -1 для проигрыша, 0 для ничьей и +1 для победы. Параметр θ обновлялся, чтобы минимизировать ошибку между предсказанным исходом vt и реальным исходом z, также параметр θ обновлялся для максимизации сходства вектора pt к полученным в результате поиска вероятностям πt. В частности, параметр θ отрегулирован градиентным спуском функции l, которая состоит из суммы квадрата отклонения ошибки и потери энтропии.
где c - параметр контролирующий уровень регуляризации весов L2. Обновленные параметры затем используются в последующих играх.
Алгоритм в AlphaZero здесь описан по-другому, чем оригинальный алгоритм в AlphaGo Zero. Отличие заключается в том, что AlphaZero вычисляет и оптимизирует ожидаемый исход, используя количество ничьих или другие потенциальные исходы.
Правила гo действуют одинаково, если рассматривать любой поворот игрового поля. Этот факт был задействован в AlphaGo и AlphaGo Zero разными путями. Во-первых, тренировочные данные были получены генерацией 8 симметрий для каждой позиции. Во-вторых, во время выполнения поиска Монте-Карло позиции на досках трансформируются с использованием случайного выбранного поворота или отзеркаливания перед передачей в нейронную сеть. Правила шахмат и сеги ассиметричны, и вообще здесь симметрии не могут быть приняты. AlphaZero не вычисляет тренировочные данные и не трансформирует доску во время поиска Монтер-Карло.
В AlphaGo Zero новые игры во время обучения получены от лучших игроков на всех предыдущих итерациях. После каждой тренировочной итерации эффективность нового игрока сравнивается с лучшим игроком. В случае 55% побед нового игрока он заменит лучшего, и все новые игры теперь будут созданы на его основе. AlphaZero поддерживает одну нейронную сеть, которая постоянно обновляется вместо ожидания завершения конца каждой итерации.
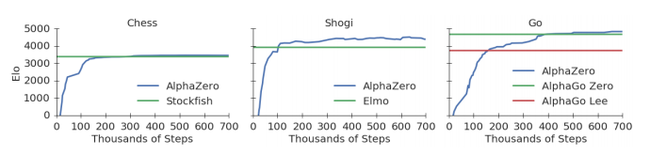
Рисунок 1. Тренировка AlphaZero в течение 700 тыс шагов. Эло рейтинг был вычислен с помощью игр между различными игроками, которым дали 1 секунду на ход. a) эффективность AlphaZero в шахматах в сравнении со Stockfish b) эффективность AlphaZero в сеги в сравнении с Elmo. c) Эффективность AlphaZero в го в сравнении с AlphaGo (игравшей против Ли) и AlphaGo Zero.
Игры против самой себя генерируются с использованием последних значений параметров нейронной сети, без оценочного шага и выбора лучшего игрока.
AlphaGo Zero настраивает гипер-параметр для поиска с помощью оптимизации Байеса. А в AlphaZero мы повторно используем один и тот же гипер-параметр для всех игр без подстройки под конкретную игру. Единственное исключение - это шум, который мы добавили, чтобы обеспечить разнообразие. Шум пропорционален типичному количеству возможных ходов для данного типа игры. Как и в AlphaGo Zero в AlphaZero состояние доски закодировано пространственными плоскостями, основанным только на базовых правилах данной игры. Действия закодированы аналогично пространственными плоскостями или плоским вектором, которые также основаны на базовых правилах игры.
Мы применили AlphaZero к шахматам, сеги и го. Программа имеет те же самые настройки, архитектуру нейронной сети и гипер-параметр для всех трех игр. Мы тренировали независимые экземпляры AlphaZero для каждой игры. Тренировка включила в себя 700 тыс шагов, которые начались со случайно выбранных параметров, использовали 5 тыс тензорных процессоров первого поколения (специальный процессор Google для нейронных сетей, имеет частоту около 700 МГц), чтобы сгенерировать игры и 64 тензорных процессора второго поколения, чтобы обучать нейронную сеть.
Рисунок 1 показывает эффективность AlphaZero в течении самообучения в виде функции тренировочных шагов по шкале Эло. В шахматах AlphaZero превзошел Stockfish после 4 часов обучения (300 тыс шагов), в сеги AlphaZero превзошел Elmo после двух часов самообучения (110 тыс шагов), и в го AlphaZero превзошел AlphaGo (который играл с Ли) после 8 часов (165 тыс шагов). Мы запустили полностью обученную AlphaZero против Stockfish, Elmo и предыдущей версии AlphaGo Zero (тренировавшейся в течение трех дней) в шахматы, сеги и го соответственно. Они сыграли по 100 игр с контролем времени 1 минута на ход. AlphaZero и предыдущая AlphaGo Zero использовали отдельные машины с 4 тензорными процессорами. Stockfish и Elmo играли на максимальных настройках эффективности, используя 64 потока и 1 Гб памяти. AlphaZero убедительно победила всех оппонентов, проиграв 0 игр Stockfish'у, 8 игр Elmo и также победила предыдущую версию AlphaGo Zero.
Таблица 1. Результаты партий, про которые говорилось выше.
Мы также проанализировали отношение эффективности поиска Монте-Карло в AlphaZero к эффективности альфа-бета поиска в Stockfish и Elmo. AlphaZero компенсирует маленькое количество выборок за счет использования нейронной сети, которая позволяет сосредоточиться только на долгосрочных многообещающих ходах, что соответствует мышлению человека. Рисунок 2 показывает связь между временем, затраченным на ход и его эффективностью, и показывает их отношение к эффективности Stockfish и Elmo, которым давалось 40 миллисекунд на ход. Поиск Монте-Карло в AlphaZero показал большую эффективность с увеличением времени в сравнении со Stockfish и Elmo, отвечая на вопрос о существенном превосходстве альфа-бета поиска в этих областях.
В конце мы проанализировали шахматные знания, накопленные AlphaZero. Таблица 2 показывает анализ наиболее популярных шахматных дебютов. Каждый из этих дебютов был независимо открыт AlphaZero и сыгран много раз в процессе обучения. Если запустить партию с любого популярного дебюта AlphaZero убедительно обыгрывает Stockfish, показывая, что AlphaZero заточена не под конкретную партию, а подобна шахматному мастеру, который будет эффективно играть в любой позиции на доске.
Игра в шахматы представлялась как вершина искусственного интеллекта последних 20 лет. Уровень развития программ зависел от мощности движков, которые перебирали много миллионов позиций на доске, используя внешние экспертные оценки. AlphaZero использует общий алгоритм самообучения, который сначала был изобретен для игры в го, что позволяет ей достичь превосходных результатов за несколько часов, исследуя в тысячи раз меньше позиций, без дополнительных знаний, кроме правил игры.
Таблица 2. Частота сыгранных дебютов. Если коротко: AlphaZero сама начала играть те дебюты, на выработку которых у людей ушли столетия.
Рисунок 2. Зависимость эффективности от времени выраженная по шкале Эло. а) эффективность AlphaZero и Stockfish в шахматы b) Эффективность AlphaZero и Elmo в сеги.
На этом основной текст статьи заканчивается.
От себя
Кароче, что нам надо знать, кроме то что с AlphaZero шутки плохи? Для начала надо оценить ее эффективность. Мы начнем издалека. Сила шахматистов оценивается в Эло. Вот список классов шахматистов и их Эло:
ниже 1000 — новичок
1000—1400 — четвёртый разряд (средний любитель);
1400—1600 — третий разряд;
1600—1800 — второй разряд;
1800—2000 — первый разряд;
2000—2200 — кандидат в мастера;
2200—2400 — национальный мастер;
2400—2500 — международный мастер;
2500—2800 — международный гроссмейстер;
свыше 2600 — претендент на участие в турнирах на звание чемпиона мира среди мужчин
свыше 2700 — претендент на матч за звание чемпиона мира по шахматам
Как видно, средний шаг между классами составляет 200 пунктов. Что же они дают? Насколько человек обладающий рейтингом 2000 сильнее того, кто обладает рейтингом 1800? Если взять двоих этих людей и посадить играть друг с другом, то более сильный игрок будет побеждать в 3 играх из 4. Разница в 400 пунктов означает, что сильнейший игрок будет побеждать в 9 играх из 10. Разница в 600 пунктов означает, что сильнейший игрок будет побеждать в 97 играх из 100. Т.е. если взять человека с третьим разрядом, то он редко, но все же будет выигрывать у первого разряда, а вот выиграть хотя бы одну партию у кандидата в мастера для него уже становится едва возможным.
Какой же рейтинг Эло имеют сильнейшие современные шахматисты? Посмотрим на топ игроков на декабрь 2017 в классические шахматы:
1. Магнус Карлсен 2837
2. Левон Аронян 2805
3. Шахрияр Мамедьяров 2799
Количество игроков, имеющих заданный рейтинг (не самые последние данные):
2400—2499 2034
2500—2599 701
2600—2699 192
2700—2799 43
≥ 2800 5
Как бы там не было, 2837 - это на данный момент вершина человечества в классических шахматах, которую представляет Магнус Карлсен, бесспорный чемпион, славящийся неординарной игрой. Так что же там с силой компьютерных программ? Как известно, они уже давно обыгрывают людей. Упомянутый в статье Stockfish имеет оценочный рейтинг Эло равный 3228. Насколько это хорошо? Это скорее плохо, потому что нетрудно посчитать, что сильнейший шахматист планеты из 100 партий против Stockfish сможет выиграть только 3. Вот так мы отстали от программ.
Теперь мы можем посчитать примерный рейтинг Эло для AlphaZero. Для подсчета нам нужно посчитать количество очков, которые AlphaZero заработала за 100 партий, это 64. Теперь смотрим в таблицу (по крайней мере, я смотрю) и видим, что 0.64 очка за партию это +100 пунктов Эло. Соответственно, AlphaZero имеет рейтинг около 3328. На самом деле - это не очень много. Нельзя сказать, что разрыв между AlphaZero и Stockfish составляет класс (т.е. 200 пунктов), но первая программа явно играет более эффективно.
Однако следует сделать оговорку: обычно такие программы как Stockfish первые 10-20 ходов играют согласно базе партий, т.е. они смотрят какие ходы делали великие шахматисты в имеющейся позиции, если соответствий не найдено, то тогда начинается перебор ходов. Так вот, в испытаниях Stockfish играл на "чистом интеллекте", т.е. ему отключили возможность пользоваться базой партий, что конечно же значительно его ослабило. Не трудно догадаться, что если разработчики пошли на такой трюк, то это значит, что в настоящий момент AlphaZero пока не в состоянии победить Stockfish в честном поединке, когда Stockfish использует всю свою мощь. С другой стороны большое уважение вызывает то, что AlphaZero сама открыла популярные дебюты. Из комментариев гроссмейстера "Два профессиональных шахматиста потратили несколько лет чтобы доработать староиндийскую защиту в шахматах. И то что они сделали считалось большим прорывом, который изменил стиль игры многих людей. AlphaZero же всего за несколько часов сама нашла то же самое решение". Так что можно считать, что это только начало - нейронные сети будут все чаще врываться в те сферы, где их не очень то и ждут и вытеснять человека традиционные подходы.
FAQ
1. Выходит разработчики всех обманули, т.к. они же сами сказали, что вся сила Stockfish'а и подобных программ в базе оценок профессиональных шахматистов, а сами ее отключили?
Все не так. База оценок профессиональных шахматистов используются, чтобы оценить позицию на доске по шкале от -1 до +1, где -1 безоговорочная победа черных, а +1 безоговорочная победа белых, ее никто не отключал. База, которую отключили разработчики AlphaZero у Stockfish - это база популярных ходов в конкретных ситуациях. Что на самом деле сравнивали - это "тупой перебор ходов" против "умного перебора ходов", о которых можно узнать ниже.
2. Я пытался разобраться в тексте и так понял, что в основе AlphaZero все равно лежит перебор ходов?
Именно так, но классические программы перебирают практически все подряд, а AlphaZero выбирает только между самыми эффективными ходами (грубо говоря, перебор 10 млн тупых ходов против перебора 70 тыс умных).
3. Все было нечестно - AlphaZero имела более мощное оборудование.
Не совсем так. AlphaZero имела мощное оборудование во время обучения, а во время проверочных игр были использованы всего 4 тензорных процессора (предположительно по 700 МГц каждый).