

О чём пишут на Пикабу?
Написал небольшую программку для анализа частоты встречаемости слов в тексте (понадобилось для одного псевдо-эксперимента) и решил, кроме прочего, испытать её на текстах из Пикабу.
Открыл поиск по тегу "текст", выставил рейтинг не меньше 500 (потому что неинтересные тексты, решил я, не отражают настроений трудящихся масс; подсчёт слов нужно проводить в текстах, которые понравились пикабушникам).
Сходу заметил одну занятную особенность: частоты употребления топовых слов сразу установились на определённых значениях и далее почти не менялись от текста к тексту:
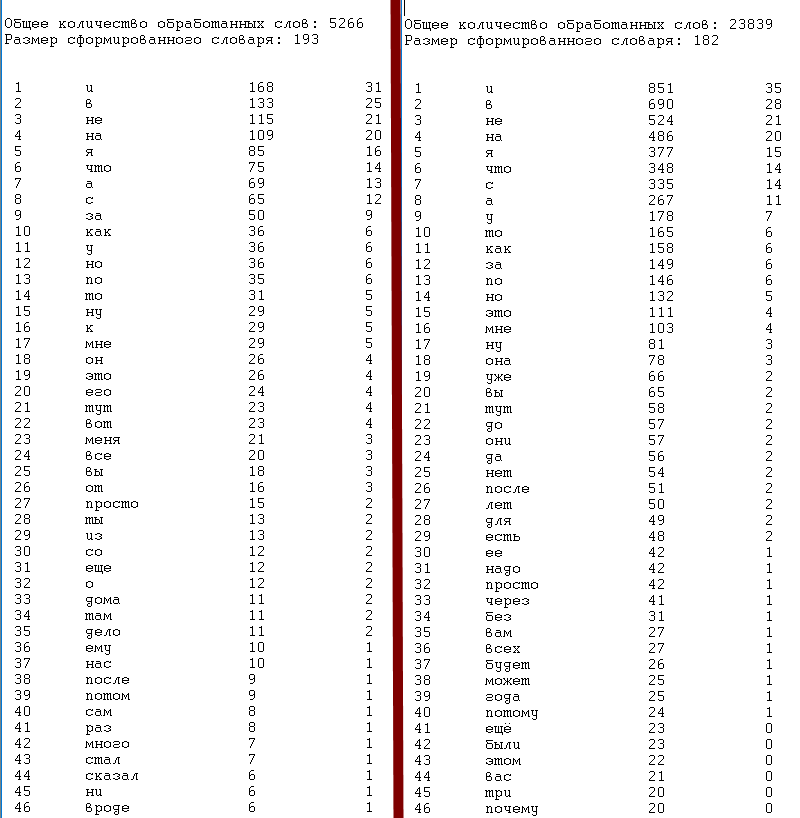
На скриншоте слева -- результат обработки массива из пяти тысяч слов. Справа -- из 23 тысяч. Несмотря на более чем четырёхкратное увеличение количества слов (и соответствующее увеличение разнообразия текстов) общий словарь почти не поменялся.
Почти не меняется и частота употребления слов (крайний правый столбец -- частота на 1000 слов). Ещё одно открытие: с увеличением размера обработанного текста первые 8 слов медленно отрываются вперёд по частоте употребления.
Вы спросите меня, зачем я всё это сделал?
Дык, рейтинга-то дохера, можно и потратить чуток.
Первое правило работы с текстом: "исключи шумовые слова!"
Какую информацию несёт то, что наиболее часто употребляемые в русском языке предлоги на первом месте?! Никакой!
Должен быть составлен словарь шумовых слов (его можно нагуглить) и в предобработке шумовые слова нужно исключить.
Затем, неплохо было бы прикрутить стеммер, например стеммер Портера или снежок snowball. Этим вы исключите разницу между словом "долбоёб" и "долбоёбы", которые суть одно и то же.
Автору долго курить обработку и поиск текста!
Хм, если соединить их воедино получится типичная ахуительная история из лучшего.
Закон Ципфа. Гугл ит.